Introduction to Data Replication in Distributed Systems
In today’s fast-paced world of distributed systems, efficiently managing vast amounts of data is critical for application success. Replication in databases is a fundamental technique that enhances data availability, reliability, and performance across multiple machines. Whether you are designing a highly available application or setting up a disaster recovery plan, implementing effective data replication strategies is key to building reliable and scalable systems.
Why is Data Replication Needed in Distributed Systems?
As applications grow in scale, relying on a single database server becomes inefficient and leads to potential bottlenecks. Distributed data systems address this challenge by spreading data across multiple machines. This improves:
Scalability
Scaling systems to accommodate increasing workloads requires distributing data effectively.
Availability
Data remains accessible at all times, even if some servers experience crashes.
Reduced Latency
Serving users from geographically closer replicas minimizes response time and boosts user experience.
Scalability Approaches: Vertical Scaling vs. Horizontal Scaling
When scaling a system, two primary approaches emerge:
1. Vertical Scaling
This involves upgrading the hardware (CPU, RAM) of a single machine. While this approach is straightforward, it comes with limitations such as hardware constraints and high costs.
2. Horizontal Scaling
Horizontal scaling adds more machines to the system, spreading the workload across multiple nodes. This approach is more flexible, fault-tolerant, and cost-effective. Replication plays a crucial role in horizontal scaling by distributing data across various nodes for better performance and fault tolerance.
How Data Replication Works: An Essential Overview
Replication is a data copying mechanism where data from one machine is replicated to another to provide redundancy and improve read performance. The benefits of replication include:
Ensuring service availability during failures.
Reducing latency by distributing read requests across multiple replicas.
Improving overall system reliability with backup copies of data.
Types of Replication Architectures
There are several replication strategies to consider, each with its pros and cons.
1. Single Leader Replication
In this model, one node (the leader) handles all write operations, while replicas (followers) keep copies of the data.
Pros:
Strong consistency.
Easy conflict resolution.
Cons:
Potential bottleneck if the leader fails or becomes overwhelmed.
2. Multi-Leader Replication
Multiple nodes accept write operations, making this architecture useful for geographically distributed systems.
Advantages:
Enhanced write availability.
Improved regional performance.
Disadvantages:
Conflicts can arise, leading to data inconsistency.
3. Leaderless (Peer-to-Peer) Replication
In this decentralized model, any node can handle both read and write operations, making it fault-tolerant and eliminating single points of failure.
Synchronization Methods: Balancing Speed and Consistency
Replication can be either synchronous or asynchronous, each with distinct trade-offs:
Synchronous Replication
Data is written to all replicas before the write is acknowledged, guaranteeing strong consistency.
Pros:
Strong consistency.
Ensures data integrity.
Cons:
Increased latency.
Risk: If one replica is slow, it can slow down the entire system.
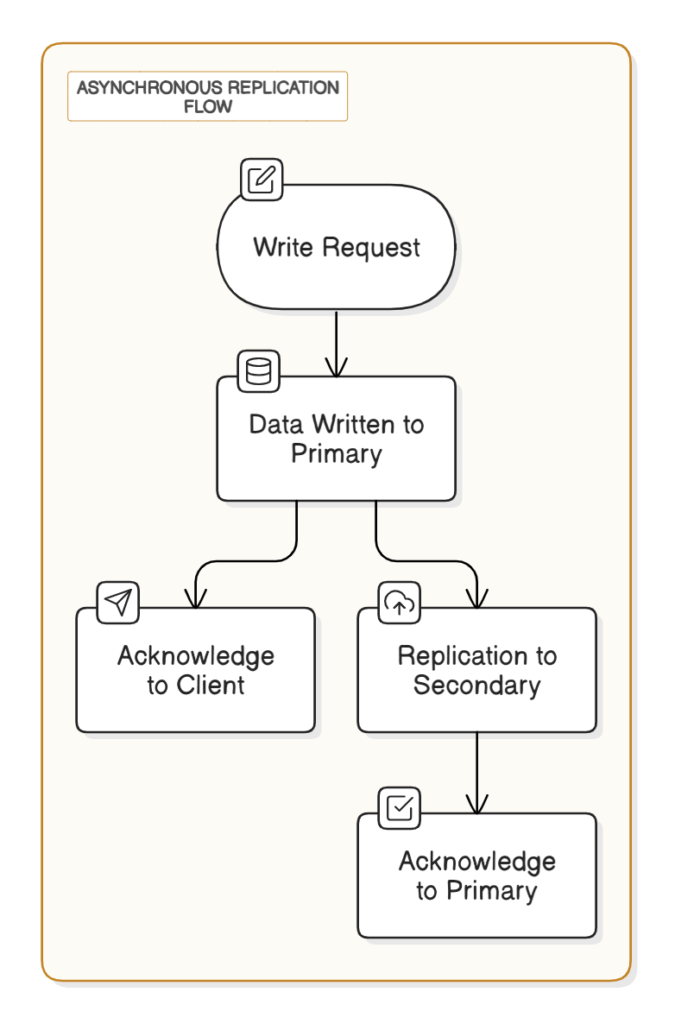
Asynchronous Replication
In this method, write requests return immediately while replication happens in the background.
Pros:
Optimized performance and scalability.
Cons:
Stale data may occur if replication lags.
Risk: Potential data loss if the leader fails before replication completes.
Replica Management: Handling Failures and Scaling
Effective replica management is essential for system reliability and availability. Key strategies include:
Dynamic Scaling: Add or remove replicas in real-time to meet demand.
Automatic Failover: Automatically promote a replica to leader status if the primary node fails.
Consistency Mechanisms: Use quorum-based writes or versioning to resolve conflicts.
Challenges in Data Replication
While replication significantly enhances system reliability, it comes with its own set of challenges:
Replication Lag: This can lead to stale reads, where replicas are not up-to-date.
Data Loss: Asynchronous replication can result in data loss if the leader crashes before replication completes.
Conflict Resolution: Multi-leader and leaderless architectures require advanced conflict resolution mechanisms to handle data discrepancies.
Consistency vs. Availability: Following the CAP Theorem, systems typically have to choose between prioritizing strong consistency or high availability.
Conclusion: Best Practices for Choosing a Replication Strategy
Replication is a vital strategy for building fault-tolerant, scalable distributed systems. Choosing the right replication architecture—single leader, multi-leader, or leaderless—depends on the system’s needs in terms of consistency, availability, and latency. With an understanding of the different replication strategies, synchronization trade-offs, and failure management techniques, engineers can design systems that scale well and maintain high performance.
This insightful blog post is authored by Abhishek Kumar, who brings his expertise and deep understanding of the topic to provide valuable perspectives.
Boost your career or get hired at top product-based companies by joining our expertly crafted courses. Gain practical skills and real-world knowledge to help you succeed.