Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
LLM Infrastructure: How AI Models Are Deployed at Scale
Have you ever wondered how massive AI models like GPT-4 or Llama power real-time applications without crashing under millions of users? Deploying large language models (LLMs) at scale is no small feat—it involves a symphony of hardware, software, and clever engineering. If you’re eager to dive deeper into AI technologies and stay updated with the latest free resources and course updates, sign up here to get exclusive access and keep your skills sharp.
In this post, we’ll unpack the intricacies of LLM infrastructure, from the nuts and bolts of hardware to cutting-edge scaling techniques. Whether you’re a developer, data scientist, or business leader eyeing AI integration, you’ll walk away with actionable insights to tackle your own deployments. Let’s break it down step by step.
Understanding LLMs and the Need for Scalable Infrastructure
Large language models are transformer-based AI systems trained on vast datasets to generate human-like text, code, and more. Models like Meta’s Llama 3.1 405B boast billions of parameters, enabling sophisticated tasks but demanding immense computational resources.
Why scale? Simple: real-world applications require low latency, high throughput, and reliability. For instance, a chatbot handling customer queries must respond in seconds, even during peak hours. Without proper infrastructure, you’d face skyrocketing costs or frustrating delays.
Key drivers for robust LLM infrastructure include:
- User Demand: Global AI adoption is surging, with the enterprise LLM market projected to grow from $5.9 billion in 2025 to $71.1 billion by 2035 at a 28.3% CAGR.
- Model Complexity: Larger models like GPT-4 require terabytes of memory for inference alone.
- Cost Efficiency: Deployment costs can reach thousands monthly; optimization is key to staying competitive.
To master this, start with foundational skills. For example, understanding data structures is crucial for efficient AI pipelines—explore our comprehensive DSA course to build that base.
Key Components of LLM Infrastructure
Building LLM infrastructure is like assembling a high-performance engine. It starts with hardware and software that work in harmony.
Hardware Essentials: GPUs, TPUs, and Beyond
Hardware is the backbone, handling the heavy lifting of training and inference.
- GPUs (Graphics Processing Units): Dominant for their parallel processing prowess. NVIDIA’s H100 GPUs, for example, are staples in LLM setups due to high memory bandwidth (up to 3 TB/s) and support for frameworks like PyTorch. Pros: Versatile, widely available, and scalable via clusters. Cons: High power consumption (e.g., 400W per A100 card).
- TPUs (Tensor Processing Units): Google’s custom chips optimized for tensor operations in neural networks. They shine in efficiency, consuming 200-250W per v4 chip while outperforming GPUs in tensor-heavy tasks like BERT training (1.7ms vs. 3.8ms on V100). Ideal for cloud-based deployments on Google Cloud, but limited to TensorFlow ecosystems.

Other options include AMD GPUs for cost savings and emerging accelerators like Grok-1 chips from xAI, tailored for inference. For large-scale setups, clusters of 16+ GPUs are common, connected via high-speed networks like NVLink or EFA.
If you’re venturing into hardware-accelerated web apps for AI, our web development course covers building scalable backends.
Software Frameworks for Serving LLMs
Once hardware is set, software frameworks handle model serving, optimizing for speed and reliability.
Popular ones include:
- NVIDIA Triton Inference Server: Supports multi-model serving with backends like TensorRT-LLM. Great for hybrid GPU/CPU setups, offering dynamic batching and model ensembles.
- vLLM: Focuses on high-throughput inference with PagedAttention, reducing memory by up to 50% for long sequences. OpenAI-compatible API makes it user-friendly.
- TensorFlow Serving: Ideal for TensorFlow models, providing versioning and A/B testing. Scales via Kubernetes for production.
- Text Generation Inference (TGI): Hugging Face’s tool for optimized serving, including flash-attention for faster processing.
- DeepSpeed-MII: Microsoft’s framework for low-latency inference, supporting load balancing across replicas.
- OpenLLM: Versatile for fine-tuned models, with adapter support and quantization.
- Ray Serve: Framework-agnostic, excels in distributed serving with native LangChain integration.
Choosing the right one? For edge deployments, try MLC LLM on consumer devices. Dive deeper with our master DSA, web dev, and system design course to architect these systems.
Deployment Strategies for LLMs
Deployment turns models into usable services. Options vary by scale and needs.
Cloud vs. On-Premises Deployment
- Cloud: Flexible and scalable. AWS EKS with Triton deploys Llama 3.1 405B across multi-node P5.48xlarge instances, using EFA for low-latency comms. Google Cloud TPUs offer managed scaling, while Azure integrates with OpenAI models. Benefits: Auto-scaling, pay-as-you-go (e.g., $4.50/hour for TPU v3). Drawbacks: Data privacy risks.
- On-Premises: For security-sensitive ops. Use Kubernetes clusters with NVIDIA GPUs. Costs upfront but control data flow. Hybrid models blend both for cost savings—up to 99.7% in some cases via optimization.
Containerization and Orchestration
Docker containerizes models for portability, while Kubernetes orchestrates scaling. Steps:
- Build a Docker image with the model and framework.
- Deploy via Helm charts on EKS.
- Use Horizontal Pod Autoscaler for demand-based scaling.
ensures reproducibility and handles failures gracefully.
Scaling Techniques for LLMs
Scaling means handling more requests without proportional cost hikes.
Parallelism Methods
- Data Parallelism (DP): Replicates models across devices for parallel processing.
- Tensor Parallelism (TP): Splits tensors across GPUs (e.g., TP=8 for Llama 405B).
- Pipeline Parallelism (PP): Divides layers across devices (e.g., PP=2 in multi-node setups).
- Hybrid: Combines for optimal balance, reducing sync overhead.
Optimization Techniques
- Quantization: Reduces precision (e.g., int8) to cut memory by 75%, using bitsandbytes.
- Continuous Batching: Dynamically batches requests mid-inference for 2-4x throughput.
- FlashAttention/PagedAttention: Optimizes attention layers, slashing latency.
These can drop costs from $10k/month to under $1k for medium-scale deployments.
For data science pros, our data science course teaches optimization in practice.
Challenges in Deploying LLMs at Scale
No rose without thorns—scaling LLMs brings hurdles.
- Memory and Compute: Models need 2TB+ GPU memory; solutions include sharding and quantization.
- Latency: Sequential generation causes delays; mitigate with continuous batching.
- Cost: Inference can cost $0.01-0.10 per 1k tokens; optimize to save 50-90%.
- Security/Privacy: Open-source models like Llama help avoid vendor lock-in.
- Real-Time Inference: High traffic bottlenecks; use ultra-low latency setups.
Expert quote: “Scaling LLM inference requires innovations in parallelism to meet real-time demands,” from Meta’s AI research.
Case Studies: Real-World Deployments
Learn from giants:
- AWS with Llama 3.1 405B: Multi-node EKS deployment using Triton and TensorRT-LLM. Sharded across 16 H100 GPUs, achieving high throughput with EFA networking. Metrics: Reduced time-to-first-token via optimizations.
- Google’s Gemini: Leverages TPUs for efficient scaling, outperforming competitors in benchmarks. Integrated with GCP for seamless inference.
- Meta’s LLaMA: Focuses on reproducibility and cost-sensitive deployment. Uses hybrid parallelism for production, handling billions of parameters on-premises.
- OpenAI’s GPT Series: Cloud-heavy with Azure, employing custom sharding for global scale. Challenges: Balancing cost with 50% market share erosion by 2025.
These showcase hybrid approaches yielding 2-5x efficiency gains.
Future Trends in LLM Infrastructure
Looking ahead, trends include:
- Hardware Specialization: New chips like xAI’s for inference, reducing costs 20-30%.
- Edge Deployment: Running LLMs on devices with MLC LLM for privacy.
- Sustainable AI: Energy-efficient TPUs and quantization to cut carbon footprints.
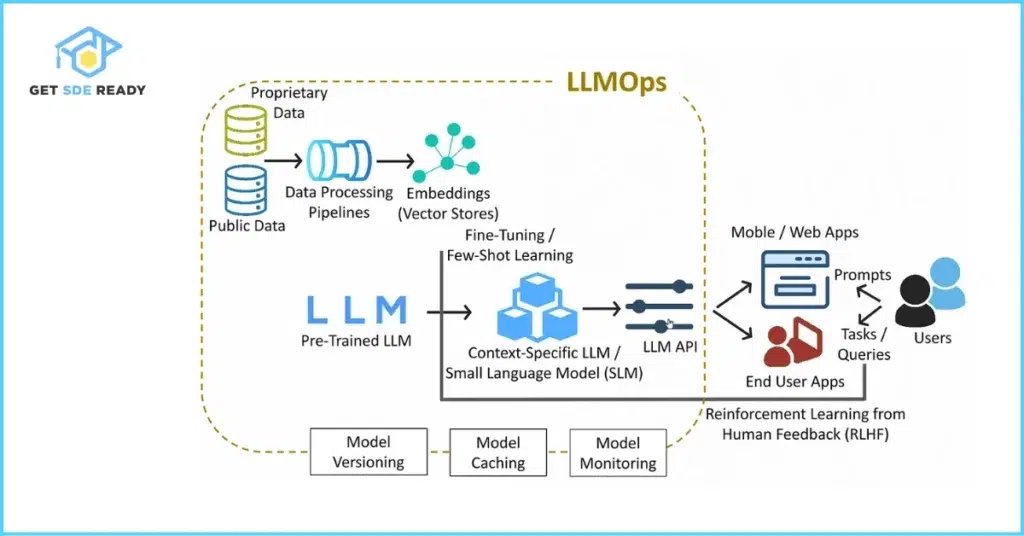
- MLOps Evolution: Automated pipelines with LLMOps for faster iterations.
- Smaller Models: SLMs like Phi-3 for efficient scaling without sacrificing performance.
The market? LLMs could hit $123 billion by 2034.
Best Practices and Actionable Advice
To deploy successfully:
- Assess Needs: Start small—prototype on cloud, then scale.
- Monitor Everything: Use Prometheus for metrics; aim for <500ms latency.
- Optimize Early: Quantize models and use continuous batching.
- Secure Deployments: Fine-tune open-source models for privacy.
- Test at Scale: Simulate traffic with tools like genai-perf.
Actionable step: Try a crash course in AI deployment—check our crash course for hands-on labs.
In conclusion, mastering LLM infrastructure unlocks AI’s full potential. Start experimenting today, and remember: the right setup can transform ideas into impactful solutions. What’s your next AI project? Share in the comments!
FAQs
What is LLM infrastructure?
LLM infrastructure refers to the hardware, software, and strategies for deploying large language models at scale, including GPUs, frameworks like Triton, and scaling techniques for efficient inference.
How do GPUs and TPUs differ in LLM deployment?
GPUs offer versatility and broad framework support for parallel tasks, while TPUs excel in tensor operations with lower power use, ideal for TensorFlow-based LLM serving in cloud environments.
What are common challenges in scaling LLMs?
Key challenges include high memory demands, latency in inference, rising costs, and security risks, often addressed through quantization, parallelism, and open-source models.
Which frameworks are best for serving LLMs?
Top frameworks include vLLM for high-throughput, Triton for multi-model support, and Ray Serve for distributed scaling, depending on your hardware and use case.

DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00
Accelerate your Path to a Product based Career
Boost your career or get hired at top product-based companies by joining our expertly crafted courses. Gain practical skills and real-world knowledge to help you succeed.

Data Analytics
- 20+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 15+ Hands-on Live Projects
- Comprehensive Notes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 70% OFF
₹9,999.00 ₹2,999.00

SDE 360: Master DSA, System Design, AI & Behavioural
- 100+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 50% OFF
₹39,999.00 ₹19,999.00

Fast-Track to Full Spectrum Software Engineering
- 120+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- 12+ live Projects & Deployments
- Case Studies
- Access to Global Peer Community
Buy for 51% OFF
₹35,000.00 ₹16,999.00
DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00

Mastering Mern Stack (WEB DEVELOPMENT)
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 12+ Hands-on Live Projects & Deployments
- Comprehensive Notes & Quizzes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 53% OFF
₹15,000.00 ₹6,999.00

Mastering Data Structures & Algorithms
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests
- Access to Global Peer Community
- Topic-wise Quizzes
- Interview Prep Material
Buy for 40% OFF
₹9,999.00 ₹5,999.00
Reach Out Now
If you have any queries, please fill out this form. We will surely reach out to you.
Contact Email
Reach us at the following email address.
arun@getsdeready.com
Phone Number
You can reach us by phone as well.
+91-97737 28034
Our Location
Rohini, Sector-3, Delhi-110085
