Indexing: Single-Level and Multi-Level
Indexing in databases is a technique used to speed up data retrieval. Much like an index in a book helps you find topics quickly, a database index helps locate records without scanning the entire table. Indexes are built on one or more columns of a table and are especially useful for search, sort, and join operations.
What is an Index?
An index is a data structure that maintains a mapping between key values and their corresponding record locations in the table (or data file). It improves query performance, especially when dealing with large volumes of data.
There are two main types based on their structure:
- Single-Level Index
- Multi-Level Index
1. Single-Level Index
In a single-level index, the index consists of a simple list of key-pointer pairs. Each key in the index corresponds to a block or record in the data file. This index is stored in memory or on disk as a separate file.

Structure:
- Key values are sorted in ascending order.
- Each entry has a pointer to the block or record containing that key.
Characteristics:
- Simple and easy to implement.
- Efficient for small to moderately sized datasets.
- Searching is faster than linear search, often using binary search on the index.
- However, as the data grows, the index file can become large, leading to performance issues.
Example:
Suppose a student table has 10,000 records. A single-level index on student_id would contain sorted student IDs with pointers to the data blocks where records are stored.
2. Multi-Level Index
As the size of the data grows, the single-level index itself can become too large to search efficiently. To handle this, we use multi-level indexing — essentially an index on the index.
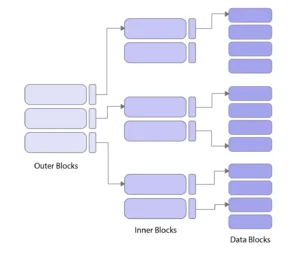
Structure:
- The bottom level is the primary index that points to data blocks.
- The next level up is a secondary index that points to blocks in the primary index.
- This continues up to a level where the index fits in a single block or memory page.
Characteristics:
- Reduces the number of disk accesses needed to find a record.
- Makes searching logarithmic in nature (O(log n)), similar to binary trees.
- More efficient for very large datasets.
- Can be implemented using tree-based structures (like B-Trees, B+ Trees).
Example:
If an index has 1,000 entries and each block can hold 100 entries, a multi-level index will have:
- 10 first-level blocks (each with 100 entries),
- 1 second-level block pointing to the 10 blocks.
Summary Table
| Feature | Single-Level Index | Multi-Level Index |
|---|---|---|
| Structure | One list of key-pointer pairs | Index of indexes (hierarchical) |
| Speed | Moderate (binary search) | Fast (logarithmic search time) |
| Space Requirement | Higher as data grows | Efficient space usage |
| Use Case | Small to medium datasets | Large-scale databases |
| Flexibility | Less flexible | More scalable |
Final Notes
- Both indexing methods aim to reduce disk I/O and improve query performance.
- Most modern databases use multi-level indexing internally, especially using B+ Trees.
- The choice of indexing strategy depends on data size, access pattern, and memory constraints.
