Schema Design, Normalization & Denormalization
Before writing complex SQL queries or building dashboards, it’s essential to understand how databases are structured. A well-designed schema helps ensure data is organized, accurate, scalable, and easy to query. This topic focuses on how to design database schemas using the concepts of normalization and denormalization.
What Is Schema Design?
A database schema is the blueprint of how data is structured in a relational database. It defines:
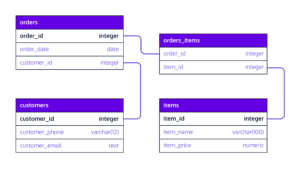
- The tables and their relationships
- The columns and their data types
- The primary keys and foreign keys
Your goal as a data analyst or engineer is to design schemas that:
- Avoid data duplication
- Maintain data consistency
- Make querying efficient
There are two main types of schema structures:
- Star schema (used in reporting/data warehouses)
- Normalized schema (used in transactional databases)
What Is Normalization?
Normalization is the process of organizing data to reduce redundancy (duplicate data) and improve data integrity. It involves splitting large tables into smaller ones and linking them using relationships (foreign keys).
Why Normalize?
- Avoids data duplication
- Reduces data anomalies during insert, update, delete
- Ensures consistency and structure
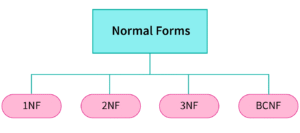
Common Normal Forms:
- 1NF (First Normal Form): No repeating groups or arrays in a row
- 2NF (Second Normal Form): No partial dependency on a composite key
- 3NF (Third Normal Form): No transitive dependencies between non-key columns
- BCNF (Boyce-Codd Normal Form): Stronger version of 3NF ensuring all determinants are candidate keys
Example:
If a single table stores employee details and department info, it’s better to split that into two tables:Employees(emp_id, name, dept_id) and Departments(dept_id, dept_name)
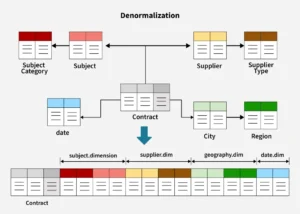
What Is Denormalization?
Denormalization is the reverse process—combining tables to reduce joins and improve read performance. It’s often used in analytics and reporting databases, where speed is more important than storage efficiency.
Why Denormalize?
- Improves query performance
- Reduces the number of joins
- Helpful in read-heavy systems like dashboards or reports
Example:
Instead of joining three tables to get sales data, you might store everything in one pre-computed summary table:sales_summary(customer_name, product_name, total_sales, region)
When to Use Normalization vs. Denormalization
| Scenario | Use Normalization | Use Denormalization |
|---|---|---|
| Transactional systems (e.g., banking) | Yes | Rarely |
| Analytics or reporting systems | Sometimes (for staging) | Yes (for fast reads) |
| Reducing data duplication | Yes | No |
| Improving read speed | No (can slow down reads) | Yes |
