Data Processing
Once data is collected and stored (e.g., in S3 or RDS), it needs to be processed and transformed before it can be analyzed. AWS offers multiple services for this, depending on the type of data, the scale, and whether it needs to be processed in real time or in batches.
1. AWS Lambda – Serverless Stream Processing
What it is:
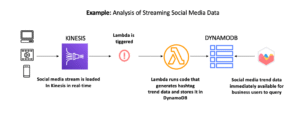
Lambda is a serverless compute service that lets you run small pieces of code in response to events—without managing servers.
Key Features:
- Event-driven and real-time
- Supports multiple languages (Python, Node.js, etc.)
- Pay-per-use pricing model
Use Cases:
- Trigger data processing when a file is uploaded to S3
- Clean and enrich streaming data (e.g., from Kinesis)
- Invoke ETL steps in real-time pipelines
Why it matters:Lambda is perfect for lightweight, real-time operations where speed and cost-efficiency are important.
2. AWS Glue – Serverless ETL & Data Catalog
What it is:
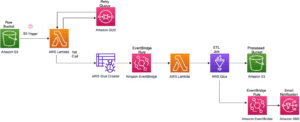
Glue is a managed ETL (Extract, Transform, Load) service. It prepares and transforms data using Apache Spark under the hood, and it also offers a data catalog to track metadata.
Key Features:
- Drag-and-drop ETL job creation (Glue Studio)
- Serverless Spark jobs
- Built-in data catalog for schema discovery
- Integrates directly with S3, Redshift, RDS, and Athena
Use Cases:
- Cleaning and transforming raw data into structured formats
- Scheduling nightly or hourly ETL jobs
- Building centralized metadata catalogs
Why it matters:
Glue automates and simplifies the data preparation phase, especially for building data lakes or Redshift pipelines.
3. Amazon EMR – Big Data Processing with Hadoop & Spark
What it is:
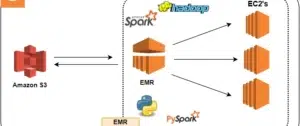
EMR (Elastic MapReduce) is a managed big data platform that runs open-source frameworks like Apache Spark, Hadoop, Hive, and Presto on AWS.
Key Features:
- Customizable cluster configurations
- Scalable for petabyte-level workloads
- Cost-effective with Spot instances and auto-scaling
Use Cases:
- Large-scale data transformation or machine learning training
- Distributed log processing and batch jobs
- Real-time analytics using Apache Spark Streaming
Why it matters:
EMR is ideal for advanced, large-scale processing with full control over the compute environment.
Summary Comparison Table
| Service | Processing Type | Best For | Example Scenario |
|---|---|---|---|
| Lambda | Real-time, event-based | Lightweight transformation tasks | Processing new S3 file uploads |
| Glue | Serverless ETL | Schema discovery, ETL pipelines | Cleaning S3 logs for Redshift |
| EMR | Batch/Stream (Big Data) | Custom big data processing | Running Spark ML jobs on clickstream data |
