Lossless Decomposition
When we decompose a relation (table) into two or more smaller relations to achieve normalization, our goal is to eliminate redundancy and anomalies without losing any data. A decomposition is called lossless (or non-lossy) if no information is lost during this process and we can reconstruct the original relation exactly by joining the decomposed tables.
Why Do We Need Decomposition?
- To remove data redundancy
- To avoid update, insertion, and deletion anomalies
- To achieve higher normal forms (like 2NF, 3NF, BCNF)
But it’s important that after decomposition, the original data can still be perfectly recovered. That’s where lossless decomposition comes in.
What is Lossless Decomposition?
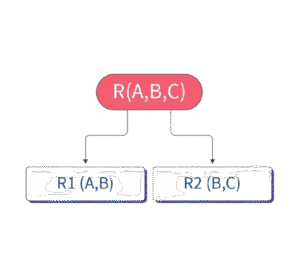
A decomposition of relation R into R1 and R2 is lossless if:
When we join
R1andR2, we get back exactly the same rows as inR, without any extra or missing tuples.
This ensures the meaning and completeness of the original data is preserved.
How to Check for Lossless Join (Informally)
A decomposition of relation R into R1 and R2 is lossless if:
The common attributes between
R1andR2form a super key in at least one of the relations.
This rule helps ensure the join doesn’t introduce any incorrect combinations of data.
What is a Lossy Decomposition?
If the join of the decomposed relations does not produce the exact original relation, then it is lossy.
