Subqueries (Single & Correlated)
In SQL, a subquery is a query inside another query. Think of it like a question that needs to be answered first before answering the main question. Subqueries are useful when you want to filter, compare, or process data based on results from a different query.
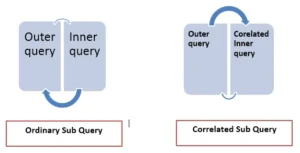
There are two main types of subqueries: Single-row subqueries and Correlated subqueries.
1. Single-Row Subqueries (Simple Subqueries)
A single-row subquery returns only one value (either one column or one row). You use it when you want to compare a column to a single result.
Real-life analogy:
Imagine you want to find the employee with the highest salary. First, you find the maximum salary (that’s your subquery). Then, you look for the employee with that salary (that’s your main query).
Where it’s used:
- Finding customers with the highest order amount
- Comparing a value to the company’s average or minimum
- Filtering records using a result from another table
Why it’s important: It helps answer queries that depend on summary data or a single condition from another dataset.
2. Correlated Subqueries
A correlated subquery is more dynamic—it depends on the row-by-row values of the outer query. This means the subquery runs once for every row in the main query, making it more complex but also more powerful.
Real-life analogy:
Imagine checking for each student whether they scored above the average in their own class. The average is different for each class, so the subquery must run repeatedly for each student with that context.
Where it’s used:
- Getting each customer’s latest order
- Checking if each employee earns more than the average of their department
- Finding repeated behavior within groups (e.g., frequent buyers per region)
Why it’s important: Correlated subqueries allow for row-specific filtering that isn’t possible with joins or simple conditions alone.
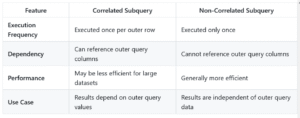
Key Differences