Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Handling Pagination in APIs: Common Web Interview Questions
Introduction to Pagination in APIs
Pagination is a cornerstone of efficient API design, particularly when handling large datasets. It involves dividing extensive data into smaller, manageable chunks or “pages” that clients can request incrementally. This approach is critical in web applications, where sending thousands of records in a single response can overwhelm servers, slow down performance, and frustrate users. By delivering data in smaller portions, pagination ensures faster response times, reduced server load, and a smoother user experience.
For example, imagine an e-commerce API returning a list of products. Without pagination, a request for all products could return thousands of items, causing delays. With pagination, the API might return 10 products per page, allowing the client to request additional pages as needed. This not only improves performance but also makes the data easier to navigate.
If you’re interested in learning more about effective web development strategies, check out this free course to improve your skills.
Why is Pagination Important?
Pagination is essential for several reasons, each contributing to the overall efficiency and usability of an API:
- Performance Optimization: Fetching large datasets in one go can strain both the server and the client. Pagination reduces the amount of data transferred, leading to faster response times and lower resource consumption. According to Nordic APIs, 53% of web users abandon a page if it takes more than 3 seconds to load, underscoring the need for efficient data handling.
- Enhanced User Experience: For end-users, pagination makes data more digestible. Features like “next page” or “load more” buttons allow users to navigate large datasets intuitively, whether in a web app or mobile interface.
- Scalability: As datasets grow, APIs must handle requests efficiently. Pagination enables APIs to scale by limiting the data processed in each request, making them suitable for applications with millions of records.
- Resource Management: By reducing the data sent in each response, pagination conserves bandwidth and server resources, which is critical for cost-effective and sustainable API operations.
Common Techniques for Implementing Pagination
APIs employ several pagination techniques, each suited to different use cases. Below are the five most common methods, along with their advantages and drawbacks:
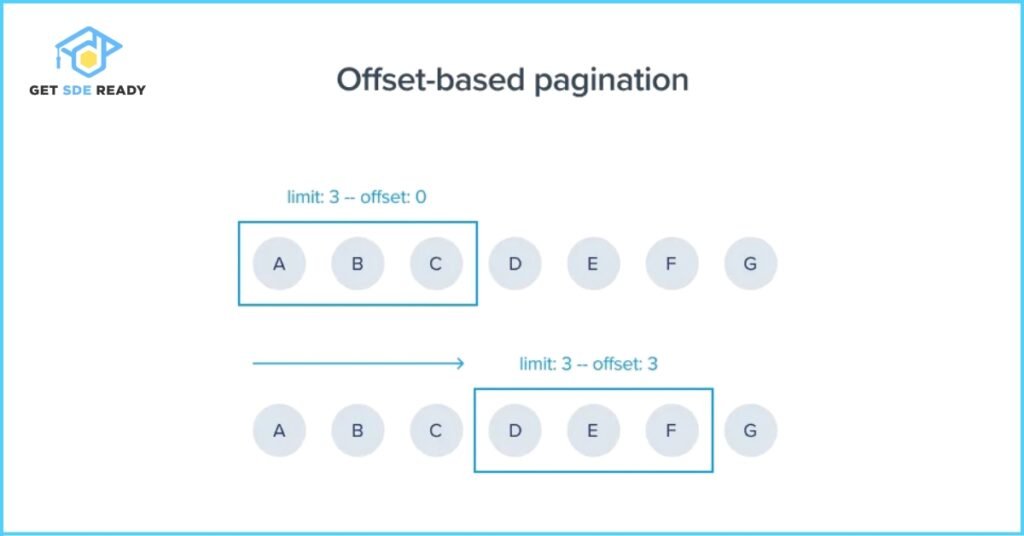
1. Offset-based Pagination
- Description: This method uses offset (the starting point in the dataset) and limit (the number of items to return) as query parameters.
- Example: A request like /api/tasks?offset=10&limit=10 returns items 11 through 20.
- Pros:
- Simple to implement, especially for SQL-based databases.
- Intuitive for developers and users familiar with page numbers.
- Cons:
- Inefficient for large datasets, as databases must scan all preceding records to reach the offset.
- Can lead to missing or duplicated data if the dataset changes (e.g., records are added or deleted).
2. Cursor-based Pagination
- Description: This method uses a unique identifier, or “cursor,” to mark the position in the dataset. The cursor is typically an opaque token or a field like an ID or timestamp.
- Example: A request like /api/tasks?cursor=abc123 returns the next set of items after the record with the cursor abc123.
- Pros:
- More efficient for large or dynamic datasets, as it avoids scanning unnecessary records.
- Ensures consistent results even if the dataset changes.
- Cons:
- More complex to implement, as the API must generate and manage cursors.
- Less intuitive for direct page access (e.g., jumping to page 10).
3. Page-based Pagination
- Description: This method uses page (the page number) and pageSize (the number of items per page) to define the data subset.
- Example: A request like /api/tasks?page=2&pageSize=10 returns the second page of 10 items.
- Pros:
- User-friendly and intuitive, especially for web interfaces.
- Easy to implement for static datasets.
- Cons:
- Similar to offset-based pagination, it can be inefficient for large datasets.
- Susceptible to missing or duplicated data if records are added or deleted.
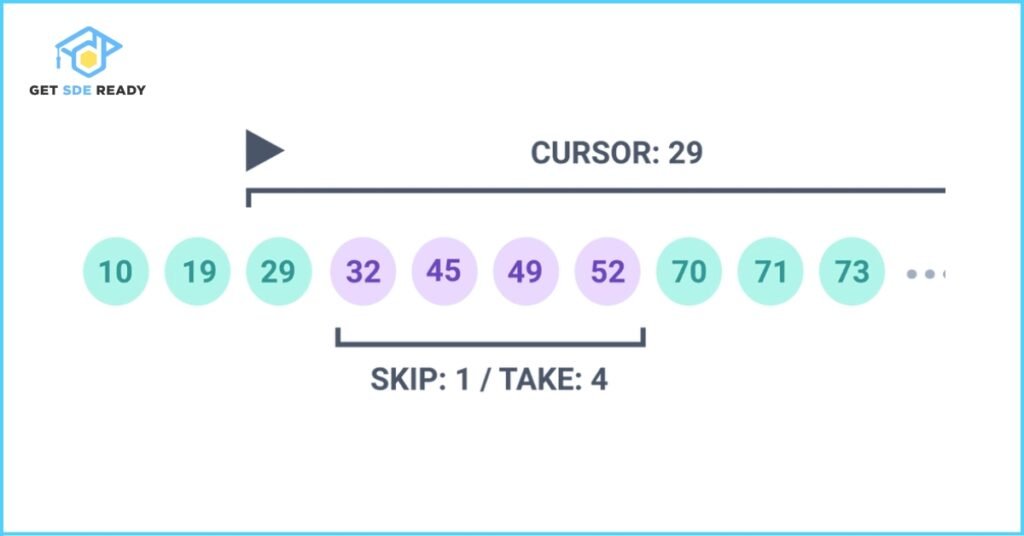
4. Keyset Pagination
- Description: This method uses a unique, sequentially ordered field (e.g., timestamp, ID) for pagination.
- Example: GET /api/events?since_id=12345&limit=10
- Pros:
- Consistent performance and replicable results for large or fast-changing datasets.
- Cons:
- Unsuitable for non-sequential data, hard to skip to random pages.
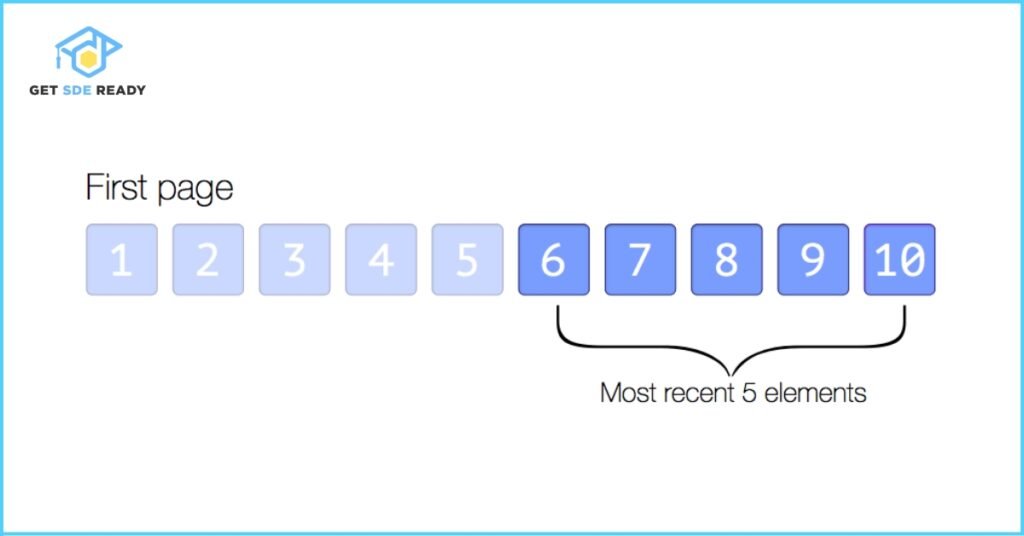
5. Time-based Pagination
- Description: Segments data by timestamps, useful for analytics or log systems.
- Example: GET /api/logs?from=2023-01-01&to=2023-01-31
- Pros:
- Precise data access within time windows, crucial for trend analysis.
- Cons:
- May not be suitable for all types of data.
For a deeper dive into these methods, refer to Merge’s Guide to REST API Pagination.
Best Practices for Handling Pagination in APIs
To design effective and scalable paginated APIs, developers should follow these best practices:
- Consistent Parameter Names: Use standard parameter names like page, pageSize, offset, limit, or cursor across all endpoints to ensure a consistent developer experience.
- Include Pagination Metadata: Provide metadata in the response to help clients navigate the dataset. Common metadata includes:
- Total number of items
- Current page or offset
- Total number of pages
- Links to the next and previous pages
Example response:
{
"data": [...],
"pagination": {
"totalItems": 100,
"currentPage": 1,
"totalPages": 10,
"nextPage": "/api/tasks?page=2",
"previousPage": null
}
}
- Set Reasonable Defaults: Provide default values for pagination parameters (e.g., page=1, limit=10) to simplify client requests and prevent excessive data retrieval.
- Validate Inputs: Handle invalid inputs (e.g., negative offsets or zero limits) gracefully by returning clear error messages, such as HTTP 400 Bad Request with a descriptive response body.
- Choose the Right Method: For large or frequently updated datasets, prefer cursor-based pagination for better performance. For smaller, static datasets, page-based or offset-based pagination may suffice.
- Implement Caching: Use caching strategies to store frequently accessed paginated responses, reducing server load. Learn more about caching in Postman’s Caching Guide.
- Document Clearly: Provide comprehensive documentation with examples of paginated requests and responses. Good documentation is critical for API usability, as noted in Hirist’s REST API Interview Questions.
Common Interview Questions on Pagination in APIs
Pagination is a frequent topic in web development interviews, particularly for backend and API design roles. Below are 30 in-depth, relevant questions that are commonly asked in technical interviews, along with detailed answers to help you prepare. These questions go beyond generic inquiries, focusing on real-world scenarios and practical challenges.
1. What is the primary purpose of pagination in APIs, and how does it impact performance?
Answer: Pagination divides large datasets into smaller chunks to reduce server load and improve response times. By limiting the data sent per request, it minimizes bandwidth usage and prevents server overload, especially for large datasets. For example, fetching 10 items instead of 10,000 reduces latency, as noted by Nordic APIs, where 53% of users abandon pages taking over 3 seconds to load.
2. How do you decide which pagination method to use for a specific API endpoint?
Answer: The choice depends on dataset size, volatility, and user needs:
- Offset-based: Best for small, static datasets due to simplicity.
- Cursor-based: Ideal for large or dynamic datasets for efficiency and consistency.
- Page-based: Suitable for user-friendly web interfaces with small datasets.
- Keyset: Effective for sequentially ordered data.
- Time-based: Useful for time-sensitive data like logs. Evaluate performance requirements and data change frequency to select the optimal method.
3. How do you implement offset-based pagination in a REST API using Spring?
Answer: In Spring, use Pageable and Page from Spring Data. Example:
@GetMapping("/items")
public Page<Item> getItems(Pageable pageable) {
return itemRepository.findAll(pageable);
}
This leverages PagingAndSortingRepository to handle pagination, returning a Page object with data and metadata (e.g., total items, pages). See Baeldung’s REST Pagination Guide.
4. What are the challenges of using offset-based pagination with large datasets, and how can they be mitigated?
Answer: Offset-based pagination is inefficient for large datasets because databases scan all preceding records (e.g., OFFSET 1000000 scans 1M records). This causes performance degradation. Mitigation includes:
- Using cursor-based or keyset pagination for better efficiency.
- Caching frequent queries.
- Limiting maximum offset values to prevent deep pagination.
5. How does cursor-based pagination ensure data consistency in dynamic datasets?
Answer: Cursor-based pagination uses a unique identifier (e.g., ID, timestamp) to mark the dataset position, avoiding issues like missing or duplicated data when records are added or deleted. For example, if item #10 is deleted, the cursor points to the next valid item, ensuring consistency, unlike offset-based pagination.
6. How do you handle pagination when the dataset is sorted or filtered?
Answer: Apply sorting (e.g., sort_by=created_at) and filtering (e.g., category=books) before pagination to ensure consistent results. For example:
@GetMapping("/items")
public Page<Item> getItems(@RequestParam String category, Pageable pageable) {
return itemRepository.findByCategory(category, pageable);
}
This ensures only filtered and sorted data is paginated, maintaining order across pages.
7. What metadata should be included in a paginated API response, and why?
Answer: Metadata should include:
- Total items (e.g., totalItems: 100)
- Current page or offset (e.g., currentPage: 1)
- Total pages (e.g., totalPages: 10)
- Navigation links (e.g., nextPage: “/api/tasks?page=2”)
This helps clients navigate datasets efficiently and understand the data structure, as recommended by Moesif’s API Design Guide.
8. How do you handle invalid pagination parameters, such as negative offsets or zero limits?
Answer: Validate inputs and return a 400 Bad Request with a descriptive error message. Example in Python Flask:
@app.route('/tasks', methods=['GET'])
def get_tasks():
offset = request.args.get('offset', 0, type=int)
limit = request.args.get('limit', 10, type=int)
if offset < 0 or limit <= 0:
return jsonify({"error": "Invalid offset or limit"}), 400
# Process request
9. What are the performance implications of allowing large page sizes in pagination?
Answer: Large page sizes negate pagination benefits, increasing server load and response times. Mitigate by:
- Setting a maximum page size (e.g., 100 items).
- Using default page sizes (e.g., 10-50 items).
- Implementing rate limiting to prevent abuse.
10. How do you implement cursor-based pagination in a REST API?
Answer: Use a cursor (e.g., last item’s ID) to fetch the next set. Example in Node.js with Express:
app.get('/tasks', async (req, res) => {
const cursor = req.query.cursor || 0;
const limit = parseInt(req.query.limit) || 10;
const tasks = await db.query('SELECT * FROM tasks WHERE id > ? LIMIT ?', [cursor, limit]);
const nextCursor = tasks.length ? tasks[tasks.length - 1].id : null;
res.json({ data: tasks, pagination: { nextCursor } });
});
This ensures efficient navigation and consistency.
11. How do you test pagination functionality in an API to ensure reliability?
Answer: Write integration tests to verify:
- Correct number of items per page.
- Accurate metadata (e.g., total items, pages).
- Navigation links functionality.
- Edge cases (e.g., empty datasets, invalid inputs).
Example using REST-assured:
given().queryParam("page", 1).queryParam("size", 10)
.when().get("/items")
.then().statusCode(200).body("pagination.totalItems", equalTo(100));
12. How do you handle pagination in GraphQL APIs compared to REST APIs?
Answer: In GraphQL, use connections and edges with first, after, last, and before arguments. Example:
query {
tasks(first: 10, after: "abc123") {
edges { node { id title } cursor }
pageInfo { hasNextPage endCursor }
}
}
Unlike REST’s query parameters, GraphQL uses a structured connection model for pagination.
13. What are the security considerations when implementing pagination in APIs?
Answer: Security considerations include:
- Validating inputs to prevent injection attacks (e.g., SQL injection via offset).
- Limiting page sizes to avoid denial-of-service attacks.
- Avoiding sensitive data exposure in cursors (e.g., encoding cursors securely).
14. How do you ensure pagination stability when data is frequently added or removed?
Answer: Use cursor-based or keyset pagination to maintain consistent ordering, as they rely on unique identifiers rather than offsets, which can shift with data changes.
15. What is the role of caching in optimizing paginated API responses?
Answer: Caching stores frequently accessed paginated responses, reducing database queries. Implement using tools like Redis or Varnish, caching responses by page or cursor. Example:
app = Flask(__name__)
cache = Cache(app, config={'CACHE_TYPE': 'redis'})
@app.route('/tasks')
@cache.cached(timeout=60)
def get_tasks():
# Fetch paginated data
16. How do you handle pagination for real-time data streams in APIs?
Answer: Use cursor-based pagination with timestamps or sequence IDs to handle real-time updates efficiently, ensuring new data is included without disrupting pagination order.
17. What are the trade-offs of allowing clients to specify custom page sizes?
Answer: Pros: Flexibility for clients. Cons: Potential performance issues with large sizes. Mitigate by setting upper limits (e.g., 100 items) and defaults (e.g., 10 items).
18. How do you implement pagination in a REST API with complex data relationships?
Answer: Use cursor-based pagination for consistency and include metadata to clarify relationships. Example:
{
"data": [{ "id": 1, "order": { "id": 101, "items": [...] } }],
"pagination": { "nextCursor": "def456" }
}
19. How do you explain pagination to a non-technical stakeholder?
Answer: Pagination is like dividing a large book into chapters. Instead of reading everything at once, you read one chapter at a time, making it faster and easier to manage.
20. What are real-world examples of APIs with effective pagination strategies?
Answer:
- GitHub API: Uses cursor-based pagination for issues/pull requests.
- Twitter API: Uses cursor-based pagination for timelines.
- Spotify API: Uses offset-based pagination for albums/tracks.
21. How do you handle pagination in APIs with nested resources?
Answer: Paginate the top-level resource and include nested data selectively. Example:
{
"data": [{ "id": 1, "comments": { "data": [...], "pagination": { "nextCursor": "xyz789" } } }],
"pagination": { "nextCursor": "abc123" }
}
22. How do you optimize database queries for pagination in large datasets?
Answer: Use indexed fields for cursor-based or keyset pagination and avoid OFFSET in SQL queries. Example:
SELECT * FROM tasks WHERE id > ? LIMIT 10;
23. What is the impact of pagination on client-side rendering, and how can it be optimized?
Answer: Pagination reduces rendering load by limiting data. Optimize with preloading next pages or infinite scroll using cursor-based pagination.
24. How do you handle pagination in APIs with high-latency databases?
Answer: Use cursor-based pagination and caching to minimize database queries. Index key fields to speed up retrieval.
25. What are the differences between keyset and cursor-based pagination?
Answer: Keyset pagination uses a specific field (e.g., ID), while cursor-based pagination uses an opaque token, offering more flexibility but requiring additional logic.
26. How do you implement time-based pagination for log data?
Answer: Use timestamp ranges. Example:
@app.route('/logs')
def get_logs():
from_time = request.args.get('from')
to_time = request.args.get('to')
logs = db.query('SELECT * FROM logs WHERE timestamp BETWEEN ? AND ?', [from_time, to_time])
return jsonify(logs)
27. How do you handle pagination in APIs with rate limiting?
Answer: Combine pagination with rate limiting to prevent abuse. Example: Limit requests per minute and enforce small page sizes.
28. What are the challenges of implementing pagination in microservices architectures?
Answer: Challenges include data consistency across services and varying pagination methods. Use a standardized approach (e.g., cursor-based) and API gateways for consistency.
29. How do you ensure pagination is SEO-friendly for web APIs?
Answer: Use crawlable links (e.g., <a href=”/api/tasks?page=2″>) and sitemaps, as recommended by Google’s Pagination Best Practices.
30. How do you debug pagination issues in production APIs?
Answer: Monitor logs for query performance, validate metadata accuracy, and test edge cases (e.g., empty pages, large offsets) to identify and resolve issues.
Pagination Methods Comparison
Method | Pros | Cons | Best Use Case |
Offset-based | Simple to implement, intuitive for small datasets | Inefficient for large datasets, risk of missing/duplicated data | Small, static datasets |
Cursor-based | Efficient for large/dynamic datasets, consistent results | Complex implementation, less intuitive for direct page access | Large or frequently updated datasets |
Page-based | User-friendly, easy for static datasets | Inefficient for large datasets, similar issues to offset-based | Web interfaces with small datasets |
Keyset | Consistent performance, good for sequential data | Unsuitable for non-sequential data, hard to skip pages | Large, ordered datasets |
Time-based | Precise for time-sensitive data, good for analytics | Limited to time-based data, less flexible for other use cases | Log or analytics systems |
Conclusion
Mastering pagination in APIs is a critical skill for web developers, particularly for roles involving backend development or API design. By understanding the different pagination methods—offset-based, cursor-based, page-based, keyset, and time-based—and adhering to best practices like consistent parameter naming, metadata inclusion, and input validation, you can build efficient and scalable APIs. Preparing for the 30 in-depth interview questions provided will demonstrate your expertise and readiness for real-world challenges.
For more advanced techniques on optimizing pagination, consider exploring courses on Mastering DSA and Data Science.
FAQs
What is pagination in APIs, and why is it used?
Pagination breaks down large datasets into smaller chunks, improving performance, reducing server load, and enhancing the user experience.
How do I choose the right pagination method for my API?
Select the method based on your dataset’s size and volatility: use offset-based for small static datasets, cursor-based for large or dynamic ones.
What are the main benefits of cursor-based pagination?
Cursor-based pagination ensures consistent results, even when data is added or removed, making it ideal for large, frequently updated datasets.
Can pagination improve API performance?
Yes, by limiting the data sent in each request, pagination reduces the server’s workload and accelerates response times.
How do I handle invalid pagination parameters?
Always validate inputs and return clear error messages (e.g., HTTP 400) if parameters like offsets or limits are incorrect.

DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00
Accelerate your Path to a Product based Career
Boost your career or get hired at top product-based companies by joining our expertly crafted courses. Gain practical skills and real-world knowledge to help you succeed.

Data Analytics
- 20+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 15+ Hands-on Live Projects
- Comprehensive Notes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 70% OFF
₹9,999.00 ₹2,999.00

SDE 360: Master DSA, System Design, AI & Behavioural
- 100+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 50% OFF
₹39,999.00 ₹19,999.00

Fast-Track to Full Spectrum Software Engineering
- 120+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- 12+ live Projects & Deployments
- Case Studies
- Access to Global Peer Community
Buy for 51% OFF
₹35,000.00 ₹16,999.00
DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00

Mastering Mern Stack (WEB DEVELOPMENT)
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 12+ Hands-on Live Projects & Deployments
- Comprehensive Notes & Quizzes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 53% OFF
₹15,000.00 ₹6,999.00

Mastering Data Structures & Algorithms
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests
- Access to Global Peer Community
- Topic-wise Quizzes
- Interview Prep Material
Buy for 40% OFF
₹9,999.00 ₹5,999.00
Reach Out Now
If you have any queries, please fill out this form. We will surely reach out to you.
Contact Email
Reach us at the following email address.
arun@getsdeready.com
Phone Number
You can reach us by phone as well.
+91-97737 28034
Our Location
Rohini, Sector-3, Delhi-110085
