Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Difference Between Load Balancing and Failover Guide for Interviews and System Design
Introduction
In the fast-paced world of IT infrastructure, ensuring systems are both highly available and performant is a top priority for businesses, developers, and system administrators. Two cornerstone strategies for achieving this are load balancing and failover. While both contribute to system reliability and user satisfaction, they serve distinct purposes: load balancing optimizes performance by distributing workloads, while failover ensures continuity by switching to backup systems during failures. Understanding their differences is critical for designing scalable, resilient systems and excelling in technical interviews, particularly for roles in system design, DevOps, or network engineering.
This blog post dives deep into load balancing and failover, exploring their mechanisms, benefits, use cases, and technical nuances. We’ll provide practical examples, code snippets, and interview-focused insights to equip you with a thorough understanding. Whether you’re preparing for a technical interview, architecting a cloud-based application, or optimizing an existing system, this guide offers actionable knowledge to help you make informed decisions.
To get the latest updates on our courses related to system design, data science, or web development, make sure to sign up for our free courses and receive notifications.
What is Load Balancing?
Load balancing is the process of distributing network traffic or computational workloads across multiple servers to optimize resource utilization, maximize throughput, minimize response times, and prevent any single server from becoming a bottleneck. It’s a proactive strategy to enhance performance and scalability, particularly for systems handling high traffic volumes.
How Load Balancing Works
A load balancer acts as a traffic manager, sitting between clients (e.g., users’ browsers or mobile apps) and backend servers. It receives incoming requests and routes them to the most suitable server based on algorithms or predefined rules. This ensures efficient workload distribution and prevents server overload.
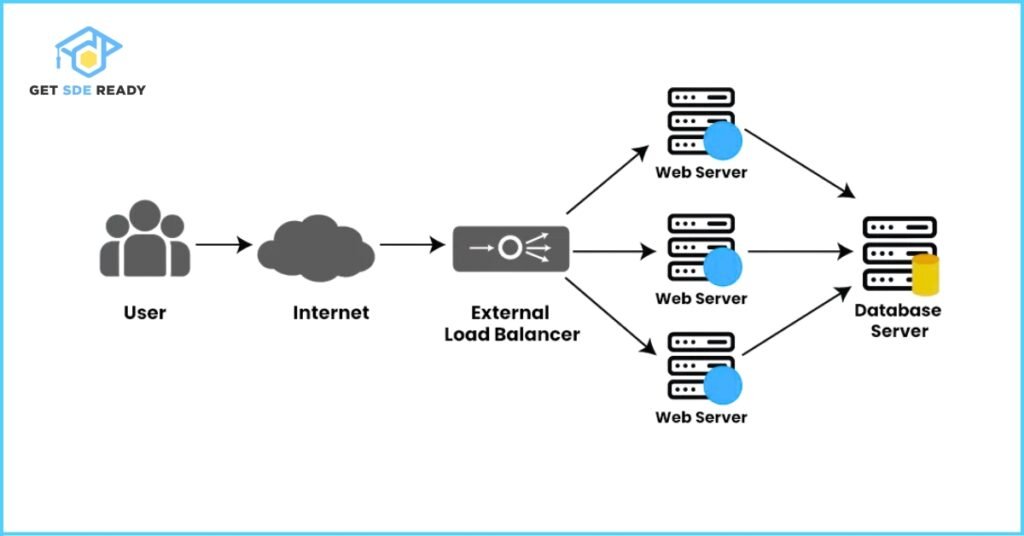
Load Balancing Algorithms
Load balancers employ various algorithms to distribute traffic effectively:
- Round-Robin: Distributes requests sequentially across all servers, ideal for servers with similar capabilities.
- Least Connections: Routes requests to the server with the fewest active connections, optimizing for real-time load.
- IP Hash: Assigns requests based on the client’s IP address, ensuring consistent routing for session persistence.
- Weighted Round-Robin: Assigns more requests to servers with higher capacity, based on predefined weights.
- Resource-Based: Considers server metrics like CPU, memory, or response time to direct traffic to the least-loaded server.
For example, in a web application, a load balancer might distribute HTTP requests across multiple web servers. If one server is handling many requests, the load balancer redirects new requests to a less busy server, maintaining smooth performance.
Types of Load Balancing
Load balancing can be implemented in several ways, each suited to different needs:
- Hardware Load Balancers: Physical devices like F5 Networks’ BIG-IP or Cisco’s Application Control Engine, offering high performance but at a higher cost and less flexibility.
- Software Load Balancers: Applications like NGINX, HAProxy, or Apache, running on standard hardware or virtual machines, providing cost-effective and flexible solutions.
- Cloud Load Balancers: Managed services like AWS Elastic Load Balancer (ELB), Azure Load Balancer, or Google Cloud Load Balancing, designed for scalability and integration with cloud ecosystems.
Example: NGINX Load Balancing Configuration
Here’s a basic NGINX configuration for load balancing across three backend servers using the round-robin algorithm:
http {
upstream backend {
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
listen 80;
location / {
proxy_pass http://backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
}
This configuration defines an upstream block with three servers, and NGINX distributes incoming requests across them. For more advanced setups, you can add weights or health checks.
Benefits of Load Balancing
- Improved Performance: Distributes traffic to prevent server overload, reducing latency and improving user experience.
- Enhanced Reliability: Redirects traffic away from failed servers, minimizing downtime.
- Scalability: Enables seamless addition of servers to handle increased traffic.
- Efficient Resource Use: Maximizes server utilization, avoiding idle or overworked resources.
Use Cases for Load Balancing
- Web Applications: E-commerce platforms like Amazon or social media sites like Twitter use load balancing to handle millions of concurrent users.
- Database Clusters: Distributing queries across multiple database nodes, as seen in MySQL or MongoDB clusters.
- Microservices Architectures: Balancing API requests across microservices in cloud-native applications.
- Content Delivery Networks (CDNs): Distributing content requests across edge servers for faster delivery.
For further reading, see Cloudflare’s guide on load balancing.
What is Failover?
Failover is a reactive mechanism that ensures service continuity by switching to a standby server, database, or system when the primary resource fails due to hardware issues, software crashes, or other disruptions. Its primary goal is to minimize downtime and maintain service availability, especially for mission-critical applications.
How Failover Works
In a failover setup, a primary (active) system handles all requests, while one or more standby (passive) systems remain synchronized through replication or mirroring. Health checks or monitoring tools detect primary system failures, triggering an automatic or manual switch to the standby system.
For example, in a database cluster, if the primary database server fails, the failover mechanism promotes a replica to take over, ensuring data access continues uninterrupted.
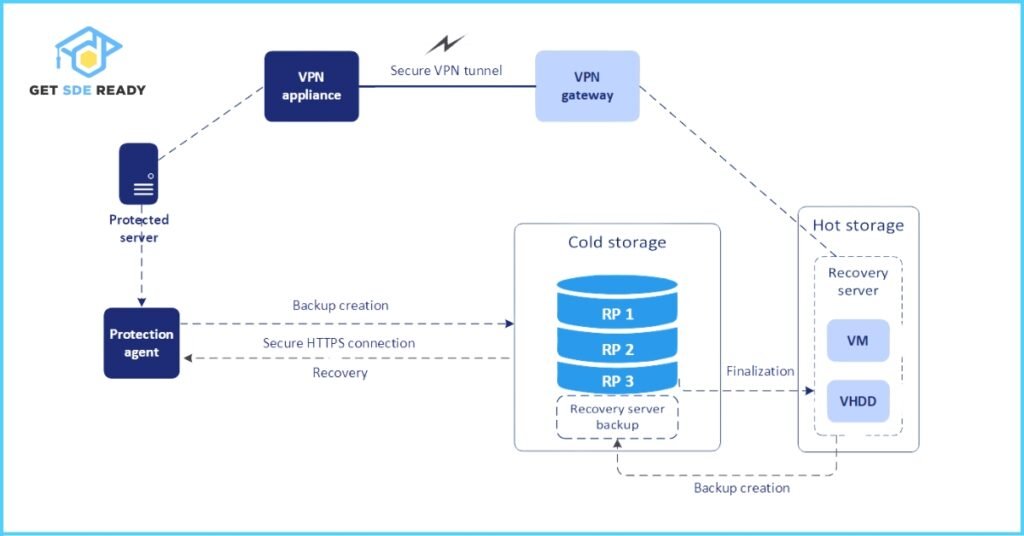
Types of Failover
- Manual Failover: Requires human intervention to switch to the standby system, suitable for non-critical systems where brief downtime is acceptable.
- Automatic Failover: Uses monitoring tools to detect failures and switch to the standby system instantly, ideal for critical applications requiring minimal downtime.
Example: MySQL Failover with Replication
Here’s a simplified example of setting up MySQL replication for failover:
Configure Primary Server:
-- On primary server (my.cnf)
[mysqld]
server-id=1
log_bin=mysql-bin
- Configure Replica Server:
-- On replica server (my.cnf)
[mysqld]
server-id=2
relay-log=mysql-relay-bin
2. Set Up Replication:
-- On primary server
GRANT REPLICATION SLAVE ON *.* TO 'replica_user'@'%' IDENTIFIED BY 'password';
FLUSH PRIVILEGES;
SHOW MASTER STATUS;
-- On replica server
CHANGE MASTER TO
MASTER_HOST='primary_host',
MASTER_USER='replica_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=123;
START SLAVE;
3. Failover Script (Python Example):
import mysql.connector
import time
def check_primary(host):
try:
conn = mysql.connector.connect(host=host, user='user', password='password', database='test')
conn.close()
return True
except:
return False
def promote_replica(replica_host):
conn = mysql.connector.connect(host=replica_host, user='user', password='password', database='test')
cursor = conn.cursor()
cursor.execute("STOP SLAVE;")
cursor.execute("RESET MASTER;")
conn.commit()
cursor.close()
conn.close()
print(f"Promoted {replica_host} to primary")
primary_host = "primary.example.com"
replica_host = "replica.example.com"
while True:
if not check_primary(primary_host):
print("Primary failed, initiating failover...")
promote_replica(replica_host)
break
time.sleep(5)
4. This script monitors the primary server and promotes the replica if the primary fails. In production, tools like MySQL’s Group Replication or third-party solutions like ProxySQL are often used for automated failover.
Benefits of Failover
- High Availability: Ensures services remain accessible during primary system failures.
- Minimal Downtime: Automatic failover can switch to a backup in seconds, reducing disruptions.
- Data Protection: Maintains data availability through synchronized replicas, critical for databases.
Use Cases for Failover
- Database Systems: Ensuring continuous access to critical data in financial or healthcare systems.
- Application Servers: Maintaining availability for business-critical applications like ERP systems.
- Network Infrastructure: Routers or switches with backup units to ensure network connectivity.
- Cloud Services: Using multi-region deployments to failover to another region during outages.
For more details, see GeeksforGeeks’ failover mechanisms.
Key Differences Between Load Balancing and Failover
Load balancing and failover are complementary but distinct strategies. The following table provides a detailed comparison:
Aspect | Load Balancing | Failover |
Purpose | Optimize performance by distributing workloads | Ensure reliability by switching to a backup |
Operation | Distributes traffic across multiple active servers | Switches from primary to standby server |
Configuration | Active-active (all servers handle requests) | Active-passive (standby idle until needed) |
Focus | Performance, scalability, resource utilization | Availability, uptime, disaster recovery |
Complexity | Complex due to algorithms and traffic management | Simpler but requires replication and monitoring |
Cost | Higher due to multiple active servers | Costly due to idle standby systems |
Failure Handling | Redirects traffic from failed servers | Activates standby system upon primary failure |
Performance Impact | Improves response times and throughput | No performance improvement, focuses on continuity |
Purpose: Performance vs. Reliability
- Load Balancing: Proactively enhances system performance by evenly distributing workloads, preventing bottlenecks. It’s ideal for high-traffic scenarios where speed is critical.
- Failover: Reactively ensures reliability by switching to a backup when the primary fails, prioritizing service continuity over performance optimization.
Operation: Distributing vs. Switching
- Load Balancing: Continuously distributes traffic across multiple servers in real-time, using algorithms to optimize load distribution.
- Failover: Activates only during a failure, redirecting all traffic to a standby system until the primary is restored.
Configuration: Active-Active vs. Active-Passive
- Load Balancing: Operates in an active-active configuration, where all servers process requests simultaneously, maximizing resource use.
- Failover: Uses an active-passive configuration, where the primary handles all requests, and the standby remains idle until needed.
Complexity and Cost
- Load Balancing: Requires sophisticated setup, including algorithm configuration, health checks, and monitoring. Costs are higher due to multiple active servers and load balancing infrastructure.
- Failover: Simpler to implement but requires maintaining standby systems, which can be costly as they remain unused until a failure. Data replication adds complexity and cost.
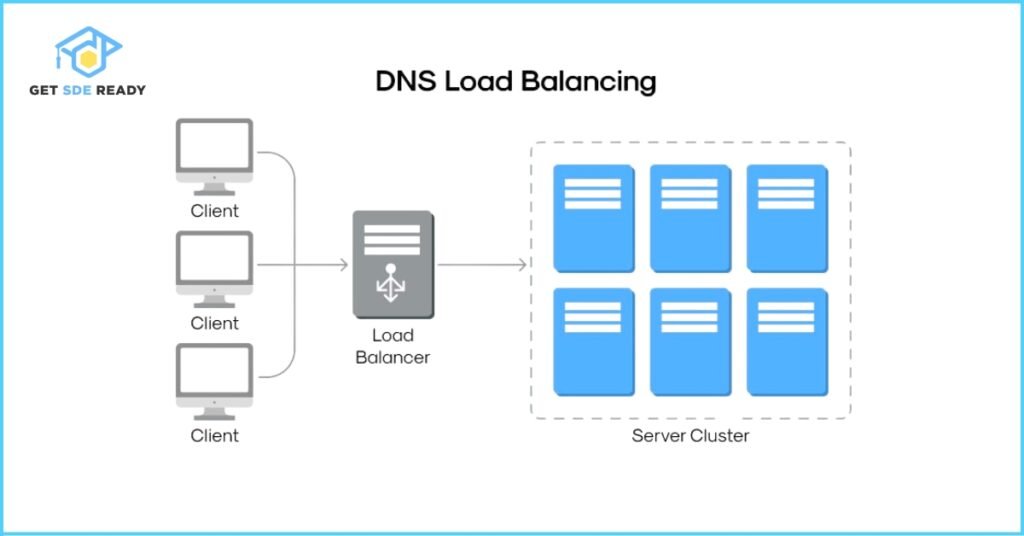
DNS-Based Considerations
DNS-based load balancing and failover, as noted by Imperva, have unique challenges:
- DNS Load Balancing: Uses DNS to distribute traffic (e.g., round-robin or geo-location-based). It’s not load-aware, leading to potential uneven traffic distribution, and relies on DNS TTL, which can delay load redistribution.
- DNS Failover: Switches to a backup server during failure but is delayed by DNS TTL (e.g., 20 minutes to an hour), causing potential service degradation. ISP caching can further complicate timely failover.
When to Use Load Balancing vs. Failover
Choosing between load balancing and failover—or combining them—depends on your system’s requirements, traffic patterns, and availability needs.
When to Use Load Balancing
- High Traffic Volumes: Essential for systems like e-commerce platforms (e.g., Amazon) or streaming services (e.g., Netflix), where load balancing prevents server overload.
- Performance Optimization: When low latency and high throughput are priorities, load balancing ensures fast, consistent performance.
- Scalability Needs: For systems expecting traffic growth, load balancing allows seamless scaling by adding servers.
When to Use Failover
- Critical Applications: For systems where downtime is unacceptable, such as healthcare (e.g., patient record systems) or financial applications (e.g., trading platforms), failover ensures continuous availability.
- Disaster Recovery: Protects against hardware failures, power outages, or natural disasters by switching to a backup system.
- Minimal Downtime: Automatic failover minimizes disruptions, critical for applications where even seconds of downtime are costly.
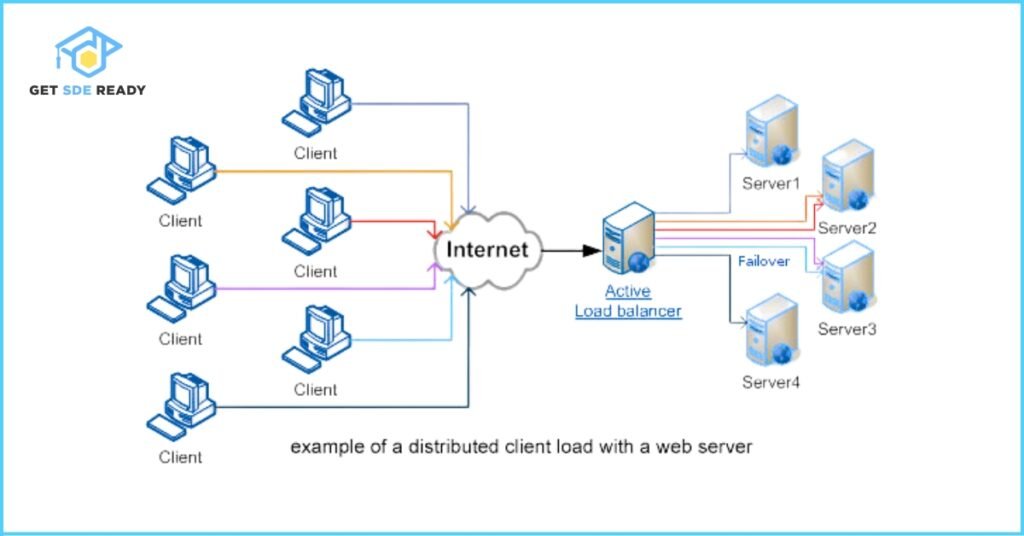
Combining Load Balancing and Failover
Modern systems often integrate both for comprehensive high availability:
- Hybrid Approach: A load balancer distributes traffic across multiple active servers, and each server has a failover replica. If a server fails, the load balancer removes it from the pool, and the failover mechanism activates the replica.
- Example: A cloud-based application using AWS ELB distributes traffic across EC2 instances in multiple availability zones. Each instance has a failover replica, and Amazon RDS uses automated failover for database instances.
Real-World Example: E-Commerce Platform
Consider an e-commerce platform during a Black Friday sale:
- Load Balancing: An AWS Application Load Balancer distributes millions of user requests across multiple EC2 instances, ensuring fast page loads and checkout processes.
- Failover: If an EC2 instance fails, the load balancer redirects traffic to healthy instances. Additionally, the database (e.g., Amazon Aurora) has a read replica that automatically takes over if the primary database fails.
This combination ensures both performance under heavy traffic and reliability during failures.
Load Balancing and Failover in Technical Interviews
In technical interviews for roles like system design, DevOps, or network engineering, load balancing and failover are common topics. Interviewers assess your ability to explain these concepts, design systems using them, and understand their trade-offs.
Common Interview Questions
- What is load balancing, and why is it important?
- Answer: Load balancing distributes traffic across multiple servers to optimize performance, enhance reliability, and enable scalability. It prevents server overload, reduces latency, and ensures efficient resource use. Example: A website like YouTube uses load balancing to handle billions of video requests daily.
- How does a load balancer decide where to send traffic?
- Answer: It uses algorithms like round-robin, least connections, or IP hash to route traffic based on server load, capacity, or session persistence. Example: NGINX’s least connections algorithm sends requests to the server with the fewest active connections.
- What is failover, and how does it differ from load balancing?
- Answer: Failover switches to a backup system when the primary fails, ensuring availability, while load balancing distributes traffic for performance. Failover is reactive (active-passive), while load balancing is proactive (active-active).
- Design a system with load balancing and failover for a web application.
- Answer: Use a cloud load balancer (e.g., AWS ELB) to distribute traffic across multiple web servers in different availability zones. Configure health checks to remove failed servers. Implement database failover with a primary-replica setup (e.g., MySQL replication). Draw a diagram showing the load balancer, web servers, and database with failover replicas.
- What are the trade-offs of DNS-based load balancing vs. application-layer load balancing?
- Answer: DNS-based load balancing is simpler but lacks load awareness and is delayed by DNS TTL. Application-layer load balancing (e.g., NGINX, HAProxy) offers dynamic routing based on server health but requires more complex setup. Example: DNS-based load balancing may cause uneven traffic distribution due to caching.
Tips for Answering Interview Questions
- Simplify Complex Concepts: Explain load balancing and failover in clear, concise terms, avoiding jargon unless necessary.
- Use Real-World Examples: Reference systems like Netflix (load balancing for streaming) or banking systems (failover for transactions).
- Discuss Trade-offs: Highlight pros (e.g., performance for load balancing, reliability for failover) and cons (e.g., cost, complexity).
- Show Practical Experience: Mention tools like NGINX, AWS ELB, or MySQL replication if you’ve used them.
- Draw Diagrams: In system design interviews, sketch architectures showing load balancers, servers, and failover mechanisms.
Example System Design Answer
Question: Design a highly available web application.
Answer:
- Architecture: Use a cloud provider like AWS. Deploy an Application Load Balancer (ALB) to distribute traffic across EC2 instances in multiple availability zones (e.g., us-east-1a, us-east-1b).
- Load Balancing: Configure the ALB with round-robin or least connections, enabling health checks to detect and remove failed instances.
- Failover: Set up Amazon RDS with a primary database and a read replica in a different availability zone. Enable automated failover to promote the replica if the primary fails.
- Monitoring: Use AWS CloudWatch to monitor server health and trigger failover or scaling actions.
- Scalability: Implement Auto Scaling to add/remove EC2 instances based on traffic demand.
Diagram:
[Clients] –> [AWS ALB] –> [EC2 Instance 1 | EC2 Instance 2]
–> [RDS Primary | RDS Replica (Failover)]
This design ensures performance (via load balancing) and reliability (via failover).
Advanced Considerations
DNS-Based Load Balancing and Failover
DNS-based load balancing and failover, as discussed by Imperva, have limitations:
- DNS Load Balancing: Uses DNS records to distribute traffic (e.g., round-robin or geo-location). It’s not load-aware, leading to uneven distribution, and DNS TTL delays traffic redistribution (e.g., 20 minutes to an hour).
- DNS Failover: Switches to a backup server during failure but is delayed by DNS TTL and ISP caching, potentially causing service degradation. Workarounds like low TTL can negatively impact performance.
For enterprise-grade solutions, Global Server Load Balancing (GSLB) or application-layer load balancers are preferred for dynamic, load-aware traffic management.
Performance Metrics and Monitoring
To optimize load balancing and failover:
- Load Balancing Metrics: Monitor server response times, CPU/memory usage, and connection counts. Tools like AWS CloudWatch or Prometheus can track these metrics.
- Failover Metrics: Measure failover time (time to switch to backup) and data consistency between primary and standby systems. Ensure replication lag is minimal (e.g., <1 second for databases).
- Health Checks: Implement frequent health checks (e.g., HTTP pings every 5 seconds) to detect failures quickly.
Cost Considerations
- Load Balancing Costs: Higher due to multiple active servers and load balancer infrastructure (e.g., AWS ELB costs $0.0225/hour + $0.008/GB processed).
- Failover Costs: Significant due to idle standby systems and replication overhead. For example, maintaining a database replica in AWS RDS can double database costs.
- Optimization: Use cloud auto-scaling to reduce costs during low traffic and reserve standby systems for critical applications only.
For more detailed information on system design and optimization strategies, explore our Master DSA, Web Development, and System Design Courses.
Conclusion
Load balancing and failover are indispensable for building resilient, high-performance systems. Load balancing optimizes resource utilization and scalability by distributing workloads across multiple servers, while failover ensures uninterrupted service by switching to backups during failures. By understanding their differences—proactive performance optimization versus reactive reliability—you can design systems that meet both performance and availability goals.
For technical interviews, mastering these concepts involves explaining their mechanisms, providing real-world examples, and designing systems that integrate both strategies. In practice, combining load balancing and failover, as seen in cloud architectures like AWS or Azure, offers the best of both worlds: fast, scalable performance and robust disaster recovery.
FAQs
What is load balancing in system design?
Load balancing distributes traffic across multiple servers to enhance performance, minimize response times, and avoid server overload.
How does failover work in a database system?
Failover ensures that if the primary database fails, a standby replica is promoted to maintain data availability.
When should I choose failover over load balancing?
Choose failover for critical systems requiring continuous availability, while load balancing is ideal for optimizing performance and scalability.
What algorithms are used in load balancing?
Common algorithms include round-robin, least connections, IP hash, and weighted round-robin to distribute traffic efficiently.
Can load balancing and failover work together?
Yes, combining load balancing and failover offers both performance optimization and reliability, as seen in cloud architectures like AWS.

DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00
Accelerate your Path to a Product based Career
Boost your career or get hired at top product-based companies by joining our expertly crafted courses. Gain practical skills and real-world knowledge to help you succeed.

Data Analytics
- 20+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 15+ Hands-on Live Projects
- Comprehensive Notes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 70% OFF
₹9,999.00 ₹2,999.00

SDE 360: Master DSA, System Design, AI & Behavioural
- 100+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 50% OFF
₹39,999.00 ₹19,999.00

Fast-Track to Full Spectrum Software Engineering
- 120+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- 12+ live Projects & Deployments
- Case Studies
- Access to Global Peer Community
Buy for 51% OFF
₹35,000.00 ₹16,999.00
DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 52% OFF
₹25,000.00 ₹11,999.00

Mastering Mern Stack (WEB DEVELOPMENT)
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 12+ Hands-on Live Projects & Deployments
- Comprehensive Notes & Quizzes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 53% OFF
₹15,000.00 ₹6,999.00

Mastering Data Structures & Algorithms
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests
- Access to Global Peer Community
- Topic-wise Quizzes
- Interview Prep Material
Buy for 40% OFF
₹9,999.00 ₹5,999.00
Reach Out Now
If you have any queries, please fill out this form. We will surely reach out to you.
Contact Email
Reach us at the following email address.
arun@getsdeready.com
Phone Number
You can reach us by phone as well.
+91-97737 28034
Our Location
Rohini, Sector-3, Delhi-110085
