Sharding & Replication (Basics)
In distributed database systems, sharding and replication are two key techniques used to scale the database horizontally and improve reliability and performance. Though they serve different purposes, they often work together in large-scale systems to ensure data is both accessible and safe across multiple nodes.
Replication
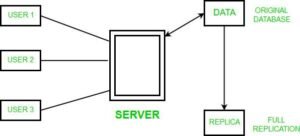
Replication is the process of creating copies of the same data on multiple servers or nodes.
Purpose:
- High availability: If one node fails, data is still available from another.
- Fault tolerance: Data can survive hardware or network failures.
- Read scalability: Multiple replicas can handle more read requests.
Types of Replication:
Master-Slave Replication:
- One node (master) handles writes.
- Other nodes (slaves) replicate data and handle reads.
- Changes are propagated from master to slaves.
Multi-Master Replication:
- Multiple nodes can read and write.
- Requires conflict resolution when concurrent writes happen.
Synchronous vs. Asynchronous:
- Synchronous: All replicas update together (stronger consistency).
- Asynchronous: Updates happen with some delay (better performance).
Example:
In MongoDB, replica sets are a form of replication. One primary handles writes, while secondaries replicate the data and can serve reads.
Sharding
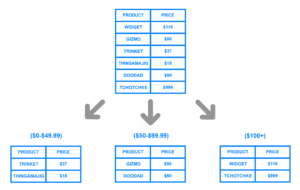
Sharding is the process of splitting a large database into smaller, manageable pieces called shards, each hosted on a different server or node.
Purpose:
- Scalability: Spread data and load across many machines.
- Write performance: Each shard handles a subset of data, reducing load on any single node.
- Efficient storage: Only part of the data resides on any given node.
How Sharding Works:
- A shard key determines how data is partitioned.
- Common sharding strategies:
- Range-based: Divide data by value ranges (e.g., user IDs 1–1000, 1001–2000).
- Hash-based: Use a hash of the key to assign data to shards.
- Geo-based or custom logic: For region-based applications.
Example:
In a shopping platform with millions of users, users can be split across shards based on user ID. Each shard only handles the data for a subset of users.
Combining Replication and Sharding
- Sharding divides the data across multiple nodes.
- Replication ensures each shard is fault-tolerant by copying its data to backup nodes.
- Together, they allow systems like Google Spanner, MongoDB, or Cassandra to scale while staying reliable.
