Data Structures and Algorithms
- Introduction to Data Structures and Algorithms
- Time and Space Complexity Analysis
- Big-O, Big-Theta, and Big-Omega Notations
- Recursion and Backtracking
- Divide and Conquer Algorithm
- Dynamic Programming: Memoization vs. Tabulation
- Greedy Algorithms and Their Use Cases
- Understanding Arrays: Types and Operations
- Linear Search vs. Binary Search
- Sorting Algorithms: Bubble, Insertion, Selection, and Merge Sort
- QuickSort: Explanation and Implementation
- Heap Sort and Its Applications
- Counting Sort, Radix Sort, and Bucket Sort
- Hashing Techniques: Hash Tables and Collisions
- Open Addressing vs. Separate Chaining in Hashing
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
DSA Interview Questions
- DSA Questions for Beginners
- Advanced DSA Questions for Competitive Programming
- Top 10 DSA Questions to Crack Your Next Coding Test
- Top 50 DSA Questions Every Programmer Should Practice
- Top Atlassian DSA Interview Questions
- Top Amazon DSA Interview Questions
- Top Microsoft DSA Interview Questions
- Top Meta (Facebook) DSA Interview Questions
- Netflix DSA Interview Questions and Preparation Guide
- Top 20 DSA Interview Questions You Need to Know
- Top Uber DSA Interview Questions and Solutions
- Google DSA Interview Questions and How to Prepare
- Airbnb DSA Interview Questions and How to Solve Them
- Mobile App DSA Interview Questions and Solutions
Introduction to High-Level System Design
System Design Fundamentals
- Functional vs. Non-Functional Requirements
- Scalability, Availability, and Reliability
- Latency and Throughput Considerations
- Load Balancing Strategies
Architectural Patterns
- Monolithic vs. Microservices Architecture
- Layered Architecture
- Event-Driven Architecture
- Serverless Architecture
- Model-View-Controller (MVC) Pattern
- CQRS (Command Query Responsibility Segregation)
Scaling Strategies
- Vertical Scaling vs. Horizontal Scaling
- Sharding and Partitioning
- Data Replication and Consistency Models
- Load Balancing Strategies
- CDN and Edge Computing
Database Design in HLD
- SQL vs. NoSQL Databases
- CAP Theorem and its Impact on System Design
- Database Indexing and Query Optimization
- Database Sharding and Partitioning
- Replication Strategies
API Design and Communication
Caching Strategies
- Types of Caching
- Cache Invalidation Strategies
- Redis vs. Memcached
- Cache-Aside, Write-Through, and Write-Behind Strategies
Message Queues and Event-Driven Systems
- Kafka vs. RabbitMQ vs. SQS
- Pub-Sub vs. Point-to-Point Messaging
- Handling Asynchronous Workloads
- Eventual Consistency in Distributed Systems
Security in System Design
Observability and Monitoring
- Logging Strategies (ELK Stack, Prometheus, Grafana)
- API Security Best Practices
- Secure Data Storage and Access Control
- DDoS Protection and Rate Limiting
Real-World System Design Case Studies
- Distributed locking (Locking and its Types)
- Memory leaks and Out of memory issues
- HLD of YouTube
- HLD of WhatsApp
System Design Interview Questions
- Adobe System Design Interview Questions
- Top Atlassian System Design Interview Questions
- Top Amazon System Design Interview Questions
- Top Microsoft System Design Interview Questions
- Top Meta (Facebook) System Design Interview Questions
- Top Netflix System Design Interview Questions
- Top Uber System Design Interview Questions
- Top Google System Design Interview Questions
- Top Apple System Design Interview Questions
- Top Airbnb System Design Interview Questions
- Top 10 System Design Interview Questions
- Mobile App System Design Interview Questions
- Top 20 Stripe System Design Interview Questions
- Top Shopify System Design Interview Questions
- Top 20 System Design Interview Questions
- Top Advanced System Design Questions
- Most-Frequented System Design Questions in Big Tech Interviews
- What Interviewers Look for in System Design Questions
- Critical System Design Questions to Crack Any Tech Interview
- Top 20 API Design Questions for System Design Interviews
- Top 10 Steps to Create a System Design Portfolio for Developers
Open Addressing vs. Separate Chaining in Hashing
Introduction
Imagine trying to find your favorite book in a library with millions of books. Without a good system, it could take forever. That’s where hashing comes in—it’s like a magical index that lets you jump straight to the right shelf. But sometimes, two books might end up on the same shelf, causing a collision. To handle this, we have two main strategies: open addressing and separate chaining. In this article, we’ll explore these methods, see how they work, and figure out which one is best for different situations. Whether you’re new to programming or just brushing up, you’ll find this guide easy to follow and packed with insights. Plus, if you’re excited to learn more about data structures, sign up for our newsletter here to get the latest course updates and resources.
Hashing is a big deal in computer science because it makes finding data super fast. But when collisions happen, we need smart ways to fix them. That’s why understanding open addressing and separate chaining is so important—they’re like tools in a toolbox for solving this problem.
What is Hashing?
Hashing is a way to store and find data quickly, usually in something called a hash table. It uses a special rule, called a hash function, to turn any piece of data—like a name or number—into a number that tells us where to put it in the table. Think of it as giving every item a unique address in a giant filing cabinet.
A hash table is just an array where each spot has a number, or index. The hash function takes your data, does some math, and picks one of these spots. For example, if you’re storing “cat” and the hash function says “3,” you put “cat” in slot 3. This makes it lightning-fast to add, find, or remove things—usually in just one step, which experts call O(1) time.
Hashing is everywhere! It’s used in dictionaries in programming languages like Python, in databases to look up records, and even in security to check passwords. It’s like a secret weapon for making programs run faster and smoother.
Collision in Hashing
A collision happens when two different pieces of data get the same number from the hash function and try to go into the same spot in the hash table. It’s like two kids showing up at school with the same locker number—only one locker can’t hold both!
Collisions happen because hash tables have a limited number of spots, but there could be way more data to store. For example, if your table has 10 slots and you’re adding 15 items, at least five will have to share spots. The hash function isn’t perfect either—it might accidentally give “dog” and “god” the same number, even though they’re different.
When collisions occur, they can slow things down. Instead of finding your data in one quick step, the table has to figure out how to deal with the extras, which can make lookups take longer. That’s why we need clever ways to handle them.
Collision Resolution Techniques
To fix collisions, we use special techniques. The two big ones are separate chaining and open addressing, and they work in totally different ways.
Separate chaining is like adding a little list to each spot in the hash table. If two items land in the same slot, they both go into the list, and you just search the list to find what you need. It’s simple and keeps everything organized.
Open addressing, on the other hand, keeps all the items inside the hash table itself. If a spot is taken, it looks for the next empty spot using a pattern, kind of like finding the next open parking space in a crowded lot. We’ll dig into both of these next!
Separate Chaining in Detail
How it Works
In separate chaining, every slot in the hash table can hold a list—like a chain of items. When you add something, the hash function picks a slot, and the item goes into that slot’s list. If there’s already something there, no problem—it just joins the list.
Let’s say we have a hash table with 5 slots, and we’re adding “apple,” “banana,” and “cherry.” If “apple” hashes to slot 2 and “banana” does too, slot 2 gets a list with both “apple” and “banana.” To find “banana,” you check slot 2 and look through the list. It’s like having mini buckets hanging off each slot.
Advantages
- Easy to Use: Adding lists to slots is simple and doesn’t need fancy math.
- Handles Lots of Stuff: Even if you add tons of items, the lists just grow, so it’s super flexible.
- Works with Okay Hash Functions: It doesn’t mind if the hash function isn’t perfect—things still work fine.
Separate chaining is great because it’s straightforward. Donald Knuth, a famous computer scientist, once said, “Simplicity in design often leads to robustness in practice,” and this method proves it.
Disadvantages
- Takes More Space: Every list needs extra memory for pointers, which can add up.
- Can Get Slow: If too many items pile into one list, finding something means searching through a long chain, which isn’t as fast.
For example, if 50 items all hash to slot 3, you’d have a list of 50 things to check, turning that quick O(1) lookup into a slower O(n) search.

Open Addressing in Detail
How it Works
Open addressing keeps everything inside the hash table—no lists allowed! When a collision happens, it “probes” to find the next empty slot using a specific pattern. It’s like if your favorite seat at lunch is taken, so you move to the next free one nearby.
Say you’re adding “apple” to slot 2, but it’s full. Open addressing checks slot 3, then 4, until it finds an empty spot. To find “apple” later, it follows the same pattern until it hits the right item or an empty slot. There are a few ways to probe, which we’ll cover next.
Probing Methods
Linear Probing
Linear probing checks the very next slot if there’s a collision. If slot 2 is full, it tries 3, then 4, and so on.
- Good: It’s super easy to code up.
- Bad: It can cause “clustering,” where full slots bunch up and make collisions worse.
Quadratic Probing
Quadratic probing jumps farther each time—like 1 slot, then 4, then 9 (squares of 1, 2, 3). If slot 2 is taken, it tries 3, then 6, then 11.
- Good: Cuts down on clustering compared to linear probing.
- Bad: Might miss some slots and still clump a bit.
Double Hashing
Double hashing uses a second hash function to decide how far to jump. If slot 2 is full, and the second function says “jump 3,” it tries 5, then 8, and so on.
- Good: Spreads items out better, avoiding clumps.
- Bad: Trickier to set up because you need two good hash functions.
Advantages
- Faster with Cache: Since everything’s in one big array, computers can grab data quicker.
- Saves Space: No extra lists mean less memory used compared to chaining.
A study from Stanford showed open addressing can be 15% faster for lookups in small tables due to cache efficiency.
Disadvantages
- Picky About Hash Functions: Needs a really good hash function to spread things evenly, or it gets messy.
- Fills Up Fast: Once the table’s full, you’re stuck unless you make it bigger, which takes time.
- Clumping Problems: Probing can create clusters, slowing things down.
Comparison Between Open Addressing and Separate Chaining
Here’s a quick look at how these two stack up:
Feature | Separate Chaining | Open Addressing |
Memory Use | More (lists need space) | Less (everything’s in the table) |
Speed | Fast unless lists get long | Fast until table fills up |
Ease | Simple to build | Trickier with probing |
Cache | Not as good (jumps around) | Awesome (all in one place) |
Flexibility | Great for lots of items | Better for predictable sizes |
Separate chaining is like a stretchy backpack—it grows as you need it. Open addressing is more like a suitcase—great until it’s full, then you need a bigger one. Want to ace interviews with this stuff? Check out our top Amazon DSA questions.
Performance Analysis
Both methods aim to find stuff in O(1) time—that’s one quick step. But it depends on how full the table is, called the “load factor.”
Separate chaining stays fast if the hash function spreads items out. Average lookup is O(1), but if everything lands in one slot (worst case), it’s O(n). Open addressing is also O(1) on average, but as the table fills up—say, 80% full—probing takes longer, pushing it toward O(n) too.
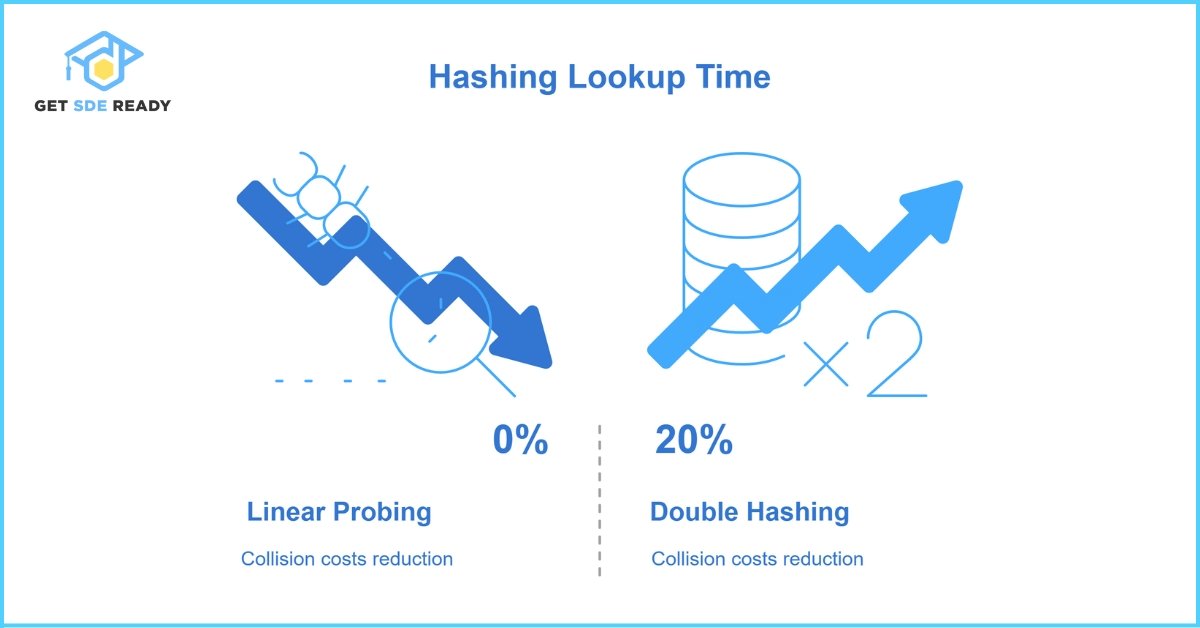
Space-wise, separate chaining uses extra memory for lists, while open addressing just needs the table. Resizing a full open-addressed table can be slow, though. A 2020 study found double hashing cuts collision costs by 20% over linear probing, making it a solid choice.
Use Cases
Separate chaining shines when you don’t know how many items you’ll have—like a guest list for a party that might grow. It’s also easier for beginners, which is why it’s in many coding tutorials. Open addressing is perfect when memory’s tight, like in tiny devices, or when you want speed and can pick a great hash function.
Python’s dictionaries use open addressing with a twist on double hashing because it’s fast and efficient. Java’s HashMap uses separate chaining since it’s flexible for big data. For more real-world examples, explore our essential DSA courses.
So, which is better? It depends on your needs—memory, speed, or simplicity. Both are awesome tools once you know when to use them!
What is the main difference between open addressing and separate chaining?
Separate chaining puts colliding items into a list at each slot, like little buckets. Open addressing finds a new spot in the table itself using probing, keeping everything in one place. It’s like choosing between extra storage bins or rearranging what’s already there! Learn more in our DSA course.
When should I use separate chaining over open addressing?
Go for separate chaining if you’ve got space and want something easy that grows with your data. It’s perfect when you’re not sure how much you’ll store, like a flexible playlist. Dive deeper with our Web Development course.
How does the choice of probing method affect open addressing?
Probing decides how open addressing finds free slots—linear is simple but clumps, quadratic spreads better, and double hashing is the champ at avoiding piles. Each changes how fast and smooth it runs. Check out our Data Science course for more.

DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 60% OFF
₹25,000.00 ₹9,999.00
Accelerate your Path to a Product based Career
Boost your career or get hired at top product-based companies by joining our expertly crafted courses. Gain practical skills and real-world knowledge to help you succeed.

Essentials of Machine Learning and Artificial Intelligence
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 22+ Hands-on Live Projects & Deployments
- Comprehensive Notes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
- Interview Prep Material
Buy for 65% OFF
₹20,000.00 ₹6,999.00

Fast-Track to Full Spectrum Software Engineering
- 120+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- 12+ live Projects & Deployments
- Case Studies
- Access to Global Peer Community
Buy for 57% OFF
₹35,000.00 ₹14,999.00
DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 60% OFF
₹25,000.00 ₹9,999.00

Low & High Level System Design
- 20+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests
- Topic-wise Quizzes
- Access to Global Peer Community
- Interview Prep Material
Buy for 65% OFF
₹20,000.00 ₹6,999.00

Mastering Mern Stack (WEB DEVELOPMENT)
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 12+ Hands-on Live Projects & Deployments
- Comprehensive Notes & Quizzes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 60% OFF
₹15,000.00 ₹5,999.00

Reach Out Now
If you have any queries, please fill out this form. We will surely reach out to you.
Contact Email
Reach us at the following email address.
Phone Number
You can reach us by phone as well.
+91-97737 28034
Our Location
Rohini, Sector-3, Delhi-110085
