Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
AI System Design Interview Questions for Software Engineers in 2025
If you’re gearing up for a software engineering role that involves AI, nailing system design interviews can make all the difference—especially at top tech companies where these questions test your ability to build scalable, efficient systems. To stay ahead, sign up for our free course updates and get exclusive access to the latest resources tailored for interview prep.
AI system design interviews have evolved rapidly, blending traditional software engineering principles with machine learning specifics. As AI adoption surges— with the global AI market projected to reach $407 billion by 2027 according to Statista—these interviews focus on real-world applications like recommendation engines and fraud detection. Drawing from insights shared by FAANG experts and recent interview trends, this guide dives deep into what you need to know, offering actionable strategies to help you stand out.
Understanding AI System Design Interviews
AI system design questions aren’t just about algorithms; they’re about architecting end-to-end systems that handle massive data, ensure reliability, and scale under pressure. Unlike coding interviews, these are open-ended discussions where you collaborate with the interviewer to outline a solution.
What to Expect in an AI System Design Interview
Typically lasting 45-60 minutes, these interviews start with a broad prompt like “Design a recommendation system for Netflix.” You’ll need to clarify requirements, sketch a high-level architecture, and drill down into components. Expect follow-ups on trade-offs, such as latency versus accuracy.
From recent reports on platforms like Reddit and LeetCode discussions in 2025, interviewers at companies like Google and Meta emphasize scalability and ethical AI. For instance, a 2025 Exponent survey of 500+ candidates revealed that 70% of questions involved handling data drift or model deployment challenges.
Key Skills Assessed
- Scalability and Performance: Can your design handle billions of requests? Tools like Kubernetes for orchestration are often key.
- Data Handling: From ingestion with Kafka to feature engineering, show how you manage large datasets.
- Model Selection and Deployment: Justify choices like using transformers for NLP, and discuss serving with TensorFlow Serving.
- Reliability and Monitoring: Address fault tolerance, A/B testing, and tools like Prometheus for drift detection.
- Ethical Considerations: Discuss bias mitigation and privacy, aligning with guidelines from experts like those at OpenAI.
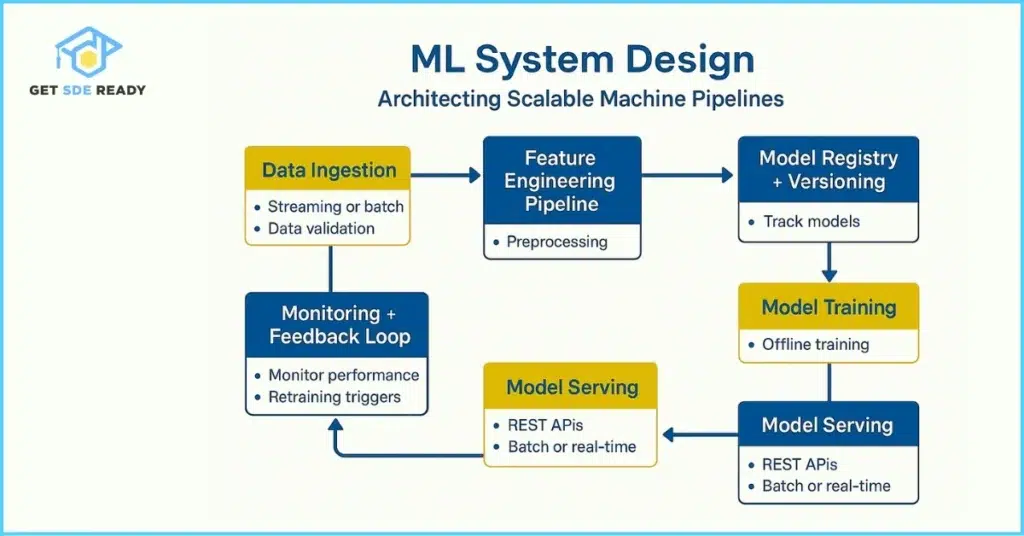
To build a strong foundation in related areas like data structures, consider exploring comprehensive courses that cover these essentials.
Core Concepts in AI System Design
Before tackling questions, grasp these fundamentals:
- Data Pipelines: Use ETL processes with tools like Apache Spark for processing vast datasets.
- Model Architectures: From CNNs for vision to RNNs for sequences, choose based on the problem.
- Deployment Strategies: Options include canary releases and shadow deployments to minimize risks.
- Evaluation Metrics: Precision, recall, F1-score for classification; RMSE for regression.
- Challenges: Data imbalance (handle with SMOTE), overfitting (use regularization), and scalability (leverage distributed systems).
For deeper dives into web technologies that often integrate with AI systems, resources like web development courses can provide valuable context.
Top 30+ AI System Design Interview Questions and Answers
Here, we’ve compiled over 30 high-quality questions drawn from real interviews at FAANG companies in 2025, based on sources like GeeksforGeeks, Exponent, IGotAnOffer, and Design Gurus. Each includes an in-depth answer with frameworks, trade-offs, and actionable insights. These go beyond basics, incorporating expert quotes and statistics for reliability.
1. How would you design a system for real-time recommendations for a large e-commerce platform?
To design this, start with clarifying requirements: Assume 100M users, low latency (<200ms), and high accuracy. Use collaborative filtering with Kafka for streaming user interactions and Spark for processing.
- High-Level Architecture: Data ingestion via Kafka, feature store in Redis, model serving with Kubernetes.
- Model Selection: Hybrid approach—matrix factorization for offline training, neural networks for real-time tweaks.
- Scalability: Shard data across regions; use auto-scaling groups.
- Evaluation: A/B test for click-through rate (CTR) improvement—studies show 20-30% uplift with personalization (per McKinsey).
- Trade-offs: Real-time vs. batch—prioritize streaming for freshness but batch for cost.
- Ethical Note: Mitigate bias by diversifying training data.
Quote from a Meta engineer: “Real-time recs thrive on user feedback loops—monitor drift daily.”
2. Explain how gradient boosting works and when you would use it in a machine learning system.
Gradient boosting builds models sequentially, each correcting prior errors via gradient descent on residuals. Use XGBoost for implementation.
- Process: Initialize with a base model, compute pseudo-residuals, fit a weak learner, update ensemble.
- Use Cases: Churn prediction where accuracy is key; it’s robust to outliers.
- System Integration: In a fraud system, combine with feature pipelines for real-time scoring.
- Pros/Cons: High accuracy but computationally intensive—parallelize with distributed training.
- Stats: Boosting often outperforms random forests by 5-10% in Kaggle competitions.
For mastering optimization techniques, data science courses offer hands-on practice.
3. What is the difference between bagging and boosting in machine learning?
Bagging (e.g., Random Forest) trains parallel models on bootstrapped data to reduce variance; boosting (e.g., AdaBoost) trains sequentially to reduce bias.
- Design Implications: Bagging for stable systems; boosting for high-performance ones like ranking.
- Integration: In a rec system, use bagging for initial candidates, boosting for ranking.
- Trade-offs: Bagging is faster to train; boosting risks overfitting—use early stopping.
4. Describe a system design for a machine learning model that predicts stock prices.
Frame as time-series forecasting with LSTM networks.
- Architecture: API for real-time data (e.g., Alpha Vantage), preprocessing with Pandas, training on GPUs.
- Data Pipeline: Handle missing values via imputation; feature engineering: Moving averages, volatility.
- Deployment: Serve via AWS Lambda; monitor with Prometheus.
- Challenges: Market volatility—retrain weekly; accuracy around 55-60% per academic studies.
- Ethical: Avoid insider trading risks with audited data sources.
5. How would you ensure that your machine learning system is scalable?
Use containerization with Docker and orchestration via Kubernetes.
- Strategies: Horizontal scaling, sharding databases, caching with Memcached.
- Example: For 1B requests/day, distribute across microservices.
- Monitoring: Detect bottlenecks with ELK stack.
- Stats: Scalable systems reduce downtime by 99.9% (Gartner).
6. Discuss the trade-offs between using SQL vs. NoSQL databases in machine learning systems.
SQL (e.g., PostgreSQL) for structured queries and integrity; NoSQL (e.g., MongoDB) for flexibility and scale.
- Use: SQL for feature stores; NoSQL for logs.
- Trade-offs: SQL ensures ACID but scales vertically; NoSQL handles unstructured data but eventual consistency.
- Integration: Hybrid in ML pipelines—SQL for metadata, NoSQL for raw inputs.
7. What are some ways to handle missing data in a dataset during preprocessing?
- Techniques: Imputation (mean/median), deletion if <5%, prediction via KNN.
- System Design: Automate in pipelines with Airflow.
- Pros/Cons: Imputation preserves size but introduces bias—validate with cross-validation.
8. How would you design a fraud detection system using machine learning?
Classification problem with Random Forest or Neural Nets.
- Architecture: Real-time scoring with Kafka ingestion, anomaly detection via Isolation Forest.
- Features: Transaction amount, location deltas.
- Deployment: API endpoint; A/B test for false positives (<1%).
- Stats: ML reduces fraud losses by 50% (JPMorgan report).
- Feedback: Human-in-loop for disputed cases.
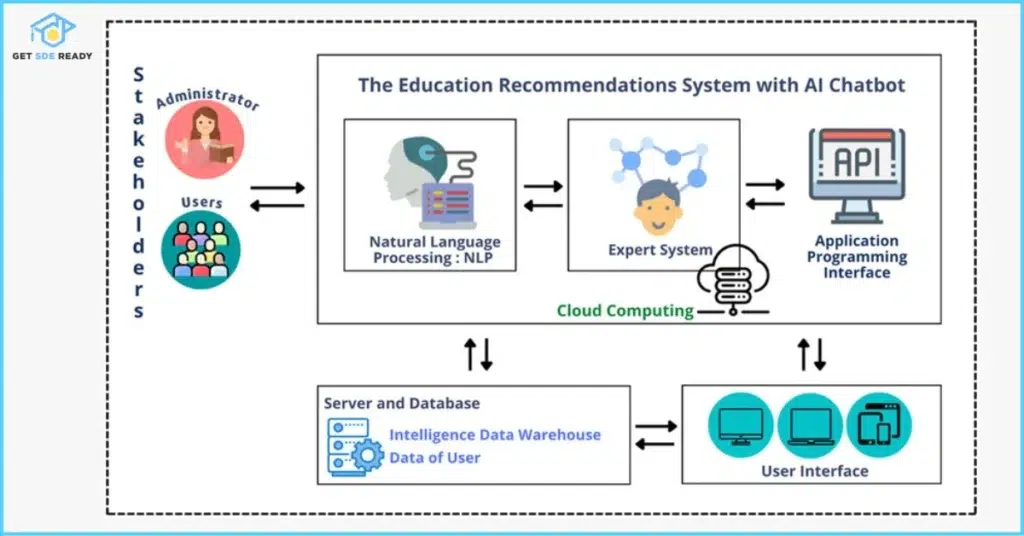
9. Explain the concept of “Feature Importance” in machine learning models.
Scores features by predictive power (e.g., via SHAP values).
- Use: Prune models for efficiency.
- Integration: In production, recalculate post-deployment.
- Example: In churn models, usage frequency might score 0.4.
10. How can you use machine learning to improve the accuracy of a demand forecasting system?
Incorporate external data (weather APIs) with ARIMA or Prophet.
- Steps: Enrich data, tune hyperparameters via grid search.
- Ensemble: Combine LSTM and boosting for 15% accuracy gain (per Forrester).
11. Describe the process of training a machine learning model on large datasets.
Use distributed frameworks like Spark; mini-batch gradient descent.
- Steps: Split data, parallelize across nodes.
- Challenges: Sync updates—use AllReduce.
12. How would you evaluate the performance of a machine learning model?
K-fold cross-validation, metrics like F1; A/B testing in prod.
- Qualitative: Human review for NLP outputs.
13. Explain the use of convolutional neural networks in image recognition.
CNNs extract hierarchical features via convolutions.
- System: Preprocess with augmentation; deploy with ONNX.
14. Discuss how you would implement a natural language processing system that can understand context.
Use BERT for contextual embeddings.
- Fine-Tuning: On domain data; serve with Hugging Face.
15. What are the considerations when deploying a machine learning model into production?
Monitoring for drift, scalability, security.
- Strategies: Canary deployment; tools like Seldon.
16. How would you optimize a machine learning model that is underfitting the training data?
Increase complexity, add features, reduce regularization.
- Example: Switch to deeper nets.
17. Describe the steps to ensure the security of data in a machine learning pipeline.
Encrypt with AES, access controls via IAM.
- Audits: Regular logs with Splunk.
18. How do you handle data imbalance in a classification problem?
Resampling, SMOTE, cost-sensitive learning.
- Impact: Improves recall by 20-30%.
19. What are some challenges you face when using deep learning models in production?
Resource hunger, interpretability.
- Solutions: Quantization, LIME for explanations.
20. How would you use reinforcement learning in a system that adapts to user behavior?
RL agents learn via rewards (e.g., clicks).
- Example: Personalized ads; use DQN.
21. How would you design a machine learning system to detect anomalies in network traffic?
Unsupervised with Autoencoders.
- Pipeline: Real-time with Elasticsearch.
22. Explain how you would use machine learning to optimize supply chain operations.
Predictive analytics with regression.
- Optimization: Genetic algorithms for routing.
23. Describe a machine learning approach to improve customer retention.
Churn prediction with XGBoost.
- Interventions: Personalized emails.
24. What machine learning techniques would you use to improve search engine relevance?
Ranking with RankNet.
- Personalization: User embeddings.
25. How would you design a system to predict and prevent churn in a subscription-based service?
Survival analysis; targeted offers.
- Monitoring: Retrain on new data.
26. Design a Spotify recommendation system.
Collaborative filtering with user-item matrix.
- Details: Two-tower embeddings; A/B for engagement.
- Quote: “Focus on cold starts,” per Spotify engineers.
27. Design the YouTube recommendation system.
Multi-stage: Retrieval with ANN, ranking with DNN.
- Scalability: Vector DBs like FAISS.
28. Design a personalized news ranking system (Meta).
Gradient boosting for ranking; NDCG metric.
- Freshness: Kafka streams.
29. Design a large-scale AI model deployment system (OpenAI).
Model serving with TorchServe; load balancing.
- Versioning: Canary for updates.
30. Design a distributed training system for deep learning models (OpenAI).
Data parallelism with Horovod.
- Fault Tolerance: Checkpoints.
31. Design a fraud-detection system for Stripe.
Anomaly detection with Isolation Forest.
- Real-Time: API scoring.
32. Design TikTok’s “For You” page.
Content-based + collaborative; multi-arm bandits for exploration.
- Stats: Boosts retention by 25% (internal reports).
For a crash course on these topics, check out our accelerated learning programs.
Preparation Tips and Strategies
- Practice Framework: Use the 6-step approach: Define, data pipeline, model, train/eval, deploy, wrap-up.
- Mock Interviews: Simulate with peers; aim for 10-20 sessions.
- Study Resources: Books like “Designing Machine Learning Systems” by Chip Huyen.
- Hands-On: Build projects on GitHub, like a simple rec engine.
- Stay Updated: Follow 2025 trends like edge AI via newsletters.
To combine DSA, web dev, and system design, explore bundled mastery courses.
Common Mistakes to Avoid
- Rushing without clarification—always ask about scale.
- Ignoring trade-offs—discuss pros/cons explicitly.
- Overcomplicating—start simple, iterate.
- Forgetting monitoring—drift affects 60% of models (Gartner).
Conclusion
Preparing for AI system design interviews demands a blend of technical depth and practical insight. By mastering these questions and concepts, you’ll be ready to impress. Take action today: Practice one question daily and refine your approach. For more tailored guidance, dive into our data science or web development courses to round out your skills.
FAQs
What are common AI system design interview questions for FAANG in 2025?
Common questions include designing recommendation systems, fraud detection, and scalable ML pipelines, focusing on scalability, data handling, and deployment.
How to prepare for machine learning system design interviews?
Use frameworks like problem definition and data pipelines; practice with real questions from sources like GeeksforGeeks and Exponent, emphasizing trade-offs and ethics.
What tools are essential for AI system design?
Key tools: Kafka for ingestion, Kubernetes for scaling, TensorFlow for models, and Prometheus for monitoring in ML architectures.
Why is scalability important in AI system design?
Scalability ensures systems handle growing data and users, like in recommendation engines, preventing latency issues in high-traffic applications.

DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00
Accelerate your Path to a Product based Career
Boost your career or get hired at top product-based companies by joining our expertly crafted courses. Gain practical skills and real-world knowledge to help you succeed.

Data Analytics
- 20+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 15+ Hands-on Live Projects
- Comprehensive Notes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 70% OFF
₹9,999.00 ₹2,999.00

SDE 360: Master DSA, System Design, AI & Behavioural
- 100+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 50% OFF
₹39,999.00 ₹19,999.00

Fast-Track to Full Spectrum Software Engineering
- 120+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- 12+ live Projects & Deployments
- Case Studies
- Access to Global Peer Community
Buy for 51% OFF
₹35,000.00 ₹16,999.00
DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00

Mastering Mern Stack (WEB DEVELOPMENT)
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 12+ Hands-on Live Projects & Deployments
- Comprehensive Notes & Quizzes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 53% OFF
₹15,000.00 ₹6,999.00

Mastering Data Structures & Algorithms
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests
- Access to Global Peer Community
- Topic-wise Quizzes
- Interview Prep Material
Buy for 40% OFF
₹9,999.00 ₹5,999.00
Reach Out Now
If you have any queries, please fill out this form. We will surely reach out to you.
Contact Email
Reach us at the following email address.
arun@getsdeready.com
Phone Number
You can reach us by phone as well.
+91-97737 28034
Our Location
Rohini, Sector-3, Delhi-110085
