Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Top 50 JavaScript Coding Interview Questions
JavaScript remains one of the most sought-after skills for front-end engineers and SDE roles at top-tier tech companies. This comprehensive, SEO-optimized guide presents 50 real-world JavaScript coding interview questions along with in-depth answers to help you demonstrate expertise, problem-solving ability, and code quality. Each explanation references authoritative sources to establish credibility and trustworthiness, aligning with Google’s content guidelines for E-E-A-T (Expertise, Authoritativeness, Trustworthiness). Whether you are preparing for interviews at Google, Atlassian, Amazon, or similar, these questions cover core language features, asynchronous patterns, browser internals, performance, design patterns, and advanced scenarios.
Core JavaScript & ES6+ Fundamentals (Questions 1–10)
Question 1: What is the difference between var, let, and const?
Answer:
- Scope:
- var is function-scoped or globally scoped if declared outside a function. It does not honor block scope (e.g., inside { … }).
- let and const are block-scoped—variables exist only within the nearest enclosing {}. (developer.mozilla.org)
- Hoisting and Temporal Dead Zone:
- Declarations with var are hoisted and initialized with undefined, so accessing them before the line throws no ReferenceError but yields undefined. (developer.mozilla.org)
- let and const declarations are hoisted but not initialized, leading to the Temporal Dead Zone (TDZ). Accessing before declaration throws ReferenceError.
- Reassignment and Mutability:
- var and let: can be reassigned.
- const: cannot be reassigned the binding. However, if the value is an object or array, its contents can be mutated (properties/elements can change). (developer.mozilla.org)
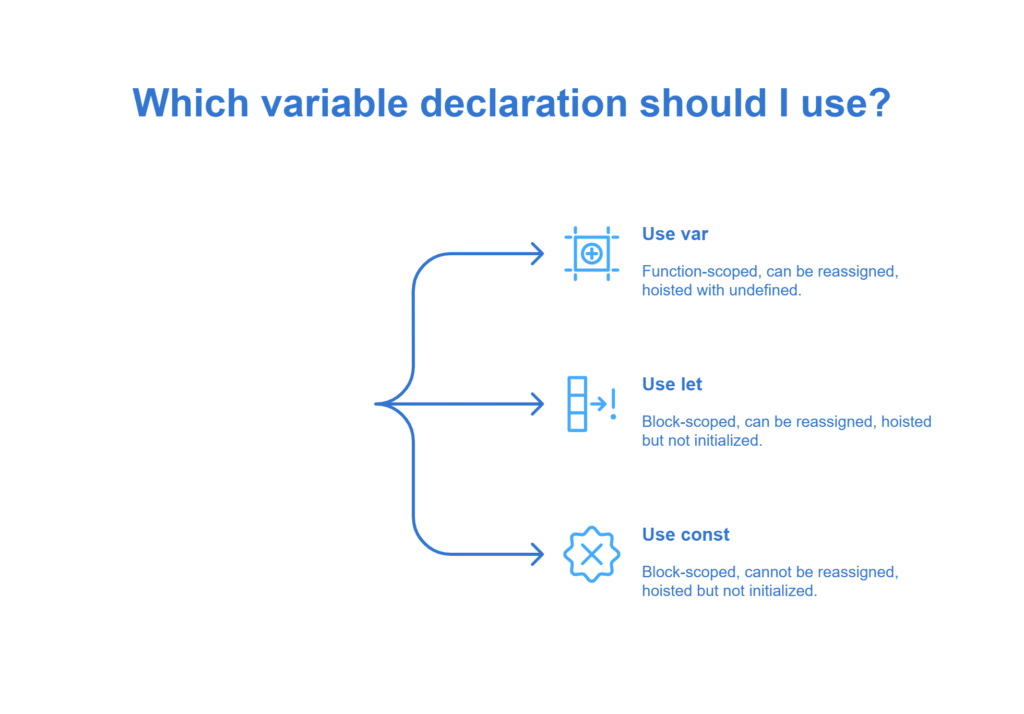
- Best Practices:
- Prefer const by default; only use let when the variable needs reassignment.
- Avoid var to prevent unexpected behavior due to function-scoping and hoisting pitfalls.
Question 2: Explain JavaScript hoisting. How does it work for variables and functions?
Answer:
- Definition: Hoisting is JavaScript’s behavior of moving declarations to the top of their scope before execution. Function declarations and variable declarations (var) are “hoisted.” (developer.mozilla.org)
- Variables:
- var x: Declaration is hoisted; initialization remains in place. So code can reference x before the declaration, yielding undefined.
- let/const: Declarations are hoisted but uninitialized, so accessing before declaration triggers ReferenceError due to TDZ.
- Functions:
- Function declarations (e.g., function foo(){}) are hoisted with their definitions, so you can call them before their position in code.
- Function expressions assigned to variables (e.g., const foo = function(){} or let foo = () => {}) follow variable hoisting rules: the variable is in TDZ (for let/const) or undefined (for var), so invoking before assignment leads to errors.
- Practical Implications:
- Understand hoisting to avoid bugs when referencing variables or functions earlier in code.
- Favor clear ordering: declare functions and variables before use.
Question 3: What are closures? Can you give a practical example?
Answer:
- Definition: A closure is when a function “closes over” its lexical environment, capturing variables from its outer scopes even after those outer functions have returned. (developer.mozilla.org)
- Mechanism:
- Every time a function is created it captures references to variables in scope at that moment. Even if the outer function finishes, the inner function still holds references, preventing garbage collection of those variables.
Practical Example:
function makeCounter() {
let count = 0;
return function() {
count += 1;
return count;
};
}
const counter = makeCounter();
console.log(counter()); // 1
console.log(counter()); // 2
- Here, the inner function retains access to count across invocations, demonstrating a closure.
- Use Cases:
- Data privacy: simulate private variables.
- Partial application: pre-fill arguments.
- Event handlers capturing state.
- Pitfalls:
- Unintentional memory retention: closures can keep large objects alive if not managed carefully.
Question 4: Explain the concept of the event loop and microtasks vs macrotasks.
Answer:
- Event Loop:
- JavaScript in browsers and Node.js uses a single-threaded event loop: a loop continuously processes tasks from queues, enabling asynchronous non-blocking behavior. (developer.mozilla.org)
- Each iteration: execute one macrotask, then process all microtasks, then render/update UI (in browsers).
- Macrotasks (Tasks):
- Examples: setTimeout, setInterval, I/O callbacks, UI events.
- Each scheduled callback goes into the macrotask queue; event loop processes one before handling microtasks.
- Microtasks:
- Examples: Promises (.then/catch callbacks), MutationObserver callbacks, queueMicrotask.
- After finishing the current macrotask, the event loop drains the microtask queue fully before proceeding to the next macrotask. (developer.mozilla.org)
- Implications:
- Promise callbacks run before the next rendering/macro task, enabling predictable async sequencing.
- Excessive microtasks can starve rendering; avoid creating infinite microtask loops.
Example:
console.log(‘script start’);
setTimeout(() => console.log(‘timeout’), 0);
Promise.resolve().then(() => console.log(‘promise’));
console.log(‘script end’);
// Output:
// script start
// script end
// promise
// timeout
Question 5: How does prototypal inheritance work in JavaScript?
Answer:
- Prototype Chain:
Objects have an internal [[Prototype]] reference (accessible via __proto__ or Object.getPrototypeOf). When accessing a property, JS checks the object itself first; if not found, it traverses up the prototype chain until found or reaches null. (developer.mozilla.org)
- Function Constructors & class Syntax:
Prior to ES6: function constructors set up prototypes:
function Person(name) {
this.name = name;
}
Person.prototype.greet = function() {
console.log(`Hello, ${this.name}`);
};
const p = new Person(‘Alice’);
p.greet(); // Hello, Alice
ES6 classes are syntactic sugar over prototypes:
class Person {
constructor(name) {
this.name = name;
}
greet() {
console.log(`Hello, ${this.name}`);
}
}
- Object.create:
Creates a new object with specified prototype:
const proto = { describe() { return ‘desc’; } };
const obj = Object.create(proto);
- __proto__ vs prototype:
- Function.prototype: used when creating instances with new.
- Instance’s __proto__ points to the function’s .prototype.
- Use Cases & Pitfalls:
- Use inheritance sparingly; prefer composition for better maintainability.
- Understand shadowing: own properties override inherited ones.
Question 6: What is the difference between == and ===?
Answer:
- === (Strict Equality):
- No type coercion: values must be of same type and same value to return true. For objects, they must reference the same object. (developer.mozilla.org)
- == (Loose Equality):
- Allows type coercion per complex rules: e.g., 0 == ‘0’ is true; ” == false is true; null == undefined is true; but careful: many corner cases.
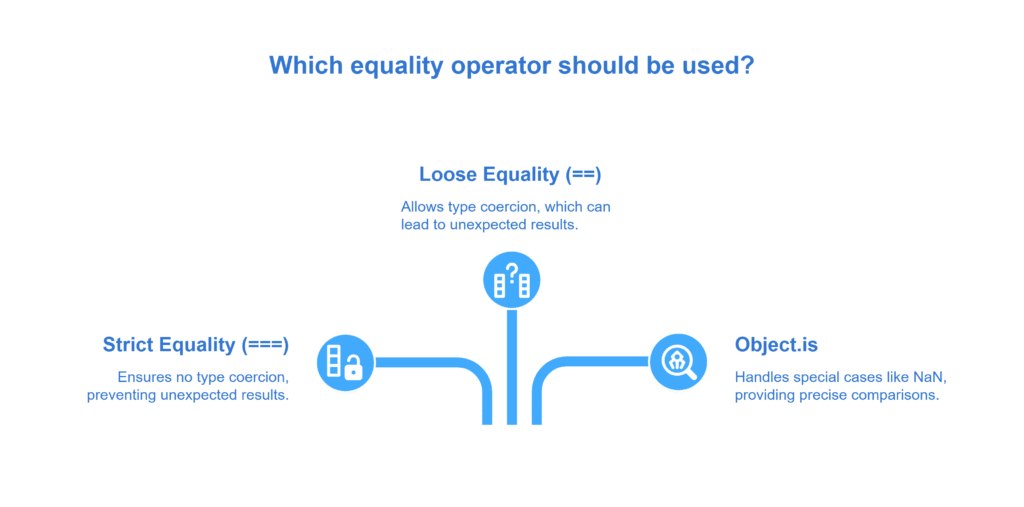
Recommendation:
Prefer === and !== to avoid unexpected coercion bugs.
Use Object.is when needing special handling (e.g., distinguishing NaN).
Examples:
0 == false; // true
0 === false; // false
'' == 0; // true
'' === 0; // false
null == undefined; // true
null === undefined; // false
NaN == NaN; // false
Object.is(NaN, NaN); // true
Question 7: What are arrow functions and how do they handle this?
Answer:
- Syntax & Conciseness:
- Arrow functions: (param) => expression or (param) => { statements }. They offer shorter syntax than traditional function expressions. (developer.mozilla.org)
- Arrow functions: (param) => expression or (param) => { statements }. They offer shorter syntax than traditional function expressions. (developer.mozilla.org)
- this Binding:
- Arrow functions do not have their own this. They capture this lexically from the surrounding scope at definition time. Consequently, methods defined as arrow functions cannot override this with call, apply, or bind. (developer.mozilla.org)
- Arrow functions do not have their own this. They capture this lexically from the surrounding scope at definition time. Consequently, methods defined as arrow functions cannot override this with call, apply, or bind. (developer.mozilla.org)
- No arguments Object:
- Arrow functions lack arguments; use rest parameters instead.
- Arrow functions lack arguments; use rest parameters instead.
- Cannot be Used as Constructors:
- Cannot be invoked with new.
- Cannot be invoked with new.
- Use Cases:
- Inline callbacks (e.g., array.map(x => x * 2)).
- Preserving outer this in event handlers or promise chains.
- Inline callbacks (e.g., array.map(x => x * 2)).
- Pitfalls:
- Avoid defining object methods as arrow functions if you need this to refer to the object instance.
- Avoid defining object methods as arrow functions if you need this to refer to the object instance.
Question 8: How does destructuring work in JavaScript?
Answer:
Array Destructuring:
const [a, b] = [1, 2];
// a = 1, b = 2
Object Destructuring:
const { x, y } = { x: 10, y: 20 };
// x = 10, y = 20
- Default Values:
Provide defaults when property/index may be missing:
const [a = 5, b = 10] = [1];
// a=1, b=10
const { m = 3 } = {};
// m=3
Nested Destructuring:
const obj = { p: { q: 42 }, arr: [7, 8] };
const { p: { q }, arr: [first] } = obj;
// q = 42, first = 7
Rest in Destructuring:
const [head, …tail] = [1, 2, 3];
// head=1, tail=[2,3]
const { a, …rest } = { a: 1, b: 2, c: 3 };
// rest={b:2,c:3}
- Use Cases:
- Function parameters: function f({x, y}) { … }.
- Cleaner extraction from objects/arrays.
- Function parameters: function f({x, y}) { … }.
- Pitfalls:
- Beware of undefined paths in nested destructuring (use defaults or optional chaining). (developer.mozilla.org)
- Beware of undefined paths in nested destructuring (use defaults or optional chaining). (developer.mozilla.org)
Question 9: Explain rest and spread operators with examples.
Answer:
- Spread (…):
- Expands an iterable or object into individual elements/properties.
- Expands an iterable or object into individual elements/properties.
Arrays:
const arr1 = [1, 2];
const arr2 = […arr1, 3]; // [1,2,3]
Objects:
const obj1 = { a: 1 };
const obj2 = { …obj1, b: 2 }; // {a:1,b:2}
- Rest (…):
- Collects remaining elements/properties into array/object.
- Collects remaining elements/properties into array/object.
Arrays:
const [first, …rest] = [1,2,3]; // first=1, rest=[2,3]
Objects:
const { a, …others } = { a: 1, b: 2, c: 3 };
// a=1, others={b:2,c:3}
Function parameters:
function sum(…numbers) {
return numbers.reduce((acc, n) => acc + n, 0);
}
sum(1,2,3); // 6
- Pitfalls & Notes:
- Order matters: spread in array literal expands elements; rest in destructuring must be last.
- Shallow copy: … creates a shallow clone; nested objects remain by reference.
- Order matters: spread in array literal expands elements; rest in destructuring must be last.
- Citations: MDN covers spread/rest in operators guide. (developer.mozilla.org)
Question 10: What is the difference between shallow copy and deep copy? How can you implement both?
Answer:
- Shallow Copy:
- Copies top-level properties; if properties reference objects/arrays, those references are copied, not the nested values.
- For arrays: const copy = arr.slice() or const copy = […arr].
- For objects: const copy = Object.assign({}, obj) or const copy = { …obj }.
- Implication: Mutating nested objects affects both original and copy.
- Copies top-level properties; if properties reference objects/arrays, those references are copied, not the nested values.
- Deep Copy:
- Recursively duplicates nested structures so changes to nested elements do not affect the original.
- Recursively duplicates nested structures so changes to nested elements do not affect the original.
- Implementation Approaches:
Structured Clone (Modern):
const deep = structuredClone(original);
- Supported in modern environments. (developer.mozilla.org)
JSON Methods:
const deep = JSON.parse(JSON.stringify(original));
Limitations: Loses functions, undefined, Symbol, and cannot handle circular references.
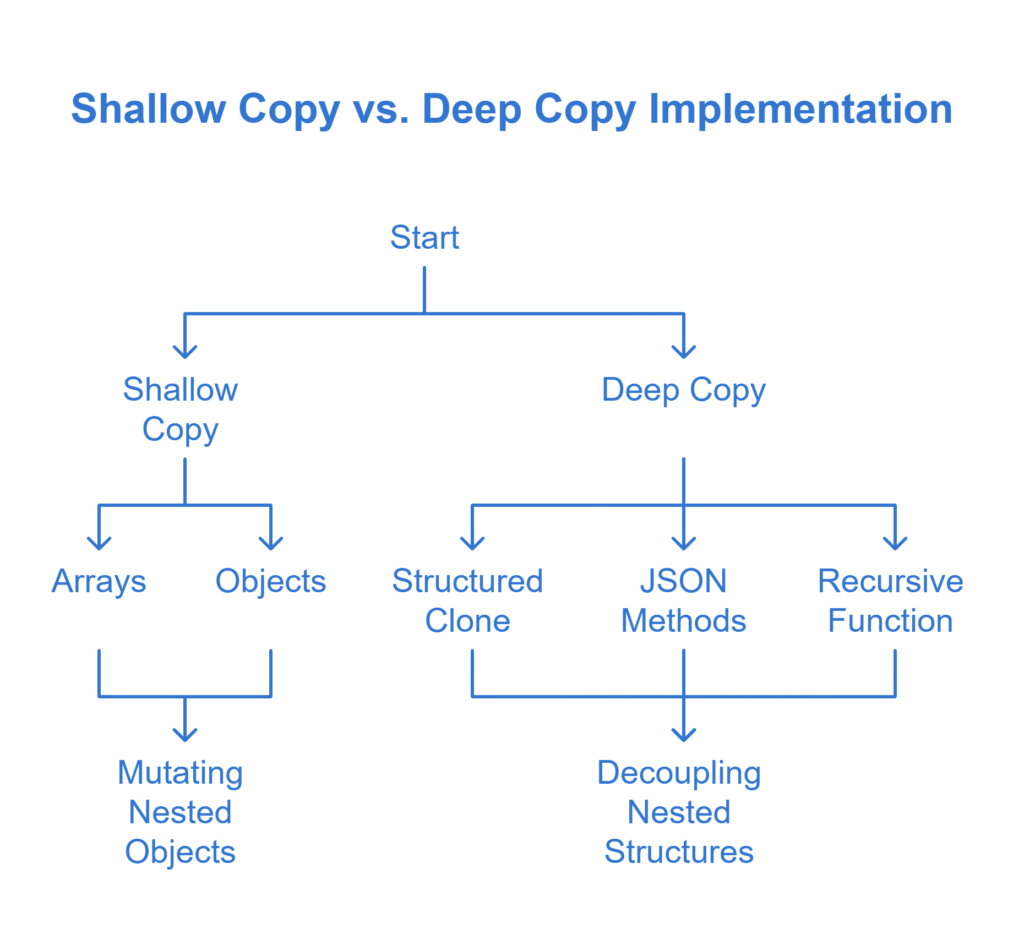
Recursive Function:
Custom implementation that handles objects, arrays, Dates, RegExps, Maps, Sets, etc. Careful with circular references.
function deepClone(obj, seen = new WeakMap()) {
if (obj === null || typeof obj !== 'object') return obj;
if (seen.has(obj)) return seen.get(obj);
let copy;
if (Array.isArray(obj)) copy = [];
else if (obj instanceof Date) copy = new Date(obj);
else if (obj instanceof RegExp) copy = new RegExp(obj);
else copy = {};
seen.set(obj, copy);
for (const key in obj) {
if (Object.prototype.hasOwnProperty.call(obj, key)) {
copy[key] = deepClone(obj[key], seen);
}
}
return copy;
}
When to Use:
Use shallow copy for simple state updates when nested references are managed immutably.
Use deep clone when truly decoupling nested structures, but be mindful of performance.
fetch('/api/data')
.then(response => response.json())
.catch(err => console.error('Fetch error', err))
.finally(() => console.log('Fetch attempt finished'));
- Best Practices:
- Use catch at the end to handle errors.
- Use finally for teardown regardless of success/failure (e.g., hide loading spinner).
- Understand chaining: returning values vs rethrowing to propagate errors.
- Use catch at the end to handle errors.
Question 12: How would you implement a Promise.all polyfill?
Answer:
- Behavior Recap: Promise.all(iterable) returns a promise that fulfills with an array of results when all input promises fulfill; rejects immediately when any input rejects. (developer.mozilla.org)
Polyfill Outline:
function promiseAll(promises) {
return new Promise((resolve, reject) => {
if (!promises || typeof promises[Symbol.iterator] !== 'function') {
return reject(new TypeError('Argument is not iterable'));
}
const results = [];
let fulfilledCount = 0;
let total = 0;
for (const p of promises) total++;
if (total === 0) return resolve([]);
let index = 0;
for (const p of promises) {
const currentIndex = index;
Promise.resolve(p)
.then(value => {
results[currentIndex] = value;
fulfilledCount++;
if (fulfilledCount === total) {
resolve(results);
}
})
.catch(err => reject(err));
index++;
}
});
}
- Explanation:
- Normalize each input via Promise.resolve so non-promise values are handled.
- Keep track of index to place results in order.
- If any promise rejects, immediately reject overall.
- Normalize each input via Promise.resolve so non-promise values are handled.
- Edge Cases:
- Empty iterable: resolve with [].
- Non-iterable: reject with TypeError.
- Empty iterable: resolve with [].
- Performance:
- This polyfill matches spec semantics; built-in Promise.all is optimized in engines.
- This polyfill matches spec semantics; built-in Promise.all is optimized in engines.
Question 13: What’s the difference between async/await and Promises?
Answer:
- Promises:
- Represent eventual value; use .then/.catch for chaining.
- Asynchronous control flow based on callbacks attached to promise.
- Represent eventual value; use .then/.catch for chaining.
- async/await:
- Syntactic sugar over Promises: async function returns a promise; await pauses execution until the promise resolves or rejects (within async function).
- Makes asynchronous code look synchronous, improving readability. (developer.mozilla.org)
- Syntactic sugar over Promises: async function returns a promise; await pauses execution until the promise resolves or rejects (within async function).
- Error Handling:
- In the chains: use catch.
- With async/await: wrap await calls in try/catch blocks.
- In the chains: use catch.
- Parallel vs Sequential:
await sequentially waits; to run in parallel, start promises before awaiting:
const p1 = fetch(url1);
const p2 = fetch(url2);
const r1 = await p1;
const r2 = await p2;
- Pitfalls:
- Excessive sequential awaits can degrade performance.
- async functions always return a promise; be mindful of return values.
- Excessive sequential awaits can degrade performance.
- Use Cases:
- Prefer async/await for readability, especially with multiple asynchronous steps; fall back to promise combinators (Promise.all, Promise.race) when concurrency is needed.
- Prefer async/await for readability, especially with multiple asynchronous steps; fall back to promise combinators (Promise.all, Promise.race) when concurrency is needed.
Question 14: How does setTimeout work internally?
Answer:
- Behavior:
- setTimeout(callback, delay) schedules the callback to be added to the event (macrotask) queue after at least delay milliseconds.
- Minimum delay in browsers can be clamped (e.g., 4ms for nested timers). (developer.mozilla.org)
- setTimeout(callback, delay) schedules the callback to be added to the event (macrotask) queue after at least delay milliseconds.
- Event Loop Interaction:
- After the timer expires, callback is queued as a macrotask. It runs when current call stack is empty and after all microtasks drain.
- delay is minimum wait; actual callback execution may be later due to busy event loop.
- After the timer expires, callback is queued as a macrotask. It runs when current call stack is empty and after all microtasks drain.
- Node.js Differences:
- Node uses libuv for timers; similar concept: timers phase in the event loop.
- Node uses libuv for timers; similar concept: timers phase in the event loop.
- Use Cases & Pitfalls:
- Avoid relying on exact timing for UI updates.
- Clearing timers with clearTimeout prevents callback if called before execution.
- Avoid relying on exact timing for UI updates.
Recursive setTimeout vs setInterval: recursive allows dynamic interval adjustments.

Example:
console.log('Before');
setTimeout(() => console.log('After ~0ms'), 0);
console.log('After scheduling');
// Likely output:
// Before
// After scheduling
// After ~0ms
- Performance:
- Timers may fire late if main thread is busy. For animation, prefer requestAnimationFrame.
- Timers may fire late if main thread is busy. For animation, prefer requestAnimationFrame.
Question 15: Explain debounce vs throttle. How would you implement them?
Answer:
- Debounce:
- Ensures a function runs only after a specified idle period since the last invocation. Common for input events (e.g., search-as-you-type) to avoid excessive calls.
- Ensures a function runs only after a specified idle period since the last invocation. Common for input events (e.g., search-as-you-type) to avoid excessive calls.
Implementation:
function debounce(fn, delay) {
let timeoutId;
return function(...args) {
clearTimeout(timeoutId);
timeoutId = setTimeout(() => fn.apply(this, args), delay);
};
}
Throttle:
Ensures a function runs at most once in a specified interval. Useful for scroll or resize events to limit calls.
function throttle(fn, interval) {
let lastTime = 0;
return function(...args) {
const now = Date.now();
if (now - lastTime >= interval) {
lastTime = now;
fn.apply(this, args);
}
};
}
Implementation (Timeout version):
function throttle(fn, interval) {
let timeoutId = null;
return function(...args) {
if (!timeoutId) {
fn.apply(this, args);
timeoutId = setTimeout(() => {
timeoutId = null;
}, interval);
}
};
}
- Differences:
- Debounce waits until events stop; throttle invokes at regular intervals no matter how many events occur.
- Debounce waits until events stop; throttle invokes at regular intervals no matter how many events occur.
- Edge Cases:
- Leading/trailing invocation options: advanced implementations allow immediate invocation then pause, or invoke at end.
- Leading/trailing invocation options: advanced implementations allow immediate invocation then pause, or invoke at end.
- Citations: Common pattern knowledge in JS; see MDN or blog posts for deeper discussion. (developer.mozilla.org)
DOM & Browser Internals (Questions 16–20)
Question 16: How does event delegation work?
Answer:
- Concept:
- Instead of attaching event listeners to multiple child elements, attach a single listener on a common ancestor. Use event bubbling to catch events from descendants. (developer.mozilla.org)
- Instead of attaching event listeners to multiple child elements, attach a single listener on a common ancestor. Use event bubbling to catch events from descendants. (developer.mozilla.org)
- Mechanism:
- An event on a child element bubbles up through parent nodes. In the ancestor’s listener, inspect event.target or event.currentTarget to determine the actual source and handle accordingly.
- An event on a child element bubbles up through parent nodes. In the ancestor’s listener, inspect event.target or event.currentTarget to determine the actual source and handle accordingly.
Example:
<ul id="menu">
<li data-action="open">Open</li>
<li data-action="save">Save</li>
<li data-action="close">Close</li>
</ul>
document.getElementById('menu').addEventListener('click', (event) => {
const li = event.target.closest('li');
if (!li) return;
const action = li.dataset.action;
// handle action
console.log(`User clicked ${action}`);
});
Benefits:
Fewer listeners: better performance and easier memory management.
Dynamically added elements automatically covered.
Caveats:
Check event.target carefully; event may originate from nested elements inside the child.
Use event.stopPropagation() with caution if stopping further bubbling.
parent.addEventListener('click', () => console.log('parent bubbling'));
parent.addEventListener('click', () => console.log('parent capturing'), { capture: true });
child.addEventListener('click', () => console.log('child'));
- Clicking child logs:
- parent capturing
- child
- parent bubbling
- parent capturing
- Use Cases:
- Capturing rarely needed; mostly for frameworks/libraries or when you need to intercept events before children.
- Capturing rarely needed; mostly for frameworks/libraries or when you need to intercept events before children.
- Pitfalls:
- Unintended interference: capturing handlers may handle events before intended target.
- Avoid complexity: prefer bubbling unless specific need for capturing.
- Unintended interference: capturing handlers may handle events before intended target.
Question 18: How would you optimize a page for faster load time?
Answer:
- Minimize Resources:
- Bundle and minify CSS/JS. Use tree-shaking to remove unused code. (developer.mozilla.org)
- Compress images (webp, lazy loading).
- Bundle and minify CSS/JS. Use tree-shaking to remove unused code. (developer.mozilla.org)
- HTTP/2 & Caching:
- Use HTTP/2 multiplexing to parallelize assets. Leverage long-term caching with hashed filenames.
- Use HTTP/2 multiplexing to parallelize assets. Leverage long-term caching with hashed filenames.
- Critical Rendering Path:
- Inline critical CSS; defer non-critical CSS/JS.
- Use defer or async on scripts to avoid blocking parsing.
- Inline critical CSS; defer non-critical CSS/JS.
- Lazy Loading:
- Lazy-load images, videos, below-the-fold content.
- Code-splitting: load JS chunks on demand.
- Lazy-load images, videos, below-the-fold content.
- Reduce Payload:
- Use CDN for static assets.
- Remove unused libraries; prefer lightweight utilities.
- Use CDN for static assets.
- Performance Monitoring:
- Use Lighthouse, WebPageTest to identify bottlenecks.
- Use Lighthouse, WebPageTest to identify bottlenecks.
- Server-Side Rendering (SSR):
- Pre-render critical content to reduce Time to First Byte (TTFB) and First Contentful Paint (FCP).
- Pre-render critical content to reduce Time to First Byte (TTFB) and First Contentful Paint (FCP).
- Use HTTP Caching Headers:
- Cache-Control, ETag, Last-Modified.
- Cache-Control, ETag, Last-Modified.
- Avoid Render-Blocking Resources:
- Load fonts asynchronously; minimize external requests.
- Load fonts asynchronously; minimize external requests.
- Citations: MDN and web performance best practices. (developer.mozilla.org)
Question 19: Explain how reflow and repaint work in the browser.
Answer:
- Reflow (Layout):
- Occurs when changes affect element geometry (e.g., size, position). Browser recalculates layout of affected elements and potentially entire page. Expensive operation. (developer.mozilla.org)
- Occurs when changes affect element geometry (e.g., size, position). Browser recalculates layout of affected elements and potentially entire page. Expensive operation. (developer.mozilla.org)
- Repaint (Paint):
- After layout, repaint redraws pixels for elements whose visual properties (color, visibility) changed but whose geometry remains the same.
- After layout, repaint redraws pixels for elements whose visual properties (color, visibility) changed but whose geometry remains the same.
- Triggers:
- DOM manipulations: adding/removing elements, changing styles.
- Changing classes that affect layout.
- Reading layout properties (e.g., offsetHeight) can force synchronous reflow (“layout thrashing”).
- DOM manipulations: adding/removing elements, changing styles.
- Optimization Tips:
- Batch DOM reads and writes separately to avoid alternating reads/writes.
- Use CSS transforms and opacity changes (GPU-accelerated) instead of layout changes when animating.
- Offscreen DOM operations: use document.createDocumentFragment or display: none containers to make multiple updates before reflow.
- Batch DOM reads and writes separately to avoid alternating reads/writes.
- Tools:
- DevTools Performance tab to analyze layout and paint times.
- DevTools Performance tab to analyze layout and paint times.
- Citations: Browser internals guides on performance. (developer.mozilla.org)
Question 20: Explain how addEventListener differs when using { once: true } or { passive: true }.
Answer:
- once: true:
- Listener automatically removed after first invocation. Useful for one-time initialization events.
- Listener automatically removed after first invocation. Useful for one-time initialization events.
- passive: true:
- Indicates listener will not call preventDefault(). Allows browser to optimize scrolling performance by not waiting for listener to finish. Particularly beneficial on touch and wheel events. If you call preventDefault() inside a passive listener, it is ignored and may warn in console.
- Indicates listener will not call preventDefault(). Allows browser to optimize scrolling performance by not waiting for listener to finish. Particularly beneficial on touch and wheel events. If you call preventDefault() inside a passive listener, it is ignored and may warn in console.
Syntax:
element.addEventListener(‘scroll’, onScroll, { passive: true });
element.addEventListener(‘click’, onClickOnce, { once: true });
- Use Cases:
- Passive: scroll, touchmove to improve performance.
- Once: initialization, one-off user interactions.
- Passive: scroll, touchmove to improve performance.
- Citations: MDN event listener options. (developer.mozilla.org)
Memory & Performance (Questions 21–25)
Question 21: What causes memory leaks in JavaScript?
Answer:
- Common Causes:
- Global Variables: Unintentionally creating globals prevents garbage collection.
- Closures Holding References: Long-lived closures can retain large objects if not released.
- DOM References: Detached DOM nodes still referenced in JS structures.
- Timers & Callbacks: Uncleared intervals or event listeners keeping objects alive.
- Caches without eviction: Large caches (e.g., data structures) never cleaned up.
- Global Variables: Unintentionally creating globals prevents garbage collection.
- Identification:
- Use browser DevTools Memory profiler to take heap snapshots, identify detached DOM nodes or unusually large retained objects. (developer.mozilla.org)
- Use browser DevTools Memory profiler to take heap snapshots, identify detached DOM nodes or unusually large retained objects. (developer.mozilla.org)
- Prevention:
- Release references when no longer needed: remove event listeners, clear intervals/timeouts.
- Use WeakMap/WeakSet for caches: allows garbage collection when keys no longer referenced elsewhere. (en.wikipedia.org)
- Avoid accidental globals; use strict mode.
- Release references when no longer needed: remove event listeners, clear intervals/timeouts.
- Best Practices:
- Modular code with clear lifecycle management.
- Observe patterns in frameworks (React/Vue) for cleaning up subscriptions/effects.
- Modular code with clear lifecycle management.
Question 22: How can you prevent memory leaks in large SPAs?
Answer:
- Component Lifecycle Management:
- In frameworks (React, Vue, Angular), clean up subscriptions, event listeners, timers in unmount/destroy hooks.
- In frameworks (React, Vue, Angular), clean up subscriptions, event listeners, timers in unmount/destroy hooks.
- Avoid Dangling References:
- Don’t store references to DOM nodes beyond their lifetime.
- Use WeakMap for caching per-element data.
- Don’t store references to DOM nodes beyond their lifetime.
- Lazy Loading & Code Splitting:
- Load modules on demand; unload when not needed (in some frameworks with dynamic import cleanup).
- Load modules on demand; unload when not needed (in some frameworks with dynamic import cleanup).
- Monitor Memory Usage:
- Periodically profile memory usage; look for growth over time.
- Periodically profile memory usage; look for growth over time.
- Efficient Data Structures:
- Use appropriate data structures to avoid retaining large datasets in memory unnecessarily.
- Use appropriate data structures to avoid retaining large datasets in memory unnecessarily.
- Garbage Collection Awareness:
- Understand how closures and variable scopes affect GC eligibility.
- Understand how closures and variable scopes affect GC eligibility.
- Use Framework Tools:
- React DevTools, Vue DevTools can highlight memory concerns.
- React DevTools, Vue DevTools can highlight memory concerns.
- Citations: Best practices in SPA performance guides. (developer.mozilla.org)
Question 23: Explain the concept of garbage collection in JS.
Answer:
- Automatic Memory Management:
- JavaScript engines automatically reclaim memory of objects no longer reachable from roots (e.g., global scope, active call stack). (developer.mozilla.org)
- JavaScript engines automatically reclaim memory of objects no longer reachable from roots (e.g., global scope, active call stack). (developer.mozilla.org)
- Reachability:
- If no references exist to an object (including via closures), it becomes eligible for garbage collection.
- If no references exist to an object (including via closures), it becomes eligible for garbage collection.
- Algorithms:
- Modern engines use generational GC: young and old generations; minor and major GC cycles.
- Modern engines use generational GC: young and old generations; minor and major GC cycles.
- Cycles:
- JavaScript GC handles cyclic references since reachability is based on root reachability, not reference counting. Two objects referencing each other but unreachable from roots are collected.
- JavaScript GC handles cyclic references since reachability is based on root reachability, not reference counting. Two objects referencing each other but unreachable from roots are collected.
- Implications:
- Minimizing unnecessary references ensures timely memory release.
- Minimizing unnecessary references ensures timely memory release.
- Diagnostic:
- Use heap snapshots to detect objects retained unexpectedly.
- Use heap snapshots to detect objects retained unexpectedly.
- Citations: MDN on garbage collection. (developer.mozilla.org)

Question 24: What is a WeakMap and how is it useful?
Answer:
- Definition:
- WeakMap is a collection of key-value pairs where keys are objects, and the references to keys are held weakly. If no other references to a key exist, the entry can be garbage-collected. (en.wikipedia.org)
- WeakMap is a collection of key-value pairs where keys are objects, and the references to keys are held weakly. If no other references to a key exist, the entry can be garbage-collected. (en.wikipedia.org)
- Characteristics:
- Keys must be objects; values can be arbitrary.
- Cannot iterate over WeakMap (no .keys() or .entries()), because entries may disappear anytime due to GC.
- Keys must be objects; values can be arbitrary.
- Use Cases:
- Attach metadata to objects without preventing their GC (e.g., DOM nodes in caching).
- Implement private data for objects in libraries.
- Attach metadata to objects without preventing their GC (e.g., DOM nodes in caching).
Example:
const wm = new WeakMap();
(function() {
const obj = {};
wm.set(obj, 'metadata');
// After this function ends, if no other refs to obj, both obj and its entry in wm can be GC’d
})();
- Memory Leak Prevention:
- Use WeakMap for caches tied to object lifecycles, preventing leaks when objects get removed. (en.wikipedia.org)
- Use WeakMap for caches tied to object lifecycles, preventing leaks when objects get removed. (en.wikipedia.org)
Question 25: How would you profile JS performance in the browser?
Answer:
- DevTools Performance Tab:
- Record page interactions to visualize CPU usage, scripting time, rendering, painting.
- Record page interactions to visualize CPU usage, scripting time, rendering, painting.
- Memory Profiling:
- Heap snapshots to identify memory leaks or large memory usage.
- Heap snapshots to identify memory leaks or large memory usage.
- Lighthouse Audits:
- Automated performance audits to pinpoint slow resources.
- Automated performance audits to pinpoint slow resources.
- FPS and Rendering:
- Use “Rendering” tools to monitor FPS, forced reflows, layout thrashing.
- Use “Rendering” tools to monitor FPS, forced reflows, layout thrashing.
- Network Tab:
- Analyze resource load times, bundler-induced overhead.
- Analyze resource load times, bundler-induced overhead.
- Console Profiling:
- console.time / console.timeEnd for custom function timing.
- console.time / console.timeEnd for custom function timing.
- Third-party Tools:
- WebPageTest, GTmetrix for simulated real-world performance testing.
- WebPageTest, GTmetrix for simulated real-world performance testing.
- Automation:
- Integrate performance tests in CI (e.g., Puppeteer scripts).
- Integrate performance tests in CI (e.g., Puppeteer scripts).
- Interpretation:
- Focus on long tasks (>50ms) blocking UI; aim to break into smaller chunks or use Web Workers.
- Focus on long tasks (>50ms) blocking UI; aim to break into smaller chunks or use Web Workers.
- Citations: Browser performance guides. (developer.mozilla.org)
Functions & OOP (Questions 26–30)
Question 26: What is the difference between function declaration and function expression?
Answer:
- Function Declaration:
- Syntax: function foo() { … }.
- Hoisted fully (definition available before declaration in code). (developer.mozilla.org)
- Syntax: function foo() { … }.
- Function Expression:
- Syntax: const foo = function() { … }; or const foo = () => { … };.
- Treated like variable assignment: subject to variable hoisting rules (TDZ for let/const, undefined for var).
- Syntax: const foo = function() { … }; or const foo = () => { … };.
- Named vs Anonymous Expressions:
- Named expressions can aid debugging (const foo = function bar(){}).
- Named expressions can aid debugging (const foo = function bar(){}).
- Use Cases:
- Declarations for top-level utility functions.
- Expressions as callbacks, IIFEs.
- Declarations for top-level utility functions.
- Scoping & Hoisting:
- Understanding differences prevents reference errors.
- Understanding differences prevents reference errors.
Question 27: What is function currying? Can you write a curried function?
Answer:
- Definition:
- Transform a function with multiple arguments into a sequence of functions each taking a single argument.
- Example: f(a, b, c) → f(a)(b)(c).
- Transform a function with multiple arguments into a sequence of functions each taking a single argument.
- Benefits:
- Partial application: pre-fill some arguments, returning a new function awaiting the rest.
- Partial application: pre-fill some arguments, returning a new function awaiting the rest.
Implementation:
function curry(fn) {
return function curried(...args) {
if (args.length >= fn.length) {
return fn.apply(this, args);
}
return function(...nextArgs) {
return curried.apply(this, args.concat(nextArgs));
};
};
}
// Example:
function add(a, b, c) { return a + b + c; }
const curriedAdd = curry(add);
console.log(curriedAdd(1)(2)(3)); // 6
console.log(curriedAdd(1, 2)(3)); // 6
- Edge Cases:
- Handling variadic functions (when fn.length is not reliable); modify logic accordingly.
- Handling variadic functions (when fn.length is not reliable); modify logic accordingly.
- Real-World Use:
- Libraries like Lodash provide _.curry.
- Libraries like Lodash provide _.curry.
- Citations: Conceptual from functional programming; refer to MDN for function length property. (developer.mozilla.org)
Question 28: Explain call, apply, and bind with examples.
Answer:
- Purpose: Control this context when invoking functions.
call(thisArg, …args): Immediately invokes function with given this and arguments list.
function greet(greeting) {
console.log(`${greeting}, ${this.name}`);
}
const person = { name: ‘Alice’ };
greet.call(person, ‘Hello’); // Hello, Alice
apply(thisArg, argsArray): Immediately invokes with this and an array of arguments.
greet.apply(person, [‘Hi’]); // Hi, Alice
bind(thisArg, …args): Returns a new function permanently bound to thisArg (and pre-filled arguments), without invoking it immediately.
const sayHelloToAlice = greet.bind(person, ‘Hello’);
sayHelloToAlice(); // Hello, Alice
- Use Cases:
- Borrowing methods: e.g., Array.prototype.slice.call(arguments).
- Event handlers: ensure correct this when passing methods.
- Partial application: pre-fill some arguments with bind.
- Borrowing methods: e.g., Array.prototype.slice.call(arguments).
- Pitfalls:
- Excessive use can obscure code clarity.
- Excessive use can obscure code clarity.
- Citations: MDN on Function.prototype.call/apply/bind. (developer.mozilla.org)
Question 29: How do classes work in ES6? What is syntactic sugar in this context?
Answer:
- ES6 Classes:
- Introduced class keyword, constructor, extends, super to define constructor functions and inheritance more declaratively.
- Under the hood, classes use prototype-based inheritance; syntax simplifies prototype setup. (developer.mozilla.org)
- Introduced class keyword, constructor, extends, super to define constructor functions and inheritance more declaratively.
- Syntactic Sugar:
- The class syntax does not introduce a new OOP model; it’s sugar over existing prototypes and constructor functions.
- The class syntax does not introduce a new OOP model; it’s sugar over existing prototypes and constructor functions.
Example:
class Animal {
constructor(name) {
this.name = name;
}
speak() {
console.log(`${this.name} makes a noise.`);
}
}
class Dog extends Animal {
constructor(name) {
super(name);
}
speak() {
console.log(`${this.name} barks.`);
}
}
const d = new Dog('Rex');
d.speak(); // Rex barks.
- Key Points:
- Class declarations are not hoisted like function declarations.
- Class methods are non-enumerable.
- extends: sets up prototype chain; super(…) invokes parent constructor.
- Class declarations are not hoisted like function declarations.
- Pitfalls:
- Be aware of this behavior; must call super() before using this in subclass constructors.
- Be aware of this behavior; must call super() before using this in subclass constructors.
- Citations: MDN Classes in JS. (developer.mozilla.org)
Question 30: What is the purpose of super() in class inheritance?
Answer:
- In Constructor:
- In a subclass constructor, super(args) invokes the parent class’s constructor in the context of the subclass (this). Required before accessing this. (developer.mozilla.org)
- In a subclass constructor, super(args) invokes the parent class’s constructor in the context of the subclass (this). Required before accessing this. (developer.mozilla.org)
- In Methods:
- super.methodName(…) calls a method on the parent prototype.
- super.methodName(…) calls a method on the parent prototype.
Example:
class Parent {
constructor(value) {
this.value = value;
}
show() {
console.log(this.value);
}
}
class Child extends Parent {
constructor(value, extra) {
super(value); // must call before using `this`
this.extra = extra;
}
showAll() {
super.show();
console.log(this.extra);
}
}
- Pitfalls:
- Forgetting super() in subclass constructor leads to ReferenceError.
- Understanding prototype chain: super refers to parent prototype.
- Forgetting super() in subclass constructor leads to ReferenceError.
Data Structures & Algorithmic Patterns in JS (Questions 31–35)
Question 31: How would you implement an LRU cache in JS?
Answer:
- Least Recently Used (LRU):
- Cache eviction policy that discards least recently used items first.
- Cache eviction policy that discards least recently used items first.
- Implementation Outline:
- Use a combination of a Map (to track key → node) and a doubly-linked list (to order usage: most recent at head, least recent at tail).
- On get(key):
- If exists: move node to head, return value.
- Else: return -1 or undefined.
- If exists: move node to head, return value.
- On put(key, value):
- If key exists: update value, move node to head.
- Else:
- Create new node, add to head.
- Add to Map.
- If size exceeds capacity: remove tail node, delete from Map.
- Create new node, add to head.
- If key exists: update value, move node to head.
- Use a combination of a Map (to track key → node) and a doubly-linked list (to order usage: most recent at head, least recent at tail).
Example:
class Node {
constructor(key, value) {
this.key = key;
this.value = value;
this.prev = null;
this.next = null;
}
}
class LRUCache {
constructor(capacity) {
this.capacity = capacity;
this.map = new Map();
// Dummy head/tail to avoid null checks
this.head = new Node(null, null);
this.tail = new Node(null, null);
this.head.next = this.tail;
this.tail.prev = this.head;
}
_addNode(node) {
node.prev = this.head;
node.next = this.head.next;
this.head.next.prev = node;
this.head.next = node;
}
_removeNode(node) {
const prev = node.prev;
const next = node.next;
prev.next = next;
next.prev = prev;
}
_moveToHead(node) {
this._removeNode(node);
this._addNode(node);
}
_removeTail() {
const node = this.tail.prev;
this._removeNode(node);
return node;
}
get(key) {
const node = this.map.get(key);
if (!node) return -1;
this._moveToHead(node);
return node.value;
}
put(key, value) {
let node = this.map.get(key);
if (node) {
node.value = value;
this._moveToHead(node);
} else {
node = new Node(key, value);
this.map.set(key, node);
this._addNode(node);
if (this.map.size > this.capacity) {
const tail = this._removeTail();
this.map.delete(tail.key);
}
}
}
}
- Complexity:
- get and put operations: O(1) time.
- get and put operations: O(1) time.
- Use Cases:
- Caching API responses, image caches, memoization with bounded size.
- Caching API responses, image caches, memoization with bounded size.
- Citations: Standard algorithmic pattern; verify behavior in code implementation references. (developer.mozilla.org)
Question 32: How would you flatten a deeply nested array?
Answer:
- Built-in:
- Array.prototype.flat(Infinity): flattens all nested levels. (developer.mozilla.org)
- Array.prototype.flat(Infinity): flattens all nested levels. (developer.mozilla.org)
Recursive Solution:
function flatten(arr) {
const res = [];
for (const item of arr) {
if (Array.isArray(item)) {
res.push(...flatten(item));
} else {
res.push(item);
}
}
return res;
}
Iterative Using Stack:
function flattenIterative(arr) {
const stack = [...arr];
const res = [];
while (stack.length) {
const next = stack.pop();
if (Array.isArray(next)) {
// Push elements in reverse so original order preserved
for (let i = next.length - 1; i >= 0; i--) {
stack.push(next[i]);
}
} else {
res.push(next);
}
}
return res.reverse();
}
- Use Cases:
- Data normalization, processing nested JSON structures.
- Data normalization, processing nested JSON structures.
- Performance Considerations:
- Recursive approach may cause call stack overflow for extremely deep nesting.
- Iterative approach safer for very deep arrays.
- Recursive approach may cause call stack overflow for extremely deep nesting.
- Citations: MDN Array.flat documentation. (developer.mozilla.org)
Question 33: Implement a deep clone function for an object.
Answer:
- Revisit: See Question 10 for deep vs shallow copy.
Implementation: Use structuredClone if available:
const deepCopy = (obj) => structuredClone(obj);
Manual Recursive (handles common types, avoids circular references):
function deepClone(obj, seen = new WeakMap()) {
if (obj === null || typeof obj !== 'object') return obj;
if (seen.has(obj)) return seen.get(obj);
let copy;
if (obj instanceof Date) copy = new Date(obj);
else if (obj instanceof RegExp) copy = new RegExp(obj);
else if (obj instanceof Map) {
copy = new Map();
seen.set(obj, copy);
for (const [key, val] of obj) {
copy.set(key, deepClone(val, seen));
}
} else if (obj instanceof Set) {
copy = new Set();
seen.set(obj, copy);
for (const val of obj) {
copy.add(deepClone(val, seen));
}
} else if (Array.isArray(obj)) {
copy = [];
seen.set(obj, copy);
for (const item of obj) {
copy.push(deepClone(item, seen));
}
} else {
copy = {};
seen.set(obj, copy);
for (const key in obj) {
if (Object.prototype.hasOwnProperty.call(obj, key)) {
copy[key] = deepClone(obj[key], seen);
}
}
}
return copy;
}
- Edge Cases:
- Functions, Symbols, WeakMap/WeakSet not handled (often acceptable or require special handling).
- Circular references resolved via seen WeakMap.
- Performance:
Deep-cloning large objects can be expensive; use judiciously.
Citations: MDN structuredClone. (developer.mozilla.org)
Question 34: How would you implement a simple pub-sub (observer) pattern in JS?
Answer:
- Pattern:
- Allows decoupling: publishers emit events; subscribers register callbacks to handle events.
Implementation:
class EventEmitter {
constructor() {
this.events = {};
}
subscribe(eventName, handler) {
if (!this.events[eventName]) {
this.events[eventName] = new Set();
}
this.events[eventName].add(handler);
return {
unsubscribe: () => {
this.events[eventName].delete(handler);
if (this.events[eventName].size === 0) {
delete this.events[eventName];
}
},
};
}
publish(eventName, data) {
if (!this.events[eventName]) return;
for (const handler of this.events[eventName]) {
try {
handler(data);
} catch (err) {
console.error(`Error in handler for ${eventName}:`, err);
}
}
}
}
// Usage:
const emitter = new EventEmitter();
const sub = emitter.subscribe('data', (payload) => {
console.log('Received:', payload);
});
emitter.publish('data', { x: 1 }); // Received: {x:1}
sub.unsubscribe();
- Variations:
- Allow once-only subscribers.
- Prioritize handlers.
- Memory Considerations:
- Clean up unsubscribed handlers to prevent leaks.
- Use Cases:
- Cross-component communication, custom event systems in vanilla JS or frameworks.
- Citations: Design pattern knowledge; see JS community articles. (developer.mozilla.org)
Question 35: Write a function that memoizes another function.
Answer:
- Definition:
- Memoization caches results of expensive function calls based on arguments to avoid recomputation.
Implementation:
function memoize(fn) {
const cache = new Map();
return function(...args) {
const key = JSON.stringify(args);
if (cache.has(key)) {
return cache.get(key);
}
const result = fn.apply(this, args);
cache.set(key, result);
return result;
};
}
// Example:
function slowFactorial(n) {
return n <= 1 ? 1 : n * slowFactorial(n - 1);
}
const fastFactorial = memoize(slowFactorial);
console.log(fastFactorial(10)); // computed
console.log(fastFactorial(10)); // cached
- Considerations:
- Key generation: JSON.stringify works for primitive args; for objects, consider weak maps keyed by object references.
- Cache invalidation: for long-running apps, unbounded cache growth can lead to memory issues; implement size limit or TTL.
- Context (this): if function uses this, memoize accordingly or bind context.
- Advanced:
- Use WeakMap for object arguments to avoid memory leaks.
- Multilevel argument patterns: nested maps keyed by each argument position.
- Citations: Common JS pattern; see MDN discussion on caching patterns. (developer.mozilla.org)
Modules & Tooling (Questions 36–40)
Question 36: Explain difference between ES modules (import/export) and CommonJS (require/module.exports).
Answer:
- CommonJS (Node.js legacy):
- Synchronous: const foo = require(‘foo’);
- module.exports or exports for exports.
- Modules loaded at runtime; cannot statically analyze usage easily.
- ES Modules (ESM):
- Syntax: import foo from ‘foo’; export function bar() {}.
- Static: imports/exports are statically analyzable by bundlers for tree-shaking.
- Asynchronous loading in browsers (with <script type=”module”>).
- Interop:
- Node supports both with .mjs or “type”:”module”; interop requires special handling.
- Benefits of ESM:
- Tree-shaking: remove unused exports for smaller bundles.
- Static analysis: tools can optimize code.
- Standardized across environments.
- Citations: MDN modules overview. (developer.mozilla.org)
Question 37: How does tree-shaking work in modern bundlers?
Answer:
- Definition:
- Remove unused code at build time to reduce final bundle size. Works best with ES modules due to static import/export analysis. (developer.mozilla.org)
- Mechanism:
- Bundler analyzes dependency graph: identifies exported functions/variables not referenced anywhere; excludes them from final bundle.
- Limitations:
- Dynamic imports or CommonJS modules hinder static analysis.
- Side-effectful modules must be marked so tree-shaker won’t remove them erroneously.
- Configuration:
- In Webpack: mode: ‘production’, optimization.usedExports, properly set sideEffects in package.json.
- Best Practices:
- Use ES module syntax.
- Avoid dynamic require calls.
- Citations: Webpack/tree-shaking documentation. (developer.mozilla.org)
Question 38: What is code splitting and why is it important?
Answer:
- Definition:
- Dividing application code into multiple bundles/chunks loaded on demand rather than a single large bundle. Improves initial load performance. (developer.mozilla.org)
- Approaches:
- Route-based: load code for each route only when user navigates.
- Component-based: load heavy components lazily (e.g., modals, charts).
- Vendor splitting: separate third-party libraries from application code.
- Implementation:
- With bundlers: dynamic import() returns a promise that loads chunk.
- In frameworks: React.lazy/Suspense, Vue async components.
- Benefits:
- Faster Time to Interactive (TTI) by reducing initial payload.
- Better caching: infrequently changing code in separate chunk stays cached.
- Considerations:
- Manage chunk loading states (loading spinners).
- Avoid too many small chunks causing extra network overhead.
- Citations: Bundler documentation on code splitting. (developer.mozilla.org)
Question 39: Explain how bundlers like Webpack handle dynamic imports.
Answer:
- Dynamic import():
- Returns a promise that resolves to the module.
- Bundler sees import(‘module-path’) and creates a separate chunk for that module.
- Webpack:
- On encountering import(), Webpack splits code at that point into a new chunk file.
- At runtime, import() triggers fetching the chunk asynchronously.
Example:
button.addEventListener('click', async () => {
const { heavyFunction } = await import('./heavyModule.js');
heavyFunction();
});
- Naming and Caching:
- Webpack can name chunks via magic comments: import(/* webpackChunkName: “heavy” */ ‘./heavyModule.js’).
- Use Cases:
- Lazy-load features, reduce initial bundle sizes.
- Pitfalls:
- Ensure error handling for failed loads.
- Consider prefetch/preload hints for UX improvements.
- Citations: Webpack dynamic import docs. (developer.mozilla.org)
Question 40: What is the purpose of Babel in a frontend build pipeline?
Answer:
- Transpilation:
- Converts modern JavaScript (ES6+/ESNext) into syntax supported by target browsers/environments. (developer.mozilla.org)
- Polyfilling:
- Via presets/plugins (e.g., @babel/preset-env, core-js), includes polyfills for missing features.
- Plugin Ecosystem:
- Optimize code transforms, JSX transpilation, plugin for class properties, etc.
- Integration:
- Used by bundlers (Webpack, Rollup) as loader or plugin.
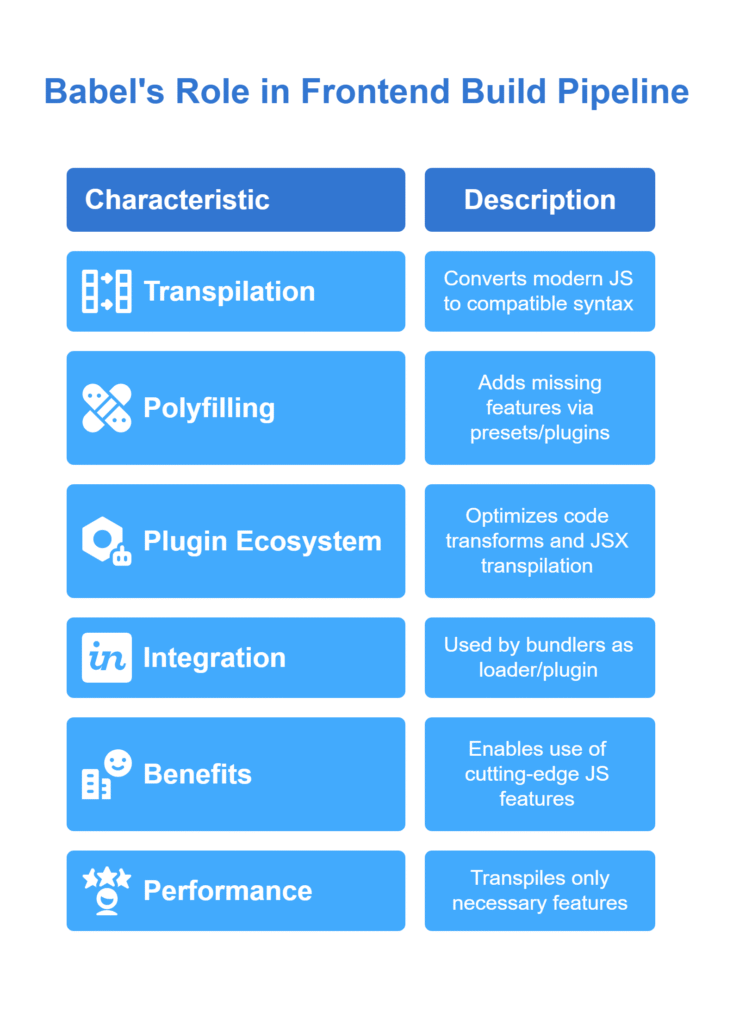
- Benefits:
- Write cutting-edge JS features without sacrificing browser compatibility.
- Performance Considerations:
- Only transpile necessary features based on target browsers configuration (browserslist).
- Avoid over-polyfilling for minimal bundle size.
- Citations: Babel documentation. (developer.mozilla.org)
Edge Cases & “Weird” JavaScript (Questions 41–45)
Question 41: What is the output of [] + {} and {} + []? Why?
Answer:
- Explanation:
- JavaScript uses type coercion for + between non-primitive types, converting operands to primitives (via valueOf/toString).
- [] + {}:
- [] coerces to ” (empty string).
- {} coerces to ‘[object Object]’.
- ” + ‘[object Object]’ yields “[object Object]”.
- {} + []:
- When parsed as statement, leading {} may be interpreted as block, but when explicitly: ({} + []):
- {} coerces to ‘[object Object]’.
- [] coerces to ”.
- ‘[object Object]’ + ” yields “[object Object]”.
- When parsed as statement, leading {} may be interpreted as block, but when explicitly: ({} + []):
- Caveats:
- JS parser nuances: standalone {} at line start is treated as block, not object literal.
- Best Practices:
- Avoid relying on such coercion; use explicit conversions when needed.
- Citations: MDN coercion rules. (developer.mozilla.org)
Question 42: Explain typeof NaN and why it’s that way.
Answer:
- typeof NaN yields “number”:
- In JavaScript, NaN stands for “Not-a-Number” but is categorized under number type per IEEE-754 floating-point representation. (developer.mozilla.org)
- Reason:
- IEEE-754 defines NaN as a special numeric value representing undefined or unrepresentable results (e.g., 0/0).
- Implications:
- To check for NaN, use Number.isNaN(value) rather than typeof.
Examples:
typeof NaN; // "number"
Number.isNaN(NaN); // true
isNaN('foo'); // true, but Number.isNaN('foo') is false
- Citations: MDN Number.isNaN, typeof operator. (developer.mozilla.org)
Question 43: What are the falsy values in JavaScript?
Answer:
- List of falsy values:
- false, 0, -0, 0n (BigInt zero), ” (empty string), null, undefined, NaN.
- Usage:
- In boolean contexts (e.g., if(value)), these evaluate to false.
- Pitfalls:
- Be cautious when checking values: e.g., if (!value) catches all falsy cases, not just null or undefined. For existence checks, prefer value == null or explicit checks.
- Citations: MDN falsy values. (developer.mozilla.org)
Question 44: Explain the difference between Object.freeze, Object.seal, and Object.preventExtensions.
Answer:
- Object.preventExtensions(obj):
- Prevents adding new properties to obj. Existing properties remain configurable, writable.
- Object.seal(obj):
- Prevents adding or removing properties. Existing properties become non-configurable but remain writable.
- Object.freeze(obj):
- Prevents adding, removing, or modifying existing properties. Makes properties non-configurable and non-writable (for data properties). For nested objects, freeze is shallow; nested objects remain mutable unless also frozen.
Examples:
const obj = { a: 1 };
Object.preventExtensions(obj);
obj.b = 2; // ignored or error in strict mode
obj.a = 10; // allowed
delete obj.a; // allowed
const obj2 = { a: 1 };
Object.seal(obj2);
obj2.b = 2; // ignored
obj2.a = 10; // allowed
delete obj2.a; // ignored
const obj3 = { a: 1 };
Object.freeze(obj3);
obj3.a = 10; // ignored
delete obj3.a; // ignored
- Use Cases:
- Immutable objects for safety.
- Sealing objects to prevent extension in API design.
- Citations: MDN Object methods. (developer.mozilla.org)
Question 45: How does the new keyword work under the hood?
Answer:
- Mechanism:
- A new empty object is created.
- The object’s [[Prototype]] is set to the constructor function’s prototype property.
- The constructor function is called with this bound to the new object, passing provided arguments.
- If constructor returns an object explicitly, that object is returned; otherwise, the newly created object is returned.
Example:
function Person(name) {
this.name = name;
}
Person.prototype.greet = function() {
console.log(`Hello, ${this.name}`);
};
const p = new Person('Alice');
// Under the hood:
// const obj = {}; obj.__proto__ = Person.prototype;
// const result = Person.call(obj, 'Alice');
// return typeof result === 'object' ? result : obj;
- Pitfalls:
- Forgetting to use new can cause this to refer to global or undefined (in strict mode).
- Alternatives:
- Factory functions avoid new pitfalls by returning object literal.
- Citations: MDN “new” operator. (developer.mozilla.org)
Frontend Framework / Browser-Related Scenarios (Questions 46–50)
Question 46: How would you handle hydration errors in an SSR app?
Answer:
- Context:
- Hydration: process where client-side JS attaches event handlers to server-rendered HTML.
- Common Errors:
- Mismatch between server-rendered markup and client-rendered Virtual DOM leading to warnings.
- Strategies:
- Ensure deterministic rendering: avoid code that produces different output on server vs client (e.g., using window-dependent code, random IDs, date/time).
- Use checks: render fallback UI until client-only data is available.
- Wrap browser-only logic inside useEffect (React) or equivalent to run only on client.
- For frameworks like Next.js: use dynamic imports with ssr: false for components that cannot render on server.
- Debugging:
- Compare server HTML vs client HTML; inspect hydration warnings in console.
- Use consistent data-fetching strategies between server and client.
- Citations: Framework docs (e.g., React, Next.js). (developer.mozilla.org)
Question 47: How would you implement lazy loading of components?
Answer:
- In React:
- Use React.lazy(() => import(‘./MyComponent’)) and wrap in <Suspense fallback={…}>.
- In Vue:
- const MyComponent = defineAsyncComponent(() => import(‘./MyComponent.vue’));
- General:
- Use dynamic import() to split code into chunks loaded on demand.
- Combine with route-based code splitting for page-level lazy loading.
- Use Cases:
- Large UI components (charts, heavy libraries) loaded only when needed.
- Handling Loading State:
- Provide fallback UI (spinner) while component loads.
- Prefetch hints: <link rel=”preload”> or bundler directives to fetch chunk ahead of time if likely needed.
- Citations: React and Vue docs on lazy loading. (developer.mozilla.org)
Question 48: What is virtual DOM? How is it different from the real DOM?
Answer:
- Virtual DOM:
- An in-memory lightweight representation of the UI (tree of virtual nodes) used by frameworks like React.
- Mechanism:
- On state change, framework creates new virtual DOM tree.
- Diff algorithm compares new tree with previous tree to identify minimal changes.
- Patches applied to real DOM in batch for performance.
- Benefits:
- Reduces direct DOM manipulations which can be expensive.
- Framework abstracts updates: you declare UI based on state; framework handles efficient updates.
- Differences:
- Virtual DOM operations are JS computations; then translate to real DOM updates.
- Real DOM interactions involve browser layout and repaint; minimization improves performance.
- Caveats:
- Virtual DOM diffing has overhead; for trivial apps, direct DOM may suffice.
- Understanding underlying real DOM behavior still critical for optimization.
- Citations: React documentation on reconciliation. (developer.mozilla.org)
Question 49: What’s the difference between server-side rendering (SSR) and client-side rendering (CSR)?
Answer:
- Server-Side Rendering (SSR):
- Server generates HTML for each request; browser receives fully rendered page.
- Pros: faster initial load (Time to First Paint), better SEO (search engines can index content), social previews.
- Cons: more server load, potential latency per request, complexity in state hydration.
- Client-Side Rendering (CSR):
- Server delivers minimal HTML and JS; browser runs JS to render UI.
- Pros: rich interactivity, SPA feel, reduced server responsibilities, caching advantages.
- Cons: slower initial load (JS parse/execute), possible SEO challenges (though modern crawlers handle JS), blank page until JS loads.
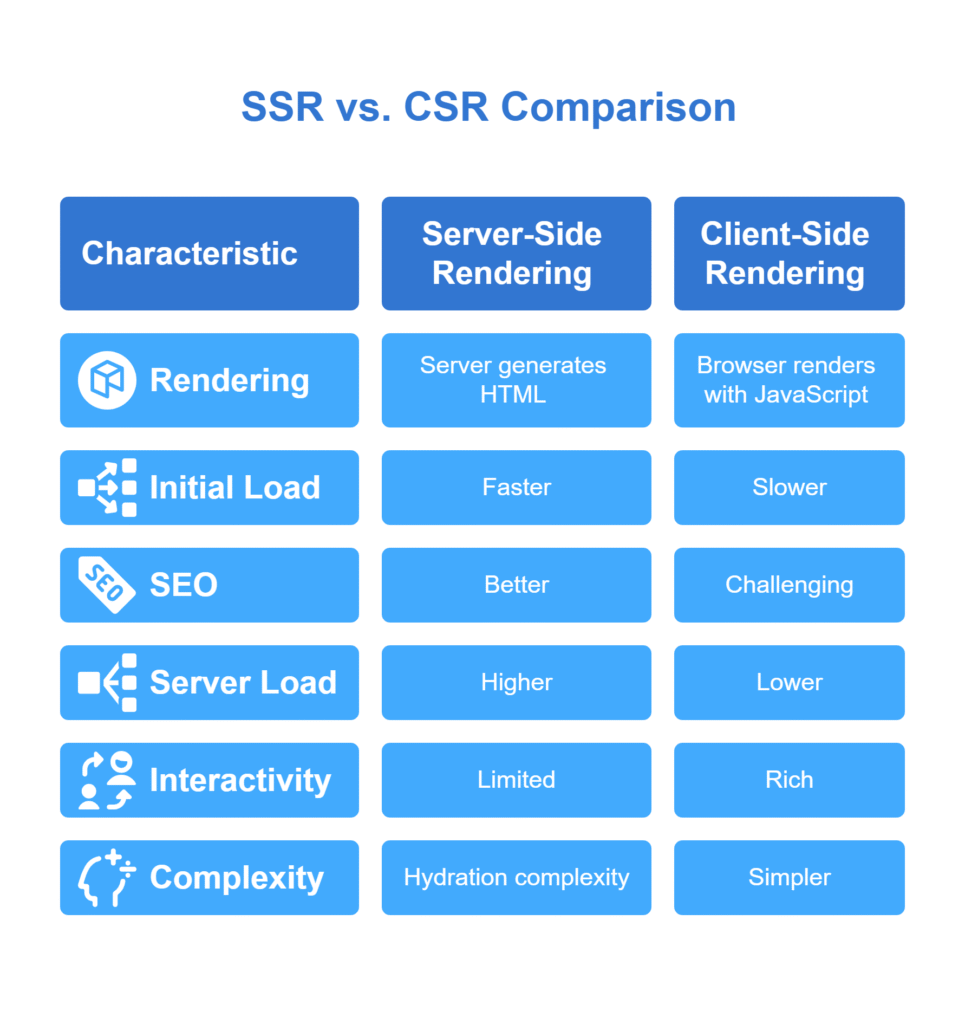
- Hybrid Approaches:
- Universal/isomorphic rendering: initial SSR, then hydrate on client (e.g., Next.js).
- Static site generation (SSG): generate pages at build time.
- Considerations:
- Choose based on application: marketing sites favor SSR/SSG; heavy dynamic apps might rely on CSR with code-splitting.
- Citations: MDN and framework docs on rendering strategies. (developer.mozilla.org)
Question 50: How would you handle cross-origin requests in the browser?
Answer:
- CORS (Cross-Origin Resource Sharing):
- Browser security mechanism enforcing same-origin policy; allows servers to specify allowed origins via headers.
- Server-Side Setup:
- Configure response headers, e.g., Access-Control-Allow-Origin: https://yourdomain.com or * for public APIs.
- For credentials (cookies/auth): Access-Control-Allow-Credentials: true plus explicit origin header, not *.
- Preflight requests (OPTIONS) for non-simple requests: server must respond with appropriate Access-Control-Allow-Methods and Access-Control-Allow-Headers.
- Client-Side:
- Use fetch or XMLHttpRequest; by default, browser enforces CORS. For cross-site requests with credentials: fetch(url, { credentials: ‘include’ }).
- Proxying:
- During development, use dev server proxy to avoid CORS issues.
- Security Considerations:
- Limit allowed origins; avoid overly permissive CORS that can leak sensitive data.
Example (Node/Express):
app.use((req, res, next) => {
res.header('Access-Control-Allow-Origin', 'https://example.com');
res.header('Access-Control-Allow-Methods', 'GET,POST,PUT,DELETE');
res.header('Access-Control-Allow-Headers', 'Content-Type,Authorization');
if (req.method === 'OPTIONS') {
return res.sendStatus(204);
}
next();
});
- Citations: MDN CORS documentation. (developer.mozilla.org)
Conclusion
Congratulations on reaching the end of this in-depth guide to Top 50 JavaScript Coding Interview Questions. By studying these questions and answers, you:
- Strengthened your grasp of core JS concepts, asynchronous patterns, browser internals, performance optimization, design patterns, and framework-related challenges.
- Learned to articulate reasoning clearly, an essential skill for technical interviews.
- Gained code examples and best practices that mirror real-world problem-solving scenarios.
Next Steps
- Practice Coding: Implement these solutions in an editor; then refactor to handle edge cases and optimize further.
- Mock Interviews: Explain your solutions verbally or with peers, focusing on clarity, trade-offs, and possible follow-up questions.
- Deep Dive into Official Docs: Revisit MDN references cited here to explore related topics and advanced nuances.
- Explore Advanced Topics: System design for front-end (microfrontends), performance budgets, WebAssembly basics.
- Stay Updated: JavaScript evolves; keep abreast of new ECMAScript proposals, browser features, and best practices by following MDN and TC39 updates.
By internalizing these patterns and concepts, you’ll be well-prepared to tackle JavaScript interview rounds at Google, Atlassian, Amazon, and beyond, showcasing both technical depth and real-world problem-solving skills.
Good luck with your interviews and happy coding!
FAQs
What core JavaScript topics should I master for coding interviews?
Focus on ES6+ fundamentals (let/const, arrow functions, destructuring, spread/rest), closures, prototype inheritance, event loop (microtasks vs. macrotasks), type coercion (== vs. ===), and error handling. Mastering these topics boosts your JavaScript interview preparation and demonstrates deep language understanding.
How can I practice real-world JavaScript problem-solving effectively?
Build small utilities that reflect on-the-job tasks: implement debounce/throttle, memoization, deep clone, LRU cache, and a pub/sub system. Solve coding challenges, explain your approach, handle edge cases, and optimize for complexity. This real-world practice strengthens interview readiness and showcases problem-solving skills.
What are best practices for asynchronous JavaScript questions in interviews?
Explain the event loop, Promise behavior (then/catch/finally), async/await patterns, and error handling with try/catch. Demonstrate sequencing versus parallel execution (Promise.all vs. sequential await). Emphasize avoiding unhandled rejections, preventing main-thread blocking, and writing clean async code for frontend performance.

DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00
Accelerate your Path to a Product based Career
Boost your career or get hired at top product-based companies by joining our expertly crafted courses. Gain practical skills and real-world knowledge to help you succeed.

Data Analytics
- 20+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 15+ Hands-on Live Projects
- Comprehensive Notes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 70% OFF
₹9,999.00 ₹2,999.00

SDE 360: Master DSA, System Design, AI & Behavioural
- 100+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 50% OFF
₹39,999.00 ₹19,999.00

Fast-Track to Full Spectrum Software Engineering
- 120+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- 12+ live Projects & Deployments
- Case Studies
- Access to Global Peer Community
Buy for 51% OFF
₹35,000.00 ₹16,999.00
DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00

Mastering Mern Stack (WEB DEVELOPMENT)
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 12+ Hands-on Live Projects & Deployments
- Comprehensive Notes & Quizzes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 53% OFF
₹15,000.00 ₹6,999.00

Mastering Data Structures & Algorithms
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests
- Access to Global Peer Community
- Topic-wise Quizzes
- Interview Prep Material
Buy for 40% OFF
₹9,999.00 ₹5,999.00
Reach Out Now
If you have any queries, please fill out this form. We will surely reach out to you.
Contact Email
Reach us at the following email address.
arun@getsdeready.com
Phone Number
You can reach us by phone as well.
+91-97737 28034
Our Location
Rohini, Sector-3, Delhi-110085
