DBMS in Distributed Systems
A Distributed Database Management System (DDBMS) is a type of DBMS where the database is spread across multiple locations, but appears to users as a single unified system. This setup enables scalability, fault tolerance, and localization, which are crucial for modern applications like global e-commerce, cloud computing, and microservices-based systems.
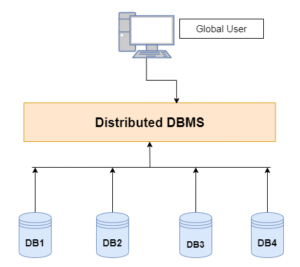
Key Characteristics of Distributed DBMS
1. Data Distribution
The database is physically stored on multiple computers (nodes), often across different geographic locations.
Data can be:
- Fragmented: Divided into pieces (horizontal or vertical fragmentation).
- Replicated: Copies of data are stored at multiple sites for faster access and fault tolerance.
- Distributed: A combination of fragmentation and replication.
2. Transparency
A DDBMS offers different types of transparency to hide system complexities:
- Location Transparency: Users don’t need to know where the data is stored.
- Replication Transparency: Users are unaware of multiple copies.
- Fragmentation Transparency: Users see one logical database even if it’s fragmented.
- Concurrency and Failure Transparency: System handles multiple users and failures internally.
3. Autonomy and Heterogeneity
- Systems may have local control over their own data (semi-autonomous).
- They may run on different platforms or use different DBMS software, leading to heterogeneity.
- A DDBMS coordinates operations across these diverse systems.
Architecture Types of Distributed DBMS
| Architecture | Description | Use Case |
|---|---|---|
| Client-Server | Centralized server handles requests from distributed clients | Web applications |
| Peer-to-Peer | All nodes are equal and share data among themselves | Blockchain, decentralized apps |
| Multi-Database Systems (MDBS) | Different DBMSs operate together via integration mechanisms | Enterprise applications using Oracle + MySQL |
Benefits of Using DBMS in Distributed Systems
- Scalability: More machines can be added easily to handle growth.
- Fault Tolerance: Failure of one site doesn’t affect the whole system.
- Improved Performance: Data can be placed closer to users (reduced latency).
- Modularity: Systems can be maintained and upgraded independently.
Challenges in Distributed DBMS
- Complex Query Processing: Requires optimization across locations.
- Data Consistency: Synchronizing replicated data can be difficult (linked with CAP Theorem).
- Network Reliability: Failures or slowdowns impact performance.
- Security & Access Control: More points of vulnerability in a distributed setup.
Relevance for Student Projects
Understanding DBMS in distributed systems is helpful when students:
- Build cloud-native apps using tools like MongoDB Atlas, Firebase, or CockroachDB
- Work on microservices where each service might own its own database
- Develop real-time collaborative apps that require syncing data across devices
- Learn big data systems like Hadoop and Spark which rely on distributed storage
