Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Introduction to High-Level System Design
System Design Fundamentals
- Functional vs. Non-Functional Requirements
- Scalability, Availability, and Reliability
- Latency and Throughput Considerations
- Load Balancing Strategies
Architectural Patterns
- Monolithic vs. Microservices Architecture
- Layered Architecture
- Event-Driven Architecture
- Serverless Architecture
- Model-View-Controller (MVC) Pattern
- CQRS (Command Query Responsibility Segregation)
Scaling Strategies
- Vertical Scaling vs. Horizontal Scaling
- Sharding and Partitioning
- Data Replication and Consistency Models
- Load Balancing Strategies
- CDN and Edge Computing
Database Design in HLD
- SQL vs. NoSQL Databases
- CAP Theorem and its Impact on System Design
- Database Indexing and Query Optimization
- Database Sharding and Partitioning
- Replication Strategies
API Design and Communication
Caching Strategies
- Types of Caching
- Cache Invalidation Strategies
- Redis vs. Memcached
- Cache-Aside, Write-Through, and Write-Behind Strategies
Message Queues and Event-Driven Systems
- Kafka vs. RabbitMQ vs. SQS
- Pub-Sub vs. Point-to-Point Messaging
- Handling Asynchronous Workloads
- Eventual Consistency in Distributed Systems
Security in System Design
Observability and Monitoring
- Logging Strategies (ELK Stack, Prometheus, Grafana)
- API Security Best Practices
- Secure Data Storage and Access Control
- DDoS Protection and Rate Limiting
Real-World System Design Case Studies
- Distributed locking (Locking and its Types)
- Memory leaks and Out of memory issues
- HLD of YouTube
- HLD of WhatsApp
System Design Interview Questions
- Adobe System Design Interview Questions
- Top Atlassian System Design Interview Questions
- Top Amazon System Design Interview Questions
- Top Microsoft System Design Interview Questions
- Top Meta (Facebook) System Design Interview Questions
- Top Netflix System Design Interview Questions
- Top Uber System Design Interview Questions
- Top Google System Design Interview Questions
- Top Apple System Design Interview Questions
- Top Airbnb System Design Interview Questions
- Top 10 System Design Interview Questions
- Mobile App System Design Interview Questions
- Top 20 Stripe System Design Interview Questions
- Top Shopify System Design Interview Questions
- Top 20 System Design Interview Questions
- Top Advanced System Design Questions
- Most-Frequented System Design Questions in Big Tech Interviews
- What Interviewers Look for in System Design Questions
- Critical System Design Questions to Crack Any Tech Interview
- Top 20 API Design Questions for System Design Interviews
- Top 10 Steps to Create a System Design Portfolio for Developers
Understanding Hash Tables: Implementation and Collision Resolution Techniques
If you’re diving into data structures, hash tables are a must-know topic for efficient data storage and retrieval. Whether you’re preparing for technical interviews or building scalable systems, understanding how hash tables work is essential. For free resources and course updates, sign up here.
Also Read: Atlassian DSA: Qs & Solutions
What Is a Hash Table?
A hash table is a data structure that stores key-value pairs, allowing lightning-fast lookups, insertions, and deletions. It works by converting keys into unique indexes using a hash function, which maps data to specific slots in an underlying array.
Hash tables power databases, caches, and even programming language internals. For instance, Python dictionaries and Java HashMaps rely on hash tables. Their average time complexity for operations is O(1), making them ideal for high-performance applications.
Also Read: Uber DSA: Qs & Solutions
Structure of a Hash Table
Hash Functions
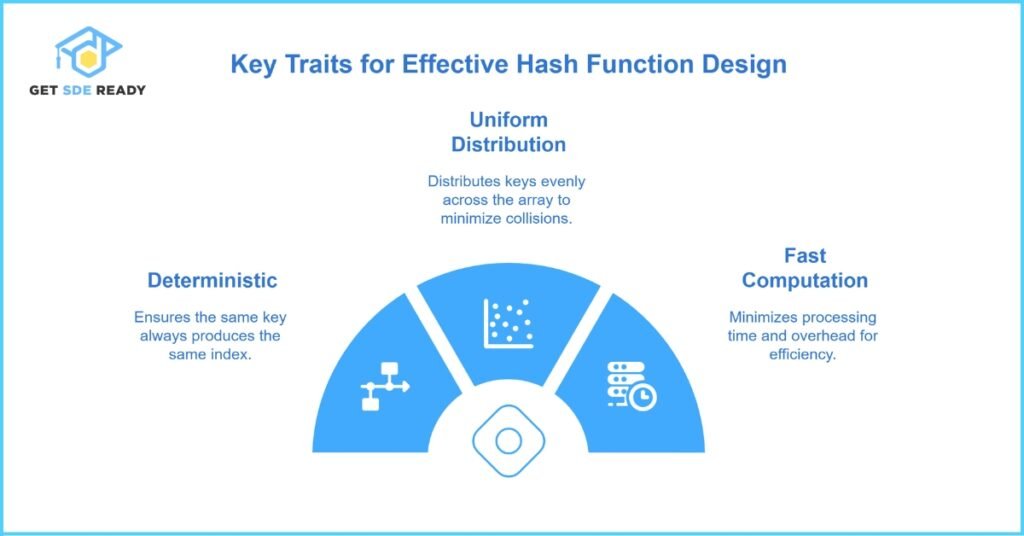
A hash function converts a key into an integer index within the array. A good hash function has three traits:
- Deterministic: Same key → same index every time.
- Uniform Distribution: Keys spread evenly across the array.
- Fast Computation: Minimal overhead.
Popular hash functions include MD5, SHA-1, and CRC32.
Key Components of Hash Functions
- Preprocessing: Handling non-integer keys (e.g., converting strings to ASCII).
- Compression: Ensuring the output fits the array size (e.g., modulo operation).
Table 1: Common Hash Functions
Function | Use Case | Collision Rate |
MD5 | Checksums | Moderate |
SHA-256 | Cryptography | Low |
MurmurHash | Databases | Very Low |
Arrays and Buckets
The array holds the actual data, while each slot (or bucket) can store multiple entries. For example, a hash table with 10 slots might index keys 0-9.
Also Read: Google DSA: Qs & Prep
Collision Resolution Techniques
What Are Collisions?
Collisions occur when two keys hash to the same index. For example, “apple” and “orange” might both map to index 3.
Separate Chaining
This method uses linked lists to handle collisions. Each bucket points to a list of entries sharing the same index.
Pros:
- Simple to implement.
- Handles unlimited collisions.
Cons:
- Overhead from pointers in linked lists.
Open Addressing
All entries are stored in the array itself. If a collision occurs, the algorithm probes for the next available slot.
Linear Probing
Searches for the next empty slot linearly (e.g., index+1, index+2).
Quadratic Probing
Uses a quadratic function (e.g., index + 1², index + 2²) to reduce clustering.
Double Hashing
Applies a second hash function to calculate the probe interval.
Table 2: Collision Methods Comparison
Method | Speed | Memory Use | Use Case |
Separate Chaining | Medium | High | High-collision data |
Linear Probing | Fast | Low | Small datasets |
Double Hashing | Slow | Low | Large datasets |
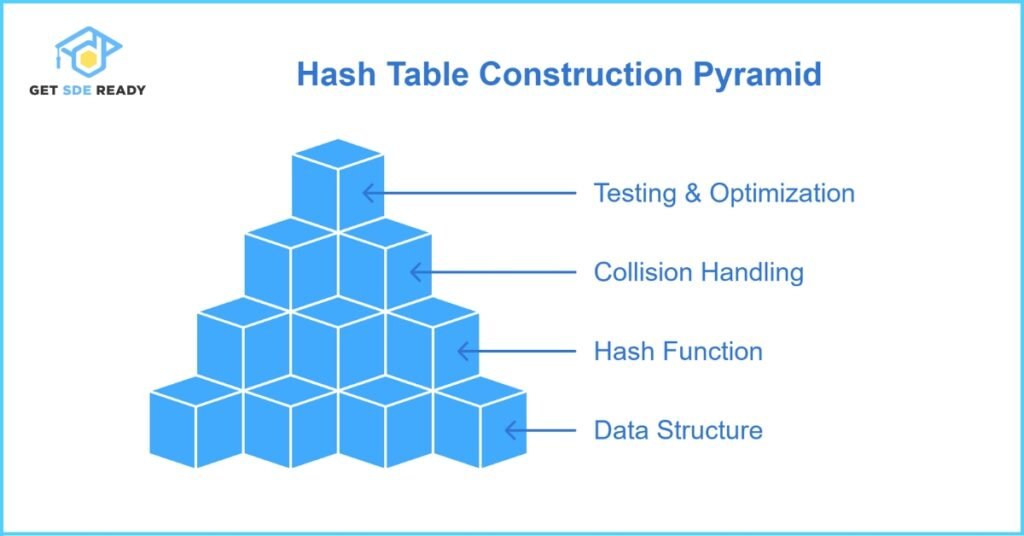
Step-by-Step Hash Table Implementation
1. Choose a Data Structure
Use an array of linked lists (for chaining) or a dynamic array (for open addressing).
2. Define the Hash Function
For strings, convert characters to ASCII and apply modulo:
def hash_function(key, size):
return sum(ord(char) for char in key) % size
3. Handle Collisions
Implement chaining or probing based on your use case.
4. Test and Optimize
Check performance under high load and adjust the hash function or table size.
Advanced Topics in Hash Tables
Dynamic Resizing
When the load factor (entries/slots) exceeds 0.7, resize the array to maintain efficiency. For example, double the size and rehash all keys.
Real-World Applications
- Databases: Indexing records for quick access.
- Caching Systems: Storing web pages (e.g., Redis).
- Compilers: Symbol tables for variables.
Recommended Topic: Amazon DSA: Interview Qs & Prep
Best Practices for Hash Table Usage
Choosing the Right Hash Function
Use SHA-256 for security-critical apps or MurmurHash for speed.
Managing Load Factor
Keep load factor ≤ 0.7 to minimize collisions. Studies show a 0.75 load factor increases lookup time by 30%.
Testing Collision Handling
Simulate worst-case scenarios (e.g., all keys collide) to validate your resolution strategy.

How do hash tables achieve O(1) time complexity?
Hash tables use a hash function to directly compute the storage location, avoiding iterative searches. However, collisions can degrade performance. For a deep dive, explore our Data Structures & Algorithms Course.
What’s the difference between separate chaining and open addressing?
Separate chaining uses linked lists to store collisions, while open addressing finds new slots within the array. The latter is memory-efficient but prone to clustering. Learn implementation details in our Web Development Course.
Why is dynamic resizing important?
Why is dynamic resizing important?
Resizing keeps the load factor low, ensuring fast operations. Without it, hash tables slow down as they fill up. Master these concepts in our System Design Course.


DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00
Accelerate your Path to a Product based Career
Boost your career or get hired at top product-based companies by joining our expertly crafted courses. Gain practical skills and real-world knowledge to help you succeed.

Mastering GenAI / LLM Engineering
- 100+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 50% OFF
₹39,999.00 ₹19,999.00

Mastering Data Structures & Algorithms
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests
- Access to Global Peer Community
- Topic-wise Quizzes
- Interview Prep Material
Buy for 40% OFF
₹9,999.00 ₹5,999.00

Data Analytics
- 20+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 15+ Hands-on Live Projects
- Comprehensive Notes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 70% OFF
₹9,999.00 ₹2,999.00

SDE 360: Master DSA, System Design, AI & Behavioural
- 100+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 50% OFF
₹39,999.00 ₹19,999.00

Fast-Track to Full Spectrum Software Engineering
- 120+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- 12+ live Projects & Deployments
- Case Studies
- Access to Global Peer Community
Buy for 51% OFF
₹35,000.00 ₹16,999.00
DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00
Reach Out Now
If you have any queries, please fill out this form. We will surely reach out to you.
Contact Email
Reach us at the following email address.
arun@getsdeready.com
Phone Number
You can reach us by phone as well.
+91-97737 28034
Our Location
Rohini, Sector-3, Delhi-110085
