Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Caching Strategies Explained with Interview Examples
Imagine you’re building a high-traffic web application where every millisecond counts—users expect lightning-fast responses, and your backend can’t afford to hit the database for every request. That’s where caching comes in, a powerhouse technique that stores frequently accessed data for quick retrieval, slashing latency and boosting performance. To get started with hands-on learning and stay ahead in mastering these concepts, sign up for our free courses and receive the latest updates on essential tech skills.
In this comprehensive guide, we’ll dive deep into caching strategies, exploring their mechanics, real-world applications, and how they can make or break system performance. Whether you’re a developer optimizing your app or prepping for a technical interview, understanding caching isn’t just useful—it’s essential. We’ll back this up with factual insights, like how effective caching can reduce database costs by up to 70% according to AWS documentation, and include expert perspectives from industry leaders. Let’s break it down step by step.
Understanding the Basics of Caching
Caching is fundamentally about storing copies of data in a temporary, high-speed location to avoid redundant computations or database queries. At its core, it leverages the principle of locality—data that’s accessed once is likely to be accessed again soon.
Think of caching as a barista remembering your usual coffee order; instead of checking the menu every time, they serve it instantly. In software terms, this means storing results from expensive operations, like API calls or complex calculations, so future requests can pull from the cache instead of recalculating.
Key benefits include:
- Performance Boost: Caching can improve read throughput by orders of magnitude—studies from Redis Labs show systems handling millions of operations per second with proper caching.
- Cost Savings: By offloading databases, you reduce query loads; for instance, Netflix reports caching helps manage petabytes of data without proportional infrastructure costs.
- Scalability: It handles traffic spikes gracefully, as seen in e-commerce sites during Black Friday sales.
- User Experience: Faster load times lead to lower bounce rates—Google research indicates a 100ms delay can drop conversions by 7%.
However, caching isn’t a silver bullet. Poor implementation can lead to stale data or increased complexity. As Martin Fowler, a renowned software architect, notes, “Caching is one of those things that’s simple in concept but devilishly tricky in practice.”
For those diving into related topics like data structures that power caches, our DSA course offers practical exercises to build your foundation.
Types of Caching Strategies
Caching strategies dictate how data is read from and written to the cache. Choosing the right one depends on your workload—read-heavy apps might favor lazy loading, while write-intensive ones need consistency guarantees. Below, we explore the most common strategies, with pros, cons, and examples.
Cache-Aside (Lazy Loading)
In cache-aside, the application manages the cache directly. On a read, it checks the cache first; if missed, it fetches from the database and populates the cache.
- How It Works: Application code handles logic—e.g., in Java with Redis: check if key exists, if not, query DB and set key with TTL.
- Pros: Flexible control, only caches requested data (efficient for sparse access).
- Cons: Initial cache misses add latency; risk of thundering herd (many simultaneous misses overwhelming the DB).
- Use Case: Social media feeds where user-specific data is queried on demand. As per a GeeksforGeeks analysis, this strategy shines in read-heavy scenarios with unpredictable access patterns.
Read-Through
Here, the cache itself fetches data from the source on a miss, transparent to the application.
- How It Works: Cache acts as a proxy—e.g., using libraries like Guava in Java, where a loader function pulls from DB.
- Pros: Simplifies app code; ensures consistency as cache handles loading.
- Cons: Tighter coupling; first-time misses still hit the source.
- Use Case: Database query results in ORM tools like Hibernate’s second-level cache. Expert quote from AWS docs: “Read-through is ideal for reactive loading in high-availability systems.”
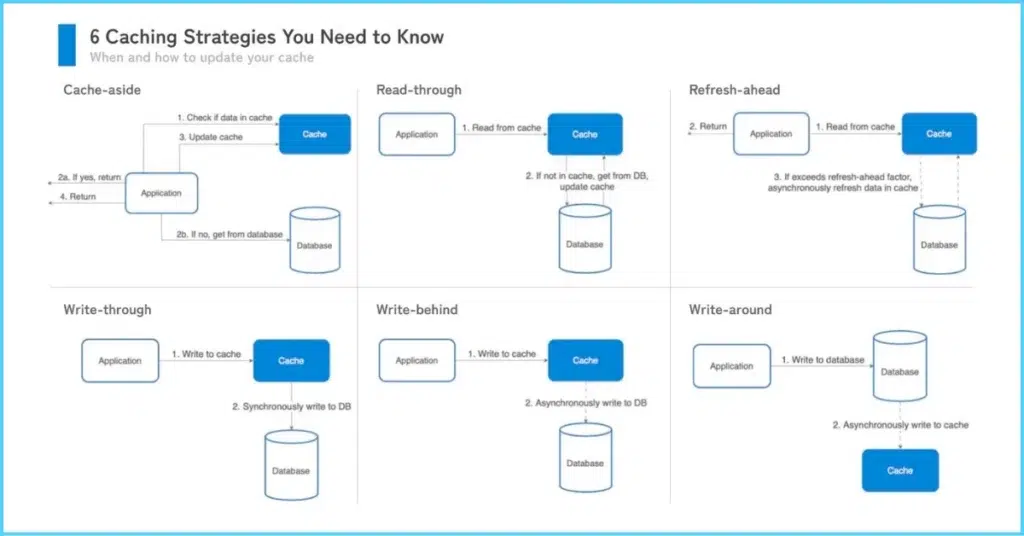
Write-Through
Writes update both cache and database synchronously.
- How It Works: Application writes to cache, which then persists to DB before acknowledging.
- Pros: Strong consistency—no stale data; reduces future read latency.
- Cons: Higher write latency due to dual operations; can bottleneck under heavy writes.
- Use Case: Financial apps where accuracy trumps speed, like stock trading platforms. Statistics from Microsoft Azure show write-through can maintain 99.99% data integrity but at 20-30% higher write costs.
Write-Around
Writes go directly to the database, bypassing the cache; cache updates only on subsequent reads.
- How It Works: Combine with cache-aside—write to DB, invalidate cache if needed.
- Pros: Avoids caching rarely read data; efficient for write-once-read-never patterns.
- Cons: Recent writes cause cache misses on reads.
- Use Case: Logging systems or time-series data. As noted in Medium articles on caching, this prevents cache pollution in write-heavy environments.
Write-Back (Write-Behind)
Writes hit the cache first, with asynchronous updates to the database.
- How It Works: Cache acknowledges write immediately, batches updates to DB later.
- Pros: Low write latency; high throughput for bursts.
- Cons: Risk of data loss if cache fails before sync; eventual consistency.
- Use Case: IoT data ingestion where immediate persistence isn’t critical. Redis benchmarks indicate write-back can handle 10x more writes per second than synchronous methods.
Refresh-Ahead
Proactively refreshes cache entries before expiration based on access patterns.
- How It Works: Monitor usage and prefetch data—e.g., using predictive algorithms in distributed caches like Hazelcast.
- Pros: Minimizes misses; ideal for predictable workloads.
- Cons: Over-fetching wastes resources if predictions are wrong.
- Use Case: E-commerce product catalogs with seasonal trends.
For web developers integrating caching into full-stack apps, our web development course provides modules on implementing these strategies with tools like Redis.
Pros and Cons: A Comparative Table
To make selection easier, here’s a table summarizing key strategies:
Strategy | Pros | Cons | Best For |
Cache-Aside | Flexible, efficient memory use | Cache misses, thundering herd | Read-heavy, unpredictable access |
Read-Through | Simplified code, consistency | Coupling, initial misses | Database-integrated apps |
Write-Through | Strong consistency | High write latency | Consistency-critical systems |
Write-Around | Avoids pollution | Misses on recent writes | Write-heavy, infrequent reads |
Write-Back | Fast writes, high throughput | Data loss risk, eventual cons. | Burst traffic, IoT |
Refresh-Ahead | Low misses | Resource waste on bad predicts | Predictable patterns |
Data from sources like The New Stack highlights that combining strategies (e.g., write-around with cache-aside) often yields the best results, balancing latency and complexity.
Best Practices and Actionable Advice
Implementing caching effectively requires more than theory. Here are actionable tips:
- Analyze Workloads: Use tools like New Relic to profile access patterns—cache hot data only.
- Set TTL Wisely: Start with 5-60 minutes; adjust based on data volatility.
- Handle Invalidation: Use event-driven approaches, like pub/sub in Redis, to evict stale entries.
- Monitor Metrics: Track hit rates (aim for >80%), eviction rates, and latency. Quote from Redis.io: “A hit rate below 70% often indicates over-eviction or poor key design.”
- Security Considerations: Encrypt sensitive cached data; avoid caching PII.
- Scale with Distribution: For large systems, use sharded caches like Redis Cluster.
If you’re tackling system design holistically, our master DSA, web dev, and system design course covers caching in distributed environments.
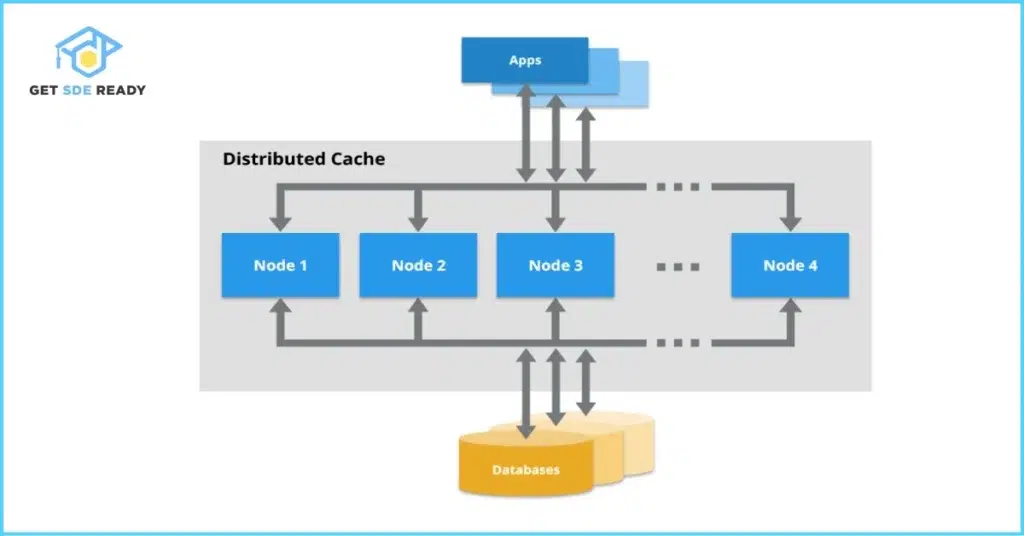
Caching in Distributed Systems
In microservices or cloud setups, caching evolves. Distributed caches like Redis or Memcached share data across nodes, but introduce challenges like consistency (eventual vs. strong) and partitioning.
- Key Concepts: Sharding for load balancing, replication for fault tolerance.
- Challenges: Network latency, coherence issues—solved via protocols like MESI.
- Use Case: Amazon’s ElastiCache handles billions of operations daily, reducing DB load by 90%.
For data scientists dealing with large datasets, explore caching in analytics with our data science course.
Interview Examples: Real Questions from Tech Interviews
Caching is a staple in FAANG interviews, often tied to system design or coding problems. Below are 30+ high-quality questions reportedly asked at companies like Google, Amazon, and Meta, with in-depth answers drawing from real experiences (e.g., from GitHub repos, Devinterview.io, and Glassdoor reports). These go beyond basics, testing depth.
- Define caching in computer programming. Caching stores frequently accessed data in fast memory to reduce retrieval time from slower sources. It improves performance by exploiting temporal and spatial locality. For example, in a web app, caching user profiles avoids repeated DB queries.
- What are the main purposes of caching? Primary goals: enhance speed (reduce latency), cut costs (fewer DB hits), scale systems (handle more traffic), and improve reliability (serve data during outages). Stats: Caching can boost throughput by 5-10x in read-heavy apps.
- Explain cache hit and miss. Hit: Data found in cache (fast access). Miss: Not found, fetch from source (slower). Types of misses: compulsory (first access), capacity (cache full), conflict (mapping issues). To minimize, use larger caches or better policies.
- Impact of cache size on performance? Larger caches increase hit rates but raise costs and potential latency from searches. Optimal size balances hit rate (e.g., 95%) with memory use—use formulas like Belady’s anomaly for prediction.
- Difference between local and distributed caching? Local: Per-instance, fast but not shared (e.g., Guava). Distributed: Across nodes, scalable but networked (e.g., Redis). Use local for low-latency, distributed for high-availability.
- Common cache eviction strategies? LRU (remove least recent), LFU (least frequent), FIFO (oldest first). LRU is popular for temporal locality; LFU for frequency-based workloads.
- What is a cache key? Unique identifier for cached data, often hashed (e.g., URL + params). Good keys ensure collisions are rare and eviction is fair.
- Importance of cache expiration? Prevents stale data; managed via TTL. Without it, caches grow indefinitely, leading to OOM errors.
- How does cache invalidation work? Remove or update entries on data change. Methods: manual (e.g., @CacheEvict in Spring), time-based, or event-driven.
- Steps to implement a basic cache? Use a map for storage, add get/put methods, implement eviction (e.g., LRU with LinkedHashMap in Java).
- Handle cache sync in distributed env? Use pub/sub (Redis) or consensus protocols (Zookeeper) for invalidation broadcasts.
- Role of hash maps in caches? O(1) access for keys; extended with doubly-linked lists for LRU.
- Caching algorithms and differences? Direct-mapped (fast, high conflicts), set-associative (balance), fully-associative (flexible, slow).
- Design for high concurrency? Use thread-safe structures (ConcurrentHashMap), locks, or sharding.
- Prevent cache stampede? Use probabilistic early expiration or locking on misses.
- Trade-offs: read vs write-heavy? Read-heavy: Favor read-through. Write-heavy: Write-back for speed, but risk inconsistency.
- Cache manifest in web apps? Lists resources for offline caching (Service Workers in PWA).
- Ensure cache-DB consistency? Write-through or invalidation events.
- Cache tagging benefits? Group-related items for bulk invalidation (e.g., all “user:123” tags).
- Distributed caching advantages? Scalability, redundancy over local; handles failures via replication.
- Handle partitioning in distributed? Consistent hashing to minimize reshuffling on node changes.
- Consistency models? Eventual (delayed sync, high avail), strong (immediate, low perf).
- Cache replication? Master-slave or peer-to-peer; sync via gossip protocols.
- Avoid coherence issues? Use write-invalidate or write-update protocols.
- Network latency in distributed? Locality-aware placement, compression, batching.
- Challenges in distributed cache? Partitioning, failure detection, hot spots—mitigate with auto-scaling.
- Write-through in distributed? Cache nodes write to shared DB synchronously.
- Handle node failures? Replication and failover; quorum reads/writes.
- Shared vs distributed cache? Shared: Single instance (bottleneck). Distributed: Multi-node (scalable).
- CDN and caching relation? CDNs cache at edges for low-latency global delivery.
- Edge caching use cases? Static assets in web apps; reduces origin load.
- Cache warming? Pre-populate cache on startup; for predictable queries.
- Query caching in DBs? Store results; invalidate on table changes.
- Object caching in OOP? Cache instances; reduces creation overhead.
- Caching in microservices? Per-service caches with central invalidation.
- Serverless caching? Use managed services like AWS ElastiCache.
For quick prep, our crash course condenses these into bite-sized lessons.
Conclusion
Caching strategies are the unsung heroes of performant systems, turning potential bottlenecks into seamless experiences. By mastering these, you’ll not only optimize your code but ace interviews too. Ready to apply this? Experiment with a small project—implement cache-aside in your app and measure the gains. What’s your go-to caching strategy? Share in the comments!
For more on advanced topics, explore our courses.
FAQs
What are the best caching strategies for beginners?
- Start with cache-aside for its simplicity in handling read-heavy web apps and databases.
How does caching improve system design interview performance?
- Demonstrating strategies like LRU eviction shows deep understanding of scalability and latency optimization.
Pros and cons of write-through caching?
- Pros: Data consistency; Cons: Higher latency—ideal for accuracy-focused apps like finance.
How to handle cache invalidation in interviews?
- Discuss methods like TTL or event-driven eviction to prevent stale data in distributed systems.

DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00
Accelerate your Path to a Product based Career
Boost your career or get hired at top product-based companies by joining our expertly crafted courses. Gain practical skills and real-world knowledge to help you succeed.

Data Analytics
- 20+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 15+ Hands-on Live Projects
- Comprehensive Notes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 70% OFF
₹9,999.00 ₹2,999.00

SDE 360: Master DSA, System Design, AI & Behavioural
- 100+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 50% OFF
₹39,999.00 ₹19,999.00

Fast-Track to Full Spectrum Software Engineering
- 120+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- 12+ live Projects & Deployments
- Case Studies
- Access to Global Peer Community
Buy for 51% OFF
₹35,000.00 ₹16,999.00
DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00

Mastering Mern Stack (WEB DEVELOPMENT)
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 12+ Hands-on Live Projects & Deployments
- Comprehensive Notes & Quizzes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 53% OFF
₹15,000.00 ₹6,999.00

Mastering Data Structures & Algorithms
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests
- Access to Global Peer Community
- Topic-wise Quizzes
- Interview Prep Material
Buy for 40% OFF
₹9,999.00 ₹5,999.00
Reach Out Now
If you have any queries, please fill out this form. We will surely reach out to you.
Contact Email
Reach us at the following email address.
arun@getsdeready.com
Phone Number
You can reach us by phone as well.
+91-97737 28034
Our Location
Rohini, Sector-3, Delhi-110085
