Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
How to Master SQL for Technical Interviews
If you’re gearing up for technical interviews at top tech companies, mastering SQL is non-negotiable—it’s a staple in roles from data analysts to software engineers, appearing in over 70% of data-related interviews according to recent reports from platforms like DataLemur and DataCamp. Whether you’re brushing up on basics or tackling advanced queries, this guide will equip you with the knowledge and strategies to ace those SQL rounds. If you’re ready to dive deeper and access free resources or updates on our latest courses, sign up here to get started on your path to interview success.
SQL, or Structured Query Language, remains a cornerstone of technical interviews because it tests your ability to manipulate and extract insights from data efficiently. With companies like Google, Amazon, and Meta (FAANG) emphasizing real-world problem-solving, understanding SQL goes beyond rote memorization—it’s about applying concepts to business scenarios. In this post, we’ll cover everything from fundamentals to advanced techniques, backed by expert insights and real interview questions. Let’s break it down step by step.
Why SQL Matters in Technical Interviews
SQL’s popularity in interviews stems from its ubiquity in handling relational databases, which power most modern applications. A 2025 survey from KDnuggets highlights that candidates often falter on advanced SQL concepts like window functions and optimization, which can make or break your performance. Research from InterviewBit and DataCamp shows that 85% of intermediate practitioners struggle with subqueries and joins under time pressure.
To stand out, focus on practical application. As Nick Singh, author of Ace the Data Science Interview, notes, “SQL questions at FAANG simulate real analytics tasks, like calculating user metrics or revenue trends.” This guide draws from such expert advice to provide actionable steps.
SQL Fundamentals: Building a Strong Foundation
Before diving into complex queries, solidify the basics. These form the backbone of most interview questions and ensure you can handle data retrieval confidently.
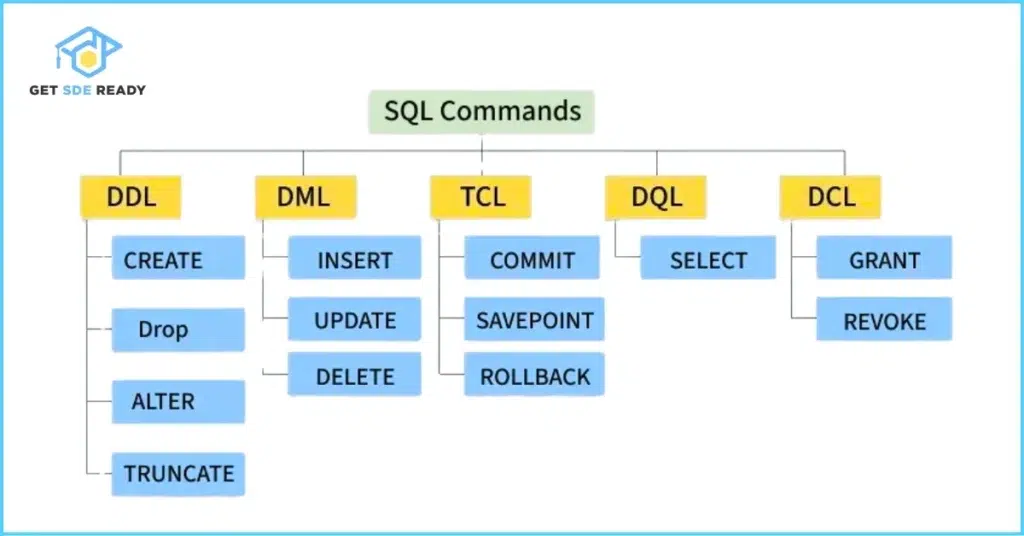
Core SQL Commands and Syntax
Start with the SELECT statement, the most common way to query data. For example:
SELECT column1, column2
FROM table_name
WHERE condition;
This retrieves specific columns from a table based on a condition. Always remember: SELECT specifies what to return, FROM indicates the source, and WHERE filters rows.
Key data types include INT (integers), VARCHAR (strings), DATE (dates), and DECIMAL (precise numbers). Constraints like NOT NULL ensure data integrity, preventing empty values in critical fields.
Filtering and Sorting Data
Use WHERE for conditions, such as equality (=), inequality (<>), or ranges (BETWEEN). Combine with logical operators like AND/OR for complex filters.
Sorting comes via ORDER BY:
SELECT * FROM employees
ORDER BY salary DESC;
This lists employees by descending salary. Limit results with LIMIT or TOP (dialect-specific) for top-N queries.
Aggregations and Grouping
Aggregate functions summarize data: COUNT() for row counts, SUM() for totals, AVG() for averages, MIN()/MAX() for extremes.
Group results with GROUP BY:
SELECT department, AVG(salary) AS avg_salary
FROM employees
GROUP BY department
HAVING AVG(salary) > 50000;
HAVING filters aggregated groups, unlike WHERE which filters individual rows.
If you’re preparing for full-stack roles, mastering these alongside web development can give you an edge—check out our comprehensive web development course for integrated learning.
Intermediate SQL: Joins, Subqueries, and More
Once basics are down, level up with techniques for multi-table operations and nested logic.
Mastering Joins
Joins combine tables based on related columns. Inner joins return matching rows:
SELECT e.name, d.department_name
FROM employees e
INNER JOIN departments d ON e.department_id = d.id;
Left joins include all from the left table, with NULLs for non-matches. Right and full joins follow similarly. Cross joins produce Cartesian products—useful but resource-intensive.
Expert tip from LearnSQL: “Misunderstanding joins is a top failure point; practice with real datasets to visualize outputs.”
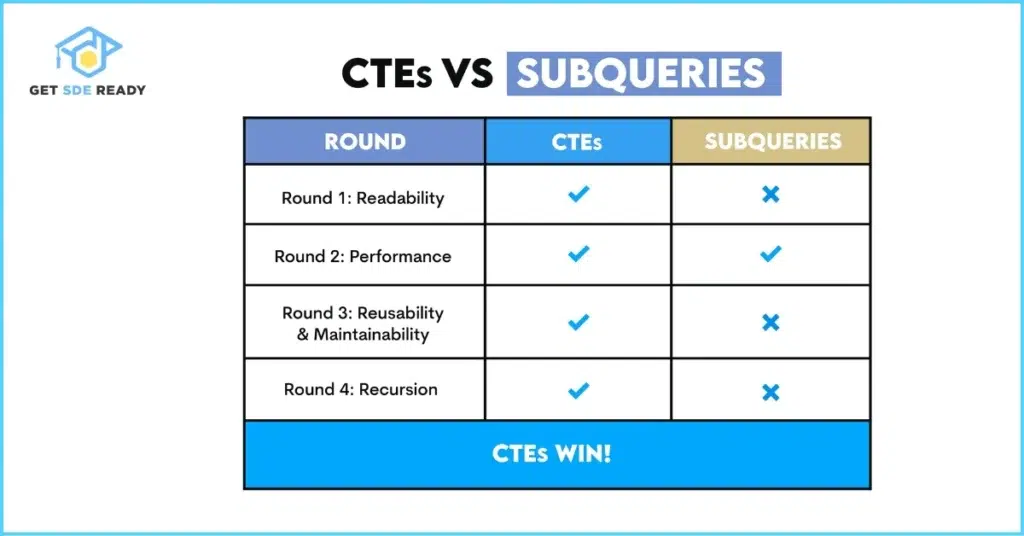
Subqueries and CTEs
Subqueries nest queries:
SELECT name
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
This finds above-average earners. Correlated subqueries reference outer queries, running per row.
Common Table Expressions (CTEs) improve readability:a
WITH high_earners AS (
SELECT * FROM employees WHERE salary > 100000
)
SELECT * FROM high_earners;
CTEs are temporary and great for recursive queries, like hierarchical data.
Set Operations
UNION combines results (removes duplicates), UNION ALL keeps them. INTERSECT finds commons, EXCEPT/MINUS subtracts one set from another.
For data science aspirants, these pair well with Python—explore our data science course to see SQL in action with ML pipelines.
Advanced SQL: Window Functions, Optimization, and Design
FAANG interviews often probe deeper, testing efficiency and scalability.
Window Functions
These perform calculations across row sets without grouping:
SELECT name, salary,
ROW_NUMBER() OVER (ORDER BY salary DESC) AS rank
FROM employees;
Functions like RANK(), DENSE_RANK(), LAG()/LEAD() for comparisons, and NTILE() for percentiles are common. Partition with PARTITION BY for group-specific windows.
As per a 2025 KDnuggets article, “Window functions trip up 60% of candidates—practice them for metrics like running totals or rankings.”
Performance Optimization
Indexes speed lookups but slow writes—use on frequently queried columns. Clustered indexes sort data physically; non-clustered create separate structures.
Analyze execution plans with EXPLAIN to spot bottlenecks. Partition large tables by keys like date for faster scans.
Avoid full table scans with WHERE on indexed columns. For big data, consider materialized views or denormalization for read-heavy workloads.
Deadlocks arise from conflicting locks—prevent with consistent access order and short transactions.
Database Design Principles
Normalization reduces redundancy (e.g., 3NF eliminates transitive dependencies). Denormalization trades space for speed in analytics.
OLTP vs. OLAP: OLTP for transactions (normalized, ACID-compliant); OLAP for analysis (denormalized, star/snowflake schemas).
Surrogate keys (artificial IDs) aid warehousing; staging tables in ETL clean data before loading.
If system design intrigues you, our master DSA, web dev, and system design course covers these holistically.
Effective Practice Strategies for SQL Interviews
Practice is key—aim for 100+ problems before interviews. Platforms like LeetCode, HackerRank, and DataLemur offer FAANG-style questions.
Steps:
- Understand schemas and requirements.
- Write iterative code: Start simple, add complexity.
- Optimize: Check for efficiency.
- Explain verbally: Mock interviews build confidence.
Time yourself—online assessments often limit to 1 hour for 2-3 questions. Join communities like Reddit’s r/SQL for discussions.

For quick ramps, try our crash course tailored for last-minute prep.
Statistics show consistent practice boosts success rates by 40%, per Interviewing.io.
30 Real SQL Interview Questions from FAANG and Beyond
Based on real questions from Google, Amazon, Meta, and others (sourced from DataLemur, InterviewBit, DataCamp, and Datainterview), here are 30 in-depth questions with solutions. These span beginner to advanced, with explanations.
- What is the difference between INNER JOIN and LEFT JOIN? (Google) Answer: INNER JOIN returns only matching rows; LEFT JOIN returns all from left table and matches from right, with NULLs for non-matches. Explanation: Use INNER for intersections, LEFT for inclusive left data. Example: Matching employees to departments vs. all employees including those without departments.
Write a query to find the second highest salary. (Am
SELECT MAX(salary) AS second_highest
FROM employees
WHERE salary < (SELECT MAX(salary) FROM employees);
2 Explanation: Subquery finds max; outer selects next max. Handles ties implicitly; for distinct, use DENSE_RANK().
Explain window functions with an example. (Meta) Answer: They compute over row windows. Example:
SELECT name, salary, RANK() OVER (ORDER BY salary DESC) AS rank FROM employees;
3 Explanation: RANK assigns positions with gaps for ties; use PARTITION BY for departments.
DELETE FROM table WHERE id NOT IN (SELECT MIN(id) FROM table GROUP BY duplicate_col);
4 Explanation: Groups duplicates, keeps min ID per group; assumes ID column.
WITH avg_sal AS (SELECT AVG(salary) FROM employees) SELECT * FROM employees WHERE salary > (SELECT * FROM avg_sal);
5 Explanation: Improves readability for complex queries; supports recursion.
SELECT e.name FROM employees e JOIN employees m ON e.manager_id = m.id WHERE e.salary > m.salary;
- Explanation: Self-join compares salaries.
Calculate cumulative sum of sales by day. (Amazon) Answer:
SELECT date, SUM(sales) OVER (ORDER BY date) AS cumulative FROM sales;
- Explanation: Window function for running total.
- What are indexes, and when to use them? (FAANG) Answer: Data structures for fast lookups. Use on WHERE/JOIN columns; pros: speed; cons: slower inserts. Explanation: Clustered sorts data; non-clustered references it.
SELECT measurement_day, SUM(CASE WHEN ROW_NUMBER() OVER (PARTITION BY measurement_day ORDER BY measurement_time) % 2 = 1 THEN measurement_value ELSE 0 END) AS odd_sum,
SUM(CASE WHEN ROW_NUMBER() % 2 = 0 THEN measurement_value ELSE 0 END) AS even_sum FROM measurements GROUP BY measurement_day;
1 Explanation: ROW_NUMBER assigns positions; CASE sums odds/evens.
10 Median search frequency from summary table. (Google) Answer: Use cumulative distribution to find median. Explanation: Expand buckets, find middle value(s) via ROW_NUMBER or PERCENTILE_CONT.
11 Difference between WHERE and HAVING? (InterviewBit) Answer: WHERE filters rows pre-group; HAVING post-group. Explanation: HAVING uses aggregates.
12 Pattern matching with LIKE. (FAANG) Answer: SELECT * FROM table WHERE col LIKE ‘A%’; Explanation: % any chars; _ single char.
13 Recursive stored procedure example. (Advanced) Answer: Procedure calling itself, e.g., factorial. Explanation: Boundary condition prevents infinite loops.
14 OLTP vs. OLAP. (DataCamp) Answer: OLTP: transactions; OLAP: analysis. Explanation: OLTP normalized; OLAP denormalized.
15 Unique vs. Primary Key. (InterviewBit) Answer: Primary: unique + not null, one per table; Unique: allows null (sometimes). Explanation: Primary identifies records.
16 Cross Join use case. (DataCamp) Answer: All combinations. Explanation: No ON; for testing pairs.
17Self-Join for hierarchy. (Google) Answer: Join table to itself. Explanation: For manager-employee.
18 User-defined function types. (Advanced) Answer: Scalar (single value); Table-valued (table). Explanation: Reusable logic.
19 Collation sensitivity. (InterviewBit) Answer: Case, accent, kana, width. Explanation: Affects sorting/comparison.
20 Data integrity types. (DataCamp) Answer: Entity, referential, domain. Explanation: Constraints enforce.
21 Clustered vs. Non-clustered index. (FAANG) Answer: Clustered: data order; Non: separate. Explanation: One clustered per table.
22 Query execution plan. (Datainterview) Answer: Shows processing steps. Explanation: Optimize with EXPLAIN.
23 Deadlocks prevention. (Advanced) Answer: Consistent lock order. Explanation: Monitor with tools.
24 Partitioning benefits. (Datainterview) Answer: Faster queries on subsets. Explanation: By date/range.
25 Staging table in ETL. (FAANG) Answer: Temporary for cleaning. Explanation: Before warehouse load.
26 Star vs. Snowflake schema. (Datainterview) Answer: Star: denormalized; Snowflake: normalized. Explanation: Star faster for queries.
SELECT l.title, s.name FROM listings l JOIN sellers s ON l.seller_id = s.id WHERE s.join_date >= '2023-01-01' ORDER BY l.price DESC LIMIT 3;
28 Explanation: Join, filter, sort.
29 Sellers without electronics listings. (Amazon) Answer: Anti-join with LEFT and NULL check. Explanation: Counts total listings too.
30Earliest joiners with above-average prices. (Meta) Answer: Subqueries for min date and avg price. Explanation: Correlated for categories.
7-day moving average. (FAANG) Answer:
SELECT date, AVG(sales) OVER (ORDER BY date ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) FROM sales;
- Explanation: Window frame for rolling avg.
These questions, drawn from real FAANG interviews, emphasize problem-solving. Practice explaining your thought process—interviewers value clarity.
For DSA integration, our DSA course complements SQL prep perfectly.
Conclusion: Your Path to SQL Mastery
Mastering SQL requires consistent practice and understanding real-world applications. Start with basics, build to advanced, and simulate interviews. With dedication, you’ll tackle any query thrown your way.
Ready to accelerate? Explore our courses for hands-on guidance. What’s one SQL concept you’ll practice today? Share in the comments!
FAQs
What are the most common SQL joins in interviews?
- INNER, LEFT, RIGHT, and FULL joins are staples; practice with Venn diagrams for visualization.
How do I prepare for advanced SQL window functions?
- Focus on RANK, ROW_NUMBER, and OVER clauses; solve LeetCode problems for running totals and partitions.
What's the difference between subqueries and CTEs in SQL?
- Subqueries are nested; CTEs are named temporary sets for better readability in complex queries.
How can I optimize SQL queries for large datasets?
- Use indexes on filter columns, avoid SELECT *, and analyze execution plans with EXPLAIN.

DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00
Accelerate your Path to a Product based Career
Boost your career or get hired at top product-based companies by joining our expertly crafted courses. Gain practical skills and real-world knowledge to help you succeed.

Low & High Level System Design
- 20+ Live Classes & Recordings
- 24*7 Live Doubt Support
- Case Studies
- Comprehensive Notes
- HackerRank Tests
- Topic-wise Quizzes
- Access to Global Peer Community
- Interview Prep Material
Buy for 60% OFF
₹20,000.00 ₹8,999.00

Mastering GenAI / LLM Engineering
- 100+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 50% OFF
₹39,999.00 ₹19,999.00

Mastering Data Structures & Algorithms
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests
- Access to Global Peer Community
- Topic-wise Quizzes
- Interview Prep Material
Buy for 40% OFF
₹9,999.00 ₹5,999.00

Data Analytics
- 20+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 15+ Hands-on Live Projects
- Comprehensive Notes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 70% OFF
₹9,999.00 ₹2,999.00

SDE 360: Master DSA, System Design, AI & Behavioural
- 100+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 50% OFF
₹39,999.00 ₹19,999.00

Fast-Track to Full Spectrum Software Engineering
- 120+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- 12+ live Projects & Deployments
- Case Studies
- Access to Global Peer Community
Buy for 51% OFF
₹35,000.00 ₹16,999.00
Reach Out Now
If you have any queries, please fill out this form. We will surely reach out to you.
Contact Email
Reach us at the following email address.
arun@getsdeready.com
Phone Number
You can reach us by phone as well.
+91-97737 28034
Our Location
Rohini, Sector-3, Delhi-110085
