Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Introduction to High-Level System Design
System Design Fundamentals
- Functional vs. Non-Functional Requirements
- Scalability, Availability, and Reliability
- Latency and Throughput Considerations
- Load Balancing Strategies
Architectural Patterns
- Monolithic vs. Microservices Architecture
- Layered Architecture
- Event-Driven Architecture
- Serverless Architecture
- Model-View-Controller (MVC) Pattern
- CQRS (Command Query Responsibility Segregation)
Scaling Strategies
- Vertical Scaling vs. Horizontal Scaling
- Sharding and Partitioning
- Data Replication and Consistency Models
- Load Balancing Strategies
- CDN and Edge Computing
Database Design in HLD
- SQL vs. NoSQL Databases
- CAP Theorem and its Impact on System Design
- Database Indexing and Query Optimization
- Database Sharding and Partitioning
- Replication Strategies
API Design and Communication
Caching Strategies
- Types of Caching
- Cache Invalidation Strategies
- Redis vs. Memcached
- Cache-Aside, Write-Through, and Write-Behind Strategies
Message Queues and Event-Driven Systems
- Kafka vs. RabbitMQ vs. SQS
- Pub-Sub vs. Point-to-Point Messaging
- Handling Asynchronous Workloads
- Eventual Consistency in Distributed Systems
Security in System Design
Observability and Monitoring
- Logging Strategies (ELK Stack, Prometheus, Grafana)
- API Security Best Practices
- Secure Data Storage and Access Control
- DDoS Protection and Rate Limiting
Real-World System Design Case Studies
- Distributed locking (Locking and its Types)
- Memory leaks and Out of memory issues
- HLD of YouTube
- HLD of WhatsApp
System Design Interview Questions
- Adobe System Design Interview Questions
- Top Atlassian System Design Interview Questions
- Top Amazon System Design Interview Questions
- Top Microsoft System Design Interview Questions
- Top Meta (Facebook) System Design Interview Questions
- Top Netflix System Design Interview Questions
- Top Uber System Design Interview Questions
- Top Google System Design Interview Questions
- Top Apple System Design Interview Questions
- Top Airbnb System Design Interview Questions
- Top 10 System Design Interview Questions
- Mobile App System Design Interview Questions
- Top 20 Stripe System Design Interview Questions
- Top Shopify System Design Interview Questions
- Top 20 System Design Interview Questions
- Top Advanced System Design Questions
- Most-Frequented System Design Questions in Big Tech Interviews
- What Interviewers Look for in System Design Questions
- Critical System Design Questions to Crack Any Tech Interview
- Top 20 API Design Questions for System Design Interviews
- Top 10 Steps to Create a System Design Portfolio for Developers
Trie Data Structure Trie Data Structure: Basics and Applications
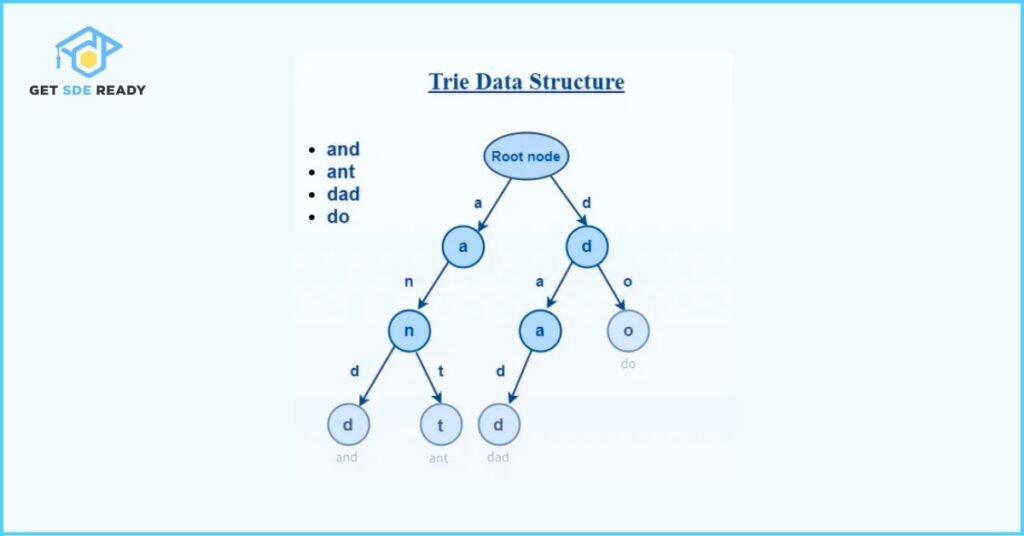
The Trie data structure, also known as a prefix tree, is a specialized tree-based structure designed for efficiently storing and retrieving strings from a dynamic dataset. It excels in scenarios involving large volumes of words or keys, making it a powerful tool for applications like autocomplete and spell checking.
Key Features and Operations
Trie enables fast operations such as insertion, search, deletion, and prefix matching, significantly reducing time complexity when compared to traditional search techniques. This makes it ideal for tasks where performance and accuracy in string handling are crucial.
In this article, we’ll dive into how Tries manage operations like inserting and searching keys, as well as performing efficient prefix-based lookups.
Representation of Trie Node
Structure of a Trie Node
A Trie node serves as a fundamental unit in the Trie data structure, connected to other nodes through edges.
Each node typically holds a character or a segment of a string, forming a hierarchical structure.
The root node of the Trie functions as the starting point and is unique in that it does not store any character. It merely acts as an anchor to initiate traversal through the tree.
class TrieNode {
public:
// pointer array for child nodes of each node
TrieNode* children[26];
// Used for indicating ending of string
bool isLeaf;
TrieNode() {
// initialize the wordEnd variable with false
// initialize every index of childNode array with NULL
isLeaf = false;
for (int i = 0; i < 26; i++) {
children[i] = nullptr;
}
}
};
public class TrieNode {
// Array for child nodes of each node
TrieNode[] children;
// Used for indicating the end of a string
boolean isEndOfWord;
// Constructor
public TrieNode() {
// Initialize the wordEnd
// variable with false
isEndOfWord = false;
// Initialize every index of
// the child array with null
// In Java, we do not have to
// explicitely assign null as
// the values are by default
// assigned as null
children = new TrieNode[26];
}
}
class TrieNode {
constructor() {
// Initialize the child Node
// array with 26 nulls
this.children = Array(26).fill(null);
// Initialize wordEnd to the false
// indicating that no word ends here yet
this.isEndOfWord = false;
}
}
class TrieNode:
def __init__(self):
self.children = [None] * 26
self.isEndOfWord = False
Output
If a valid color configuration is found, the output will display the assigned colors for each vertex:
Solution Exists: Following are the assigned colors
1 2 3 2
Applications of Graph Coloring
Graph coloring has a wide range of real-world applications, particularly in areas where resource allocation or conflict resolution is required. Common use cases include:
- Timetable Scheduling – Assigning time slots to avoid clashes in exams or classes.
- Sudoku Solver – Treating each cell as a vertex and ensuring numbers don’t repeat in rows, columns, or blocks.
- Register Allocation in Compilers – Optimizing the use of limited CPU registers during program execution.
- Map Coloring – Ensuring neighboring regions or countries are colored differently on a map.
- Mobile Radio Frequency Assignment – Assigning frequencies to avoid interference between adjacent towers.
FAQs

Insertion in Trie Data Structure – O(n) Time | O(n) Space
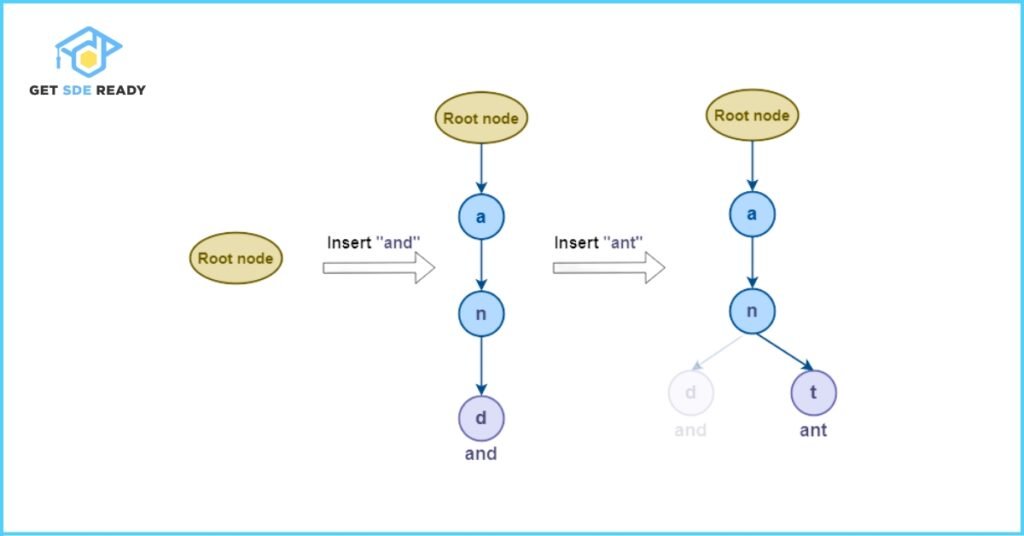
Example: Inserting the Word “and”
- Start at the root node:
The root node does not contain any character. Its wordEnd value is set to 0, indicating that no word ends at this point. - First character – “a”:
Calculate the index: ‘a’ – ‘a’ = 0.
Check if child[0] is null. Since it is, create a new TrieNode for the character “a” with wordEnd = 0 and an empty array of children. Move to this newly created node. - Second character – “n”:
Calculate the index: ‘n’ – ‘a’ = 13.
Check if child[13] is null. It is, so create a new TrieNode for “n” with wordEnd = 0. Move to this node. - Third character – “d”:
Calculate the index: ‘d’ – ‘a’ = 3.
Since child[3] is null, create a new TrieNode for “d” and set wordEnd = 1, marking the end of the word “and”.
Example: Inserting the Word “ant”
- Start at the root node:
The root node remains unchanged and keeps track of the starting characters of all inserted strings. - First character – “a”:
Index: ‘a’ – ‘a’ = 0.
A node for “a” already exists from the previous insertion. Move to this existing node. - Second character – “n”:
Index: ‘n’ – ‘a’ = 13.
The node for “n” is also present. Proceed to this node. - Third character – “t”:
Index: ‘t’ – ‘a’ = 19.
Since child[19] is null, create a new TrieNode for “t” and set wordEnd = 1, indicating that the word “ant” ends here.
// Method to insert a key into the Trie
void insert(TrieNode* root, const string& key) {
// Initialize the curr pointer with the root node
TrieNode* curr = root;
// Iterate across the length of the string
for (char c : key) {
// Check if the node exists for the
// current character in the Trie
if (curr->children[c - 'a'] == nullptr) {
// If node for current character does
// not exist then make a new node
TrieNode* newNode = new TrieNode();
// Keep the reference for the newly
// created node
curr->children[c - 'a'] = newNode;
}
// Move the curr pointer to the
// newly created node
curr = curr->children[c - 'a'];
}
// Mark the end of the word
curr->isLeaf = true;
}
// Method to insert a key into the Trie
static void insert(TrieNode root, String key) {
// Initialize the curr pointer with the root node
TrieNode curr = root;
// Iterate across the length of the string
for (char c : key.toCharArray()) {
// Check if the node exists for the
// current character in the Trie
if (curr.children[c - 'a'] == null) {
// If node for current character does
// not exist then make a new node
TrieNode newNode = new TrieNode();
// Keep the reference for the newly
// created node
curr.children[c - 'a'] = newNode;
}
// Move the curr pointer to the
// newly created node
curr = curr.children[c - 'a'];
}
// Mark the end of the word
curr.isEndOfWord = true;
}
// Method to insert a key into the Trie
function insert(root, key) {
// Initialize the curr pointer with the root node
let curr = root;
// Iterate across the length of the string
for (let c of key) {
// Check if the node exists for the
// current character in the Trie
let index = c.charCodeAt(0) - 'a'.charCodeAt(0);
if (curr.children[index] === null) {
// If node for current character does
// not exist then make a new node
let newNode = new TrieNode();
// Keep the reference for the newly
// created node
curr.children[index] = newNode;
}
// Move the curr pointer to the
// newly created node
curr = curr.children[index];
}
// Mark the end of the word
curr.isEndOfWord = true;
}
Time and Space Complexity of Insertion
- Time Complexity:
O(n) — where n is the length of the word being inserted. This is because each character of the word is processed exactly once during insertion. - Auxiliary Space:
O(n) — in the worst-case scenario, a new node is created for each character if none of the characters are already present in the Trie.
Searching in Trie Data Structure
Time Complexity: O(n)
Auxiliary Space: O(1)
Searching in a Trie is similar to the insertion operation but without creating new nodes. The algorithm simply navigates through existing paths by comparing each character of the input string.
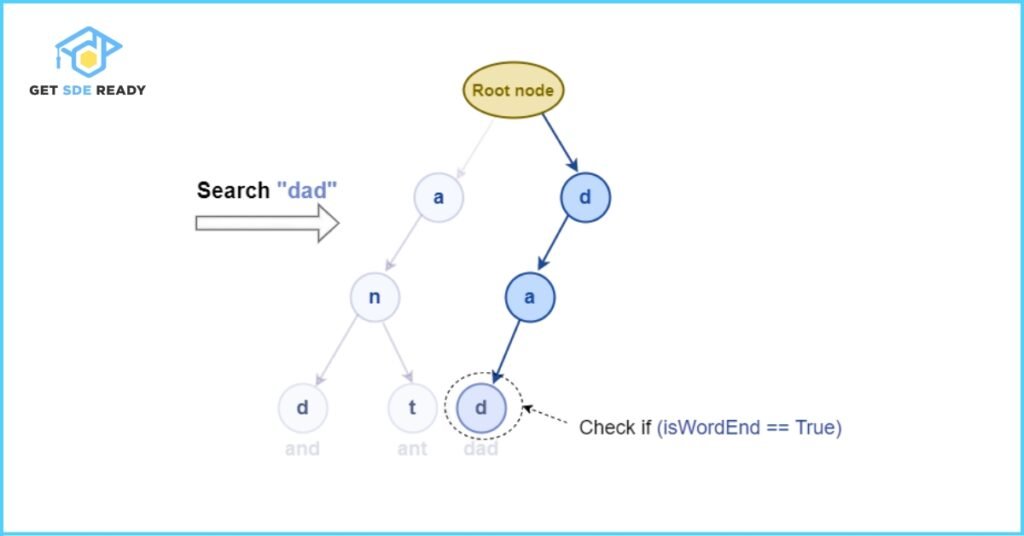
The search process may terminate in two cases:
- When the end of the string is reached.
- When a required character node is not found in the Trie.
Example: Searching for the Word “dad”
Assume the Trie already contains the words: “and”, “ant”, and “dad”. Now, let’s walk through the steps to search for the word “dad”:
- Start at the root node.
- Check for the character ‘d’: Navigate to the corresponding child node.
- Next, check for the character ‘a’: Move to the child node linked to ‘a’.
- Then, check for the character ‘d’ again: Move to the final character’s node.
- Verify the wordEnd flag: If it is set to 1, this confirms that the word “dad” exists in the Trie.
If all characters are found and the final node marks the end of a word, the search is successful.
# Method to insert a key into the Trie
def insert(root, key):
# Initialize the curr pointer with the root node
curr = root
# Iterate across the length of the string
for c in key:
# Check if the node exists for the
# current character in the Trie
index = ord(c) - ord('a')
if curr.children[index] is None:
# If node for current character does
# not exist then make a new node
new_node = TrieNode()
# Keep the reference for the newly
# created node
curr.children[index] = new_node
# Move the curr pointer to the
# newly created node
curr = curr.children[index]
# Mark the end of the word
curr.isEndOfWord = True
Output
If a valid color configuration is found, the output will display the assigned colors for each vertex:
Solution Exists: Following are the assigned colors
1 2 3 2
Applications of Graph Coloring
Graph coloring has a wide range of real-world applications, particularly in areas where resource allocation or conflict resolution is required. Common use cases include:
- Timetable Scheduling – Assigning time slots to avoid clashes in exams or classes.
- Sudoku Solver – Treating each cell as a vertex and ensuring numbers don’t repeat in rows, columns, or blocks.
- Register Allocation in Compilers – Optimizing the use of limited CPU registers during program execution.
- Map Coloring – Ensuring neighboring regions or countries are colored differently on a map.
- Mobile Radio Frequency Assignment – Assigning frequencies to avoid interference between adjacent towers.
FAQs
What is graph coloring?
Graph coloring is the process of assigning colors to each vertex of a graph such that no two adjacent vertices have the same color.
What is the chromatic number of a graph?
The chromatic number is the smallest number of colors needed to color a graph without any two connected vertices sharing the same color.
Why is graph coloring considered NP-complete?
Because there’s no known efficient algorithm that solves all instances of the problem in polynomial time. Finding an optimal coloring is computationally hard.
What is the difference between the decision and optimization versions of graph coloring?
The decision version asks whether a graph can be colored with M colors. The optimization version tries to find the minimum number of colors required to color the graph.

DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00
Accelerate your Path to a Product based Career
Boost your career or get hired at top product-based companies by joining our expertly crafted courses. Gain practical skills and real-world knowledge to help you succeed.

Data Analytics
- 20+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 15+ Hands-on Live Projects
- Comprehensive Notes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 70% OFF
₹9,999.00 ₹2,999.00

SDE 360: Master DSA, System Design, AI & Behavioural
- 100+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 50% OFF
₹39,999.00 ₹19,999.00

Fast-Track to Full Spectrum Software Engineering
- 120+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- 12+ live Projects & Deployments
- Case Studies
- Access to Global Peer Community
Buy for 51% OFF
₹35,000.00 ₹16,999.00
DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00

Mastering Mern Stack (WEB DEVELOPMENT)
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 12+ Hands-on Live Projects & Deployments
- Comprehensive Notes & Quizzes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 53% OFF
₹15,000.00 ₹6,999.00

Mastering Data Structures & Algorithms
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests
- Access to Global Peer Community
- Topic-wise Quizzes
- Interview Prep Material
Buy for 40% OFF
₹9,999.00 ₹5,999.00
Reach Out Now
If you have any queries, please fill out this form. We will surely reach out to you.
Contact Email
Reach us at the following email address.
arun@getsdeready.com
Phone Number
You can reach us by phone as well.
+91-97737 28034
Our Location
Rohini, Sector-3, Delhi-110085
