Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
MongoDB Aggregation Pipeline Simplified with Examples
The MongoDB Aggregation Pipeline is a robust framework for processing and transforming data within a MongoDB database. It allows developers to perform complex operations like filtering, sorting, grouping, and reshaping documents directly in the database, reducing the need for additional application logic. This guide will walk you through the pipeline’s core concepts, stages, use cases, and best practices, complete with practical examples to help you master this essential tool. Whether you’re a beginner or an experienced developer, this tutorial will provide clear, actionable insights to enhance your MongoDB skills.
Want to master MongoDB and other essential tech skills? Sign up for our free courses and get the latest updates on data science, web development, and more!
Introduction to MongoDB Aggregation Pipeline
The MongoDB Aggregation Pipeline is a framework designed to process multiple documents and produce computed results, making it ideal for tasks like data analysis, reporting, and transformation. Unlike traditional SQL databases that rely on JOINs and GROUP BY clauses, MongoDB’s pipeline offers a flexible, stage-based approach to handle complex queries in a NoSQL environment.
Each stage in the pipeline performs a specific operation on the input documents and passes the results to the next stage. This sequential processing model is similar to a data processing assembly line, where each step refines the data further. The pipeline is executed using the db.collection.aggregate() method and does not modify the original collection unless specific stages like $out or $merge are used.
Why Use the Aggregation Pipeline?
The aggregation pipeline stands out for several reasons:

- Performance: It processes data efficiently within the database, leveraging MongoDB’s optimization capabilities.
- Flexibility: Supports a wide range of operations, from simple filtering to advanced computations.
- Readability: The stage-based structure makes queries modular and easier to understand.
- Modern Alternative: Since MongoDB 5.0, the pipeline has replaced the deprecated map-reduce framework, offering superior performance and usability.
For developers looking to deepen their understanding of data processing, exploring related topics like data structures and algorithms can enhance your ability to design efficient queries.
Understanding the Aggregation Pipeline Stages
The aggregation pipeline consists of multiple stages, each performing a distinct operation on the input documents. Below, we explore the most commonly used stages with practical examples based on a sample cities collection containing documents like:
{
name: "Tokyo",
country: "Japan",
continent: "Asia",
population: 37400000,
landmarks: ["Tokyo Tower", "Shibuya Crossing"]
}
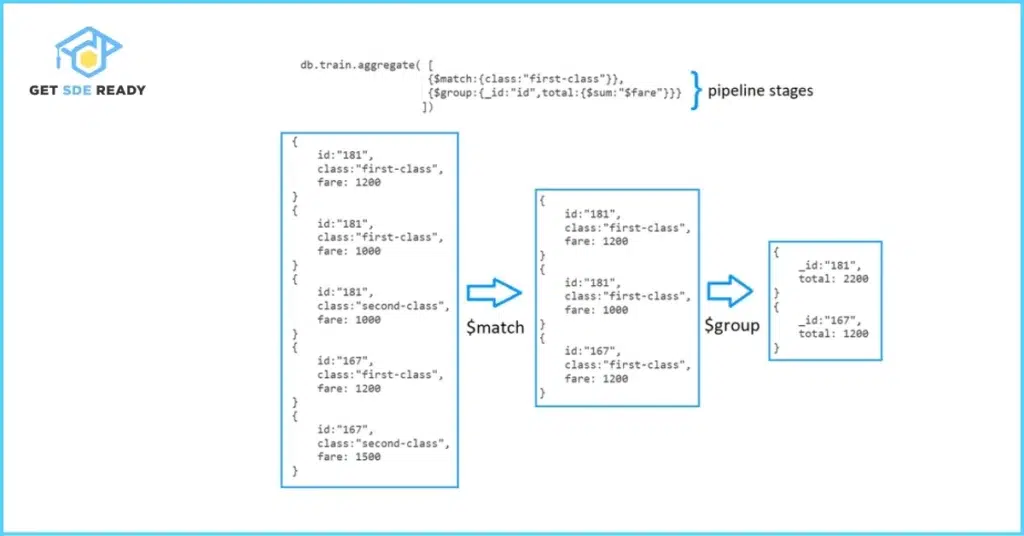
1. $match
The $match stage filters documents based on specified criteria, similar to the WHERE clause in SQL. It’s best used early in the pipeline to reduce the dataset size, improving performance.
Example: Filter cities in North America
db.cities.aggregate([
{
$match: {
continent: "North America"
}
}
])
Output: Returns documents for cities like New York and Mexico City.
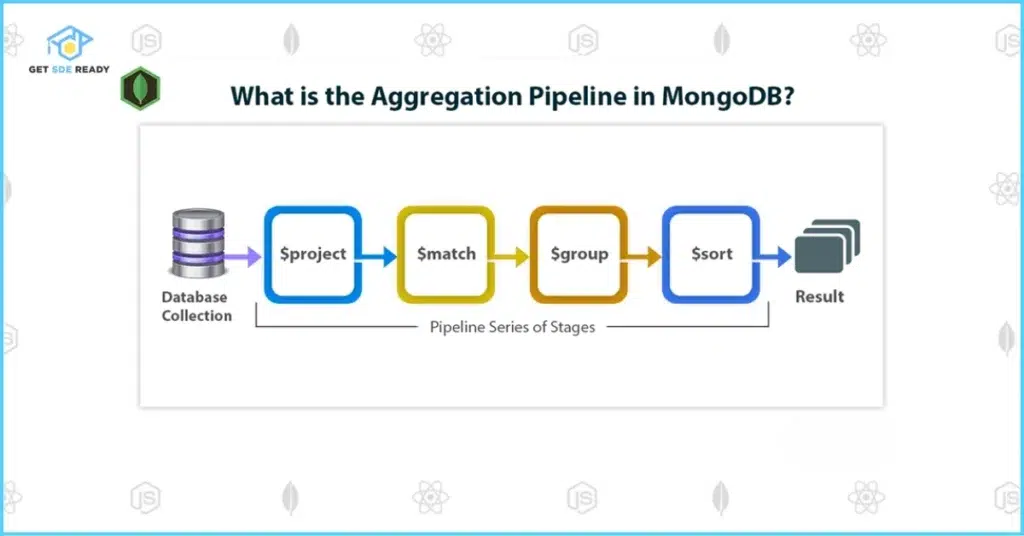
2. $sort
The $sort stage orders documents based on a specified field. Use 1 for ascending order and -1 for descending.
Example: Sort cities by population in descending order.
db.cities.aggregate([
{
$sort: {
population: -1
}
}
])
3. $group
The $group stage groups documents by a specified field and applies aggregation operations (e.g., $sum, $avg, $max) to each group.
Example: Calculate the total population per continent.
db.cities.aggregate([
{
$group: {
_id: "$continent",
totalPopulation: { $sum: "$population" }
}
}
])
Output:
{ "_id": "Asia", "totalPopulation": 150000000 }
{ "_id": "North America", "totalPopulation": 80000000 }
..
4. $project
The $project stage reshapes documents by including, excluding, or computing new fields.
Example: Create a new field combining city and country names.
db.cities.aggregate([
{
$project: {
cityCountry: { $concat: ["$name", ", ", "$country"] },
population: 1,
_id: 0
}
}
])
Output:
{ "cityCountry": "Tokyo, Japan", "population": 37400000 }
{ "cityCountry": "New York, USA", "population": 18800000 }
...
5. $limit and $skip
These stages are used for pagination. $limit restricts the number of output documents, while $skip skips a specified number of documents.
Example: Get the top 5 most populous cities.
db.cities.aggregate([
{
$sort: { population: -1 }
},
{
$limit: 5
}
])
Output: The top 5 cities by population, such as Tokyo, Delhi, Shanghai, São Paulo, and Mexico City.
6. $unwind
The $unwind stage deconstructs an array field, creating a new document for each array element.
Example: List each landmark separately.
db.cities.aggregate([
{
$unwind: "$landmarks"
}
])
Output:
{ "name": "Tokyo", "country": "Japan", "landmarks": "Tokyo Tower" }
{ "name": "Tokyo", "country": "Japan", "landmarks": "Shibuya Crossing" }
...
For a complete list of stages, refer to the MongoDB Aggregation Pipeline Documentation.
Common Use Cases of Aggregation Pipeline
The aggregation pipeline is versatile and supports various scenarios, making it a cornerstone for data-driven applications. Here are some practical use cases:
1. Data Analysis
The pipeline excels at performing complex calculations like averages, maximums, or counts.
Example: Calculate the average population per continent.
db.cities.aggregate([
{
$group: {
_id: "$continent",
averagePopulation: { $avg: "$population" }
}
}
])
Output:
{ "_id": "Asia", "averagePopulation": 30000000 }
{ "_id": "North America", "averagePopulation": 20000000 }
...
This is particularly useful for data science applications where aggregated insights drive decision-making

2. Reporting
Generate summarized reports for business intelligence or dashboards.
Example: Create a report of total population by continent, sorted by population.
db.cities.aggregate([
{
$group: {
_id: "$continent",
totalPopulation: { $sum: "$population" }
}
},
{
$sort: { totalPopulation: -1 }
}
])
Output
{ "_id": "Asia", "totalPopulation": 150000000 }
{ "_id": "North America", "totalPopulation": 80000000 }
...
3. Data Transformation
Reshape data for export or integration with other systems.
Example: Flatten a nested array structure.
db.cities.aggregate([
{
$unwind: "$landmarks"
},
{
$project: {
_id: 0,
city: "$name",
landmark: "$landmarks"
}
}
])
Output:
{ "city": "Tokyo", "landmark": "Tokyo Tower" }
{ "city": "Tokyo", "landmark": "Shibuya Crossing" }
...
This is valuable for web development projects requiring normalized data for APIs.
4. Real-time Analytics
Process streaming data for real-time insights, such as monitoring application logs.
Example: Count errors per minute in a logging system.
db.logs.aggregate([
{
$match: { level: "error" }
},
{
$group: {
_id: {
$dateTrunc: { date: "$timestamp", unit: "minute" }
},
count: { $sum: 1 }
}
},
{
$sort: { _id: 1 }
}
])
Output:
{ "_id": ISODate("2025-08-07T12:00:00Z"), "count": 10 }
{ "_id": ISODate("2025-08-07T12:01:00Z"), "count": 15 }
...
Best Practices for Using Aggregation Pipeline
To maximize the pipeline’s efficiency, follow these best practices:
- Optimize Stage Order: Place $match and $sort early to reduce the dataset size.
- Leverage Indexes: Create indexes on fields used in $match and $sort to boost performance.
- Minimize Computations: Include only necessary fields in $project to reduce processing overhead.
- Test Performance: Use the explain option in db.collection.aggregate() to analyze and optimize pipeline performance.
- Handle Large Datasets: For large datasets, consider sharding and ensure result sizes stay within MongoDB’s limits (see Aggregation Pipeline Limits).
Understanding system design principles can further help in scaling pipelines for large-scale applications.
Conclusion
The MongoDB Aggregation Pipeline is a game-changer for developers working with NoSQL databases. Its stage-based approach allows you to perform complex data processing tasks efficiently, from filtering and sorting to grouping and transforming data. By mastering the pipeline, you can streamline your application’s data handling, improve performance, and unlock powerful analytics capabilities.
To take your skills further, explore related topics like data structures and algorithms for query optimization, web development for integrating MongoDB with applications, or data science for advanced analytics. For a quick start, check out our crash course to accelerate your learning journey.
Practice is key—experiment with different pipeline stages and datasets to build confidence and expertise.
FAQs
What is the difference between the aggregation pipeline and map-reduce in MongoDB?
The aggregation pipeline processes data through sequential stages, offering better performance and flexibility than map-reduce, which relies on custom JavaScript functions. Map-reduce is deprecated since MongoDB 5.0.
How can I optimize the performance of my aggregation pipeline?
Place $match early, use indexes, minimize fields in $project, and test with explain. Sharding can help with large datasets.
Can I use the aggregation pipeline to update documents in MongoDB?
Yes, using $merge or $out stages to write results to a collection, but in-place updates require separate update operations
What are common mistakes to avoid when using the aggregation pipeline?
Avoid late $match stages, missing fields in $project, complex expressions, and neglecting indexes.
How does the aggregation pipeline handle large datasets?
It processes data in a streaming fashion and supports sharding for parallel processing, making it efficient for large datasets.

DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00
Accelerate your Path to a Product based Career
Boost your career or get hired at top product-based companies by joining our expertly crafted courses. Gain practical skills and real-world knowledge to help you succeed.

Mastering GenAI / LLM Engineering
- 100+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 50% OFF
₹39,999.00 ₹19,999.00

Mastering Data Structures & Algorithms
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests
- Access to Global Peer Community
- Topic-wise Quizzes
- Interview Prep Material
Buy for 40% OFF
₹9,999.00 ₹5,999.00

Data Analytics
- 20+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 15+ Hands-on Live Projects
- Comprehensive Notes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 70% OFF
₹9,999.00 ₹2,999.00

SDE 360: Master DSA, System Design, AI & Behavioural
- 100+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 50% OFF
₹39,999.00 ₹19,999.00

Fast-Track to Full Spectrum Software Engineering
- 120+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- 12+ live Projects & Deployments
- Case Studies
- Access to Global Peer Community
Buy for 51% OFF
₹35,000.00 ₹16,999.00
DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00
Reach Out Now
If you have any queries, please fill out this form. We will surely reach out to you.
Contact Email
Reach us at the following email address.
arun@getsdeready.com
Phone Number
You can reach us by phone as well.
+91-97737 28034
Our Location
Rohini, Sector-3, Delhi-110085
