Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Docker and Kubernetes Interview Questions for Deployment Engineers
Are you preparing for a deployment engineer interview that focuses on Docker and Kubernetes? Look no further! In this comprehensive guide, we’ll dive into 30 high-quality, in-depth interview questions commonly asked in such roles, complete with detailed answers to help you shine. Whether you’re new to these technologies or a seasoned professional, this post will equip you with the knowledge to succeed. To further boost your skills, sign up for our free courses and stay updated with the latest in tech. Sign up here!
Introduction
Docker and Kubernetes are transformative technologies in modern software deployment. Docker enables developers to package applications and their dependencies into portable containers, ensuring consistency across environments. Kubernetes, an open-source orchestration platform, automates the deployment, scaling, and management of these containers, making it ideal for large-scale, high-availability applications. For deployment engineers, mastering these tools is critical, as they form the backbone of modern DevOps practices.
This blog post provides 30 carefully selected Docker and Kubernetes interview questions, tailored for deployment engineers. Each question is accompanied by an in-depth answer, covering core concepts, practical applications, and best practices. We’ve also included actionable advice to help you prepare effectively. Whether you’re aiming to understand container orchestration or troubleshoot complex issues, this guide has you covered. For a deeper dive into related topics, explore our Web Development course.
Section 1: Understanding Docker and Kubernetes
1. What is Docker and how does it relate to Kubernetes?
Answer: Docker is an open-source platform that packages applications and their dependencies into containers—lightweight, portable units that run consistently across different environments. Containers include the application code, runtime, libraries, and system tools, ensuring reliability from development to production.
Kubernetes is an open-source platform for orchestrating containers. It automates tasks like deployment, scaling, and load balancing across a cluster of machines. Docker creates the containers, while Kubernetes manages them at scale, ensuring high availability and efficient resource use.
Example: You might use Docker to build a container image for a web application, then deploy it using Kubernetes to manage multiple instances across a cluster. For more on Docker, check out our Web Development course.
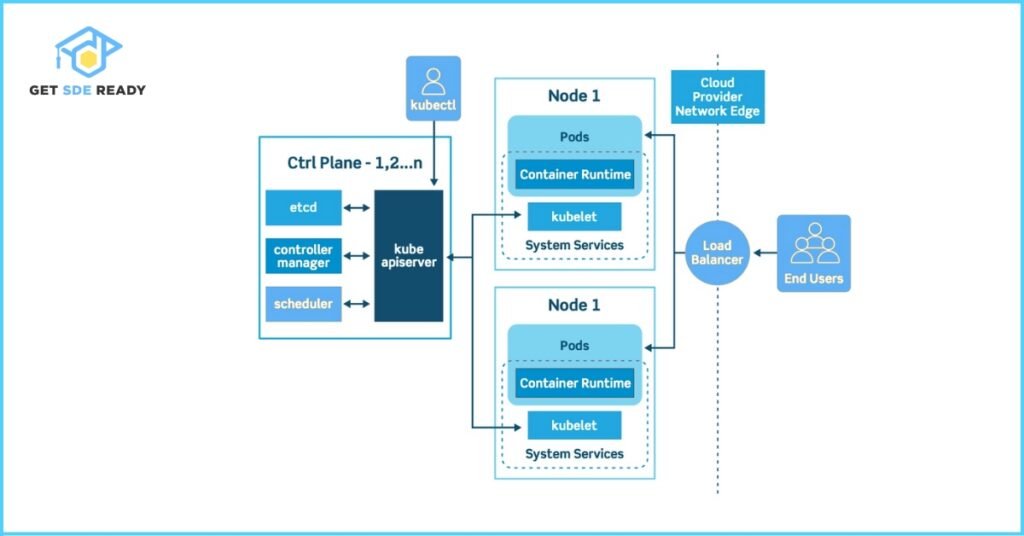
2. What are the main components of Kubernetes architecture?
Answer: Kubernetes architecture consists of a control plane (master node) and worker nodes, each with specific components:
- Control Plane (Master Node):
- API Server: Exposes the Kubernetes API for cluster management.
- Scheduler: Assigns pods to nodes based on resource needs and constraints.
- Controller Manager: Runs controllers (e.g., Node Controller, Job Controller) to maintain the desired state.
- etcd: A distributed key-value store for cluster configuration data.
- Worker Nodes:
- Kubelet: Ensures containers in pods are running as expected.
- Kube-Proxy: Manages network rules for pod communication and load balancing.
- Pods: The smallest deployable units, containing one or more containers.
- Services: Provide stable endpoints for accessing pods.
- Deployments: Manage pod scaling and updates.
For a deeper understanding of system design, explore our Master DSA, Web Dev, System Design course.
3. How is Kubernetes different from Docker Swarm?
Answer: Kubernetes and Docker Swarm are both container orchestration tools, but they differ in complexity and features:
- Setup: Docker Swarm is simpler to set up, ideal for smaller deployments. Kubernetes is more complex but suited for enterprise-scale applications.
- Scaling: Kubernetes offers advanced autoscaling (e.g., Horizontal Pod Autoscaler), while Docker Swarm supports basic scaling.
- Load Balancing: Kubernetes provides robust load balancing via services and Ingress, while Docker Swarm’s load balancing is less flexible.
- Monitoring: Kubernetes integrates with tools like Prometheus, while Docker Swarm relies on third-party solutions.
Use Case: Choose Kubernetes for large, complex deployments; opt for Docker Swarm for simpler setups.
Section 2: Core Concepts in Kubernetes
4. What is a pod in Kubernetes?
Answer: A pod is the smallest deployable unit in Kubernetes, representing a single instance of a running process. It can contain one or more containers that share the same network namespace (e.g., localhost communication) and storage volumes. Pods are ephemeral, meaning they can be created or terminated as needed.
Example: A pod might include a web server container and a logging sidecar container, sharing the same network and storage.
5. What is a Namespace in Kubernetes?
Answer: A namespace divides cluster resources among users or teams, preventing name conflicts and enabling resource isolation. It’s like a virtual cluster within a physical cluster.
Default Namespaces:
- default: For resources without a specified namespace.
- kube-system: For system components (e.g., kube-dns).
- kube-public: For publicly accessible resources (rarely used).
Use Case: Create namespaces like “dev” or “prod” for different environments.
6. What are the different types of services in Kubernetes?
Answer: Kubernetes services provide stable endpoints for accessing pods. The main types are:
- ClusterIP: Exposes the service on an internal IP (default).
- NodePort: Exposes the service on each node’s IP at a static port (30000–32767).
- LoadBalancer: Exposes the service externally via a cloud provider’s load balancer.
- ExternalName: Maps the service to an external DNS name.
Example: Use ClusterIP for internal pod communication and LoadBalancer for public-facing APIs.
Section 3: Deployment and Scaling
7. How does Kubernetes handle load balancing?
Answer: Kubernetes uses services to distribute traffic to pods matching a selector (e.g., app: myapp). The kube-proxy component on each node manages network rules to route traffic. For external traffic, the LoadBalancer service type integrates with cloud providers to provision a load balancer.
Example: A service with selector: app: myapp routes traffic to all pods labeled app: myapp.
8. What is the difference between a deployment and a statefulset?
Answer:
- Deployment: Manages stateless applications (e.g., web servers). Pods are interchangeable, and scaling or updates don’t require persistent identities.
- StatefulSet: Manages stateful applications (e.g., databases). Each pod has a unique, stable identity (e.g., mysql-0, mysql-1) and persistent storage.
Use Case: Use deployments for APIs, StatefulSets for databases like MySQL.
9. How does Kubernetes handle persistent storage?
Answer: Kubernetes uses Persistent Volumes (PVs) and Persistent Volume Claims (PVCs):
- PV: A piece of storage provisioned by an administrator (e.g., NFS, cloud storage).
- PVC: A user’s request for storage, bound to a PV.
Workflow:
- Administrator creates a PV with specific attributes (e.g., size, access mode).
- User creates a PVC to request storage.
- Kubernetes binds the PVC to a suitable PV.
- The PVC is mounted as a volume in a pod.
Example: A database pod uses a PVC to mount a 10GB PV for data storage.
Section 4: Configuration and Secrets
10. What is a ConfigMap and how is it used?
Answer: A ConfigMap stores non-sensitive configuration data in key-value pairs, decoupling configuration from application code.
Use Cases:
- Store environment variables (e.g., DB_HOST=localhost).
- Mount configuration files into pods.
Example:
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
data:
DB_HOST: "localhost"
DB_PORT: "5432"
This ConfigMap can be used as environment variables or mounted as a volume.
11. What is a Secret and how is it different from a ConfigMap?
Answer: A Secret stores sensitive data (e.g., passwords, tokens) and is encrypted at rest and in transit. Unlike ConfigMaps, Secrets are base64-encoded and designed for security.
Key Differences:
- ConfigMaps: Non-sensitive data (e.g., app settings).
- Secrets: Sensitive data (e.g., API keys).
Example:
apiVersion: v1
kind: Secret
metadata:
name: db-secret
type: Opaque
data:
DB_PASSWORD: "cGFzc3dvcmQxMjM=" # base64-encoded
Section 5: Maintenance and Troubleshooting
12. How do you perform maintenance on a Kubernetes node?
Answer:
- Cordon: Run kubectl cordon <node-name> to mark the node as unschedulable.
- Drain: Run kubectl drain <node-name> –ignore-daemonsets to evict pods.
- Perform Maintenance: Update the node (e.g., apply patches).
- Uncordon: Run kubectl uncordon <node-name> to make the node schedulable again.
This ensures minimal disruption, as pods are rescheduled to other nodes.
13. How do you monitor a Kubernetes cluster?
Answer: Monitoring tools like Prometheus, Grafana, and ELK Stack are commonly used:
- Prometheus: Collects metrics from pods, nodes, and services.
- Grafana: Visualizes metrics via dashboards.
- ELK Stack: Aggregates and analyzes logs.
Setup:
- Deploy Prometheus and Grafana as pods.
- Configure Prometheus to scrape application metrics.
- Use Grafana for real-time dashboards.
For more on monitoring, explore our Data Science course.
14. What security measures should be taken in Kubernetes?
Answer:
- RBAC: Use Role-Based Access Control to limit permissions.
- Secrets: Encrypt sensitive data.
- Network Policies: Restrict pod-to-pod traffic.
- Updates: Regularly patch Kubernetes components.
- Audit Logging: Track cluster changes.
Example: Define a network policy to allow traffic only from specific pods.
15. How do you scale an application in Kubernetes?
Answer: Kubernetes supports:
- Horizontal Scaling: Increase pod replicas using kubectl scale deployment <name> –replicas=<number>.
- Vertical Scaling: Adjust pod resources (CPU, memory) via resources in the pod spec.
- Horizontal Pod Autoscaler (HPA): Automatically scales based on metrics like CPU usage.
HPA Example:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
spec:
scaleTargetRef:
kind: Deployment
name: myapp
minReplicas: 2
maxReplicas: 10
targetCPUUtilizationPercentage: 80
16. What is a Horizontal Pod Autoscaler (HPA)?
Answer: HPA automatically adjusts the number of pod replicas based on metrics like CPU or memory usage.
How It Works:
- Monitors metrics via the Metrics Server.
- Scales pods between minReplicas and maxReplicas based on a target (e.g., 80% CPU).
Example: If CPU usage exceeds 80%, HPA adds more pods.
17. How do you perform a rolling update with zero downtime in Kubernetes?
Answer: Kubernetes deployments support rolling updates, creating new pods before terminating old ones.
Steps:
- Update the deployment’s container image: kubectl set image deployment/<name> <container>=<new-image>.
- Monitor rollout: kubectl rollout status deployment/<name>.
- Roll back if needed: kubectl rollout undo deployment/<name>.
Example:
apiVersion: apps/v1
kind: Deployment
spec:
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
This ensures zero downtime by keeping at least one pod available.
18. What is a Pod Disruption Budget (PDB)?
Answer: A PDB ensures a minimum number of pods remain available during voluntary disruptions (e.g., node maintenance).
Example:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: myapp-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: myapp
This guarantees at least two myapp pods are running.
19. How do you debug a pod that is not starting?
Answer:
- Check Pod Status: kubectl get pods to see if it’s in Pending, CrashLoopBackOff, etc.
- View Events: kubectl describe pod <name> for scheduling or resource issues.
- Inspect Logs: kubectl logs <name> for application errors.
- Check Resources: Ensure sufficient CPU/memory.
- Verify Config: Check for errors in YAML (e.g., wrong image).
Example: A CrashLoopBackOff might indicate a misconfigured container.
20. What is the role of Kubelet and Kube-proxy?
Answer:
- Kubelet: Runs on each node, communicates with the API server, and ensures containers in pods are running.
- Kube-proxy: Manages network rules for pod communication and load balancing.
Example: Kubelet restarts a failed container, while Kube-proxy routes traffic to a service’s pods.
21. What is etcd and why is it important in Kubernetes?
Answer: etcd is a distributed key-value store that holds the cluster’s configuration data, such as pod states and service definitions. It’s critical for the control plane to maintain the desired state.
Importance:
- Ensures consistency across the cluster.
- Stores all API objects.
Best Practice: Back up etcd regularly to prevent data loss.
22. How does Kubernetes handle service discovery?
Answer: Kubernetes uses services to provide stable endpoints for pods. Each service has a DNS name, and pods can discover it via DNS or environment variables.
Example: A service named myapp is accessible as myapp.default.svc.cluster.local.
23. What is an Ingress and how does it work?
Answer: Ingress manages external access to services, providing load balancing, SSL termination, and name-based virtual hosting.
How It Works:
- An Ingress controller (e.g., NGINX) processes Ingress rules.
- Routes traffic based on host or path (e.g., example.com/api).
Example:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myapp-ingress
spec:
rules:
- host: example.com
http:
paths:
- path: /api
pathType: Prefix
backend:
service:
name: myapp
port:
number: 80
24. How do you manage resource usage for pods?
Answer: Use requests and limits in the pod spec:
- Requests: Minimum resources (CPU, memory) a pod needs.
- Limits: Maximum resources a pod can use.
Example:
apiVersion: v1
kind: Pod
metadata:
name: myapp
spec:
containers:
- name: myapp
image: myapp:latest
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
25. What is the difference between a Job and a CronJob in Kubernetes?
Answer:
- Job: Runs a task to completion (e.g., a batch process).
- CronJob: Schedules Jobs to run at specific times or intervals.
Example:
apiVersion: batch/v1
kind: CronJob
metadata:
name: my-cronjob
spec:
schedule: "*/5 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: my-task
image: my-task:latest
26. How do you use taints and tolerations in Kubernetes?
Answer: Taints mark nodes to repel pods unless they have matching tolerations.
Example:
Taint a node: kubectl taint nodes <node-name> key=value:NoSchedule.
Add toleration to a pod:
spec:
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
Use Case: Reserve nodes for specific workloads.
27. What is a DaemonSet and when would you use it?
Answer: A DaemonSet ensures a pod runs on every node in the cluster (or a subset).
Use Cases:
- Logging agents (e.g., Fluentd).
- Monitoring agents (e.g., Prometheus Node Exporter).
Example:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
containers:
- name: fluentd
image: fluentd:latest
28. How do you backup and restore Kubernetes resources?
Answer:
- Backup: Use tools like Velero to back up cluster resources and persistent volumes.
- Restore: Restore backups to a new or existing cluster using Velero.
Steps:
- Install Velero with a backup storage provider (e.g., AWS S3).
- Run velero backup create <name> to back up resources.
- Run velero restore create <name> –from-backup <backup-name> to restore.
29. What are the best practices for securing Kubernetes clusters?
Answer:
- RBAC: Define granular roles and bindings.
- Secrets: Use encrypted Secrets for sensitive data.
- Network Policies: Restrict pod communication.
- Pod Security Policies: Enforce security standards.
- Regular Updates: Patch Kubernetes components.
- Audit Logging: Monitor cluster activity.
For advanced security practices, check our Data Science course.
30. How do you troubleshoot networking issues in Kubernetes?
Answer:
- Check Service: Verify service selectors match pod labels (kubectl describe service <name>).
- Inspect Kube-Proxy: Ensure it’s running (kubectl get pods -n kube-system).
- Test Connectivity: Use kubectl exec to ping or curl endpoints.
- Check Network Policies: Ensure policies allow traffic.
- Review Logs: Check pod and kube-proxy logs for errors.
Example: If pods can’t communicate, verify DNS resolution with nslookup myapp.default.svc.cluster.local.
Conclusion
Mastering Docker and Kubernetes is essential for deployment engineers aiming to excel in modern DevOps roles. This guide covers key concepts, practical scenarios, and best practices to help you prepare for interviews. Practice hands-on with tools like kubectl and explore real-world projects to solidify your skills. For a quick boost, try our Crash Course to accelerate your learning.
FAQs
What is the primary difference between Docker and Kubernetes?
Docker builds and runs containers, while Kubernetes orchestrates them for scalability and reliability.
How does Kubernetes ensure high availability of applications?
Kubernetes uses replication, self-healing, and load balancing to ensure applications remain available.
What is a StatefulSet and when should it be used?
StatefulSets manage stateful applications, providing unique identities and persistent storage for pods.
How can you secure a Kubernetes cluster?
Use RBAC, network policies, Secrets, and regular updates to secure clusters.
What is the role of Ingress in Kubernetes?
Ingress manages external access, offering load balancing, SSL, and virtual hosting.

DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 60% OFF
₹25,000.00 ₹9,999.00
Accelerate your Path to a Product based Career
Boost your career or get hired at top product-based companies by joining our expertly crafted courses. Gain practical skills and real-world knowledge to help you succeed.

Low & High Level System Design
- 20+ Live Classes & Recordings
- 24*7 Live Doubt Support
- Case Studies
- Comprehensive Notes
- HackerRank Tests
- Topic-wise Quizzes
- Access to Global Peer Community
- Interview Prep Material
Buy for 65% OFF
₹20,000.00 ₹6,999.00

Fast-Track to Full Spectrum Software Engineering
- 120+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- 12+ live Projects & Deployments
- Case Studies
- Access to Global Peer Community
Buy for 57% OFF
₹35,000.00 ₹14,999.00
DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 60% OFF
₹25,000.00 ₹9,999.00
Design Patterns Bootcamp
- Live Classes & Recordings
- 24/7 Live Doubt Support
- Practice Questions
- Case Studies
- Access to Global Peer Community
- Topic wise Quizzes
- Referrals
- Certificate of Completion
Buy for 50% OFF
₹2,000.00 ₹999.00

LLD Bootcamp
- 7+ Live Classes & Recordings
- Practice Questions
- 24/7 Live Doubt Support
- Case Studies
- Topic wise Quizzes
- Access to Global Peer Community
- Certificate of Completion
- Referrals
Buy for 50% OFF
₹2,000.00 ₹999.00

Essentials of Machine Learning and Artificial Intelligence
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 22+ Hands-on Live Projects & Deployments
- Comprehensive Notes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
- Interview Prep Material
Buy for 65% OFF
₹20,000.00 ₹6,999.00
Reach Out Now
If you have any queries, please fill out this form. We will surely reach out to you.
Contact Email
Reach us at the following email address.
arun@getsdeready.com
Phone Number
You can reach us by phone as well.
+91-97737 28034
Our Location
Rohini, Sector-3, Delhi-110085
