Q1: Design and implement an Excel Spreadsheet
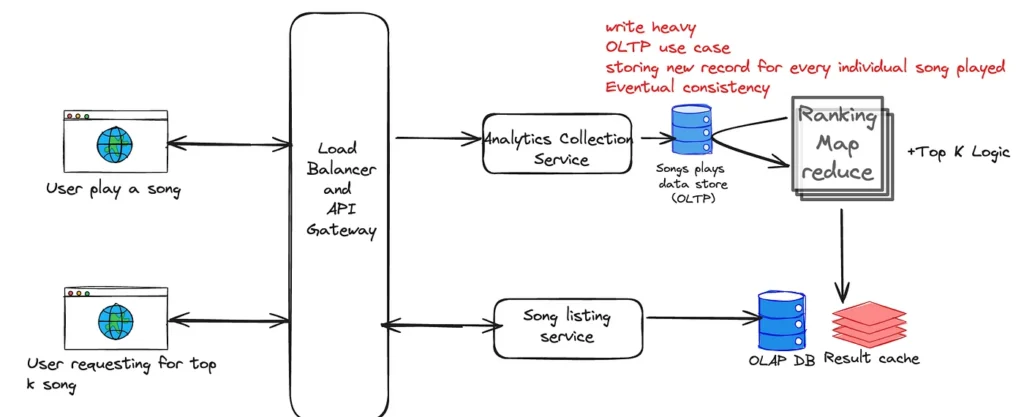
Q2: Problem Statement: Design a Song Play Analytics System
Q3: Add driver and per hour rate.
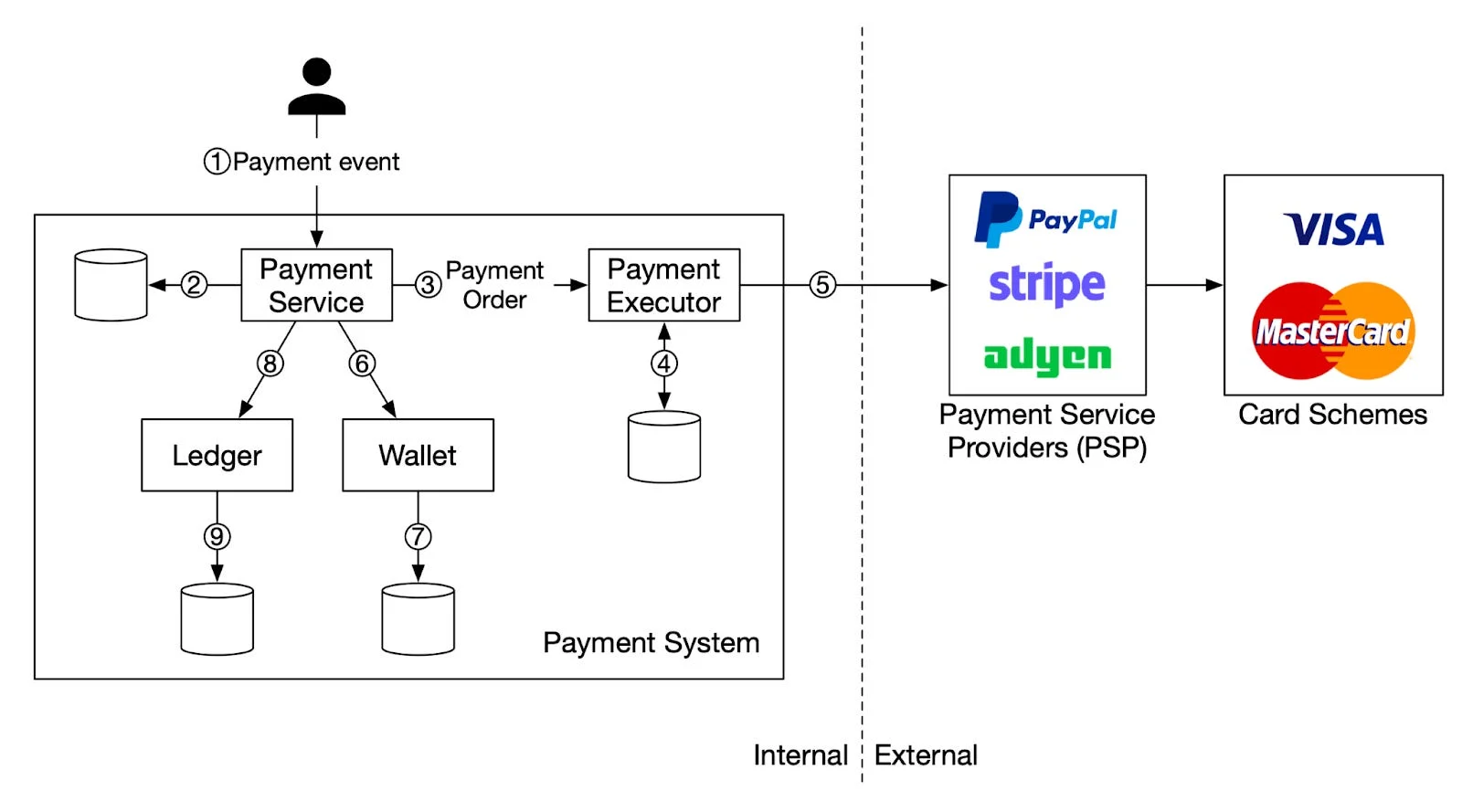
Q4: Design a Driver Payment Management System
Q5: Competing Reactions in an Isothermal Reactor
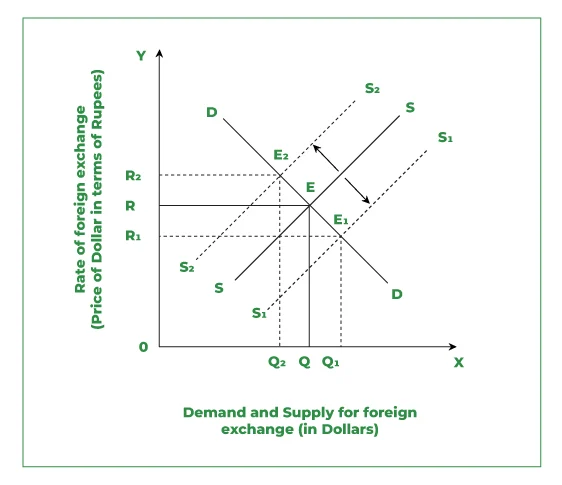
Q6: Currency Conversion Rate Calculation Using Exchange Mappings
Q7: Design a Data Store to execute
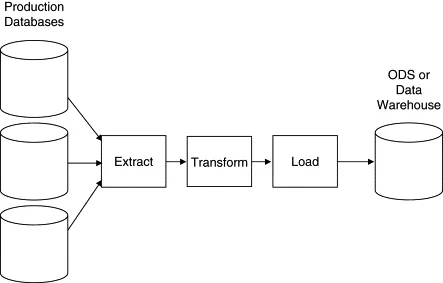
Q8: Design an Event Tracking and Analytics System
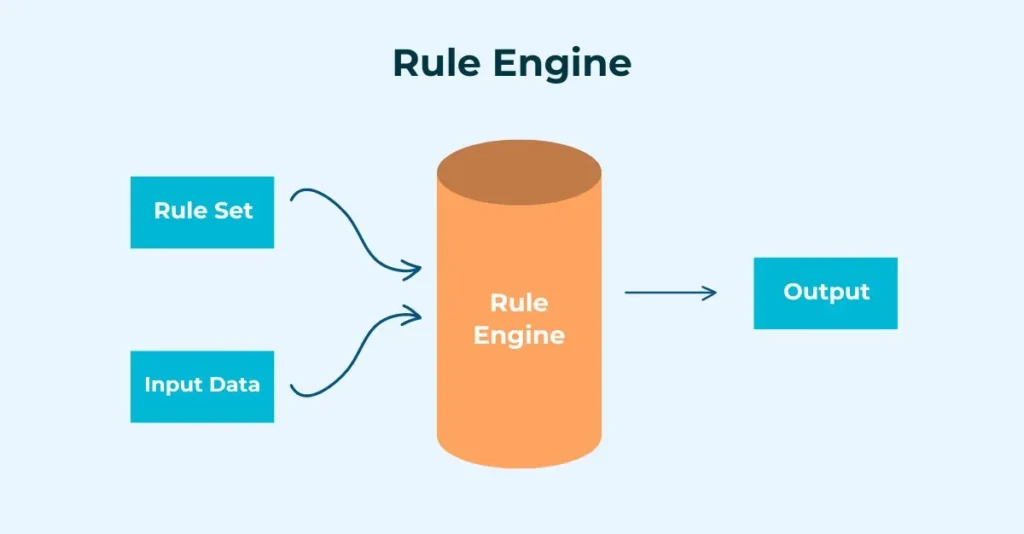
Q9: Expense Policy Rules Engine