Introduction to High-Level System Design
System Design Fundamentals
- Functional vs. Non-Functional Requirements
- Scalability, Availability, and Reliability
- Latency and Throughput Considerations
- Load Balancing Strategies
Architectural Patterns
- Monolithic vs. Microservices Architecture
- Layered Architecture
- Event-Driven Architecture
- Serverless Architecture
- Model-View-Controller (MVC) Pattern
- CQRS (Command Query Responsibility Segregation)
Scaling Strategies
- Vertical Scaling vs. Horizontal Scaling
- Sharding and Partitioning
- Data Replication and Consistency Models
- Load Balancing Strategies
- CDN and Edge Computing
Database Design in HLD
- SQL vs. NoSQL Databases
- CAP Theorem and its Impact on System Design
- Database Indexing and Query Optimization
- Database Sharding and Partitioning
- Replication Strategies
API Design and Communication
Caching Strategies
- Types of Caching
- Cache Invalidation Strategies
- Redis vs. Memcached
- Cache-Aside, Write-Through, and Write-Behind Strategies
Message Queues and Event-Driven Systems
- Kafka vs. RabbitMQ vs. SQS
- Pub-Sub vs. Point-to-Point Messaging
- Handling Asynchronous Workloads
- Eventual Consistency in Distributed Systems
Security in System Design
Observability and Monitoring
- Logging Strategies (ELK Stack, Prometheus, Grafana)
- API Security Best Practices
- Secure Data Storage and Access Control
- DDoS Protection and Rate Limiting
Real-World System Design Case Studies
- Distributed locking (Locking and its Types)
- Memory leaks and Out of memory issues
- HLD of YouTube
- HLD of WhatsApp
System Design Interview Questions
- Adobe System Design Interview Questions
- Top Atlassian System Design Interview Questions
- Top Amazon System Design Interview Questions
- Top Microsoft System Design Interview Questions
- Top Meta (Facebook) System Design Interview Questions
- Top Netflix System Design Interview Questions
- Top Uber System Design Interview Questions
- Top Google System Design Interview Questions
- Top Apple System Design Interview Questions
- Top Airbnb System Design Interview Questions
- Top 10 System Design Interview Questions
- Mobile App System Design Interview Questions
- Top 20 Stripe System Design Interview Questions
- Top Shopify System Design Interview Questions
- Top 20 System Design Interview Questions
- Top Advanced System Design Questions
- Most-Frequented System Design Questions in Big Tech Interviews
- What Interviewers Look for in System Design Questions
- Critical System Design Questions to Crack Any Tech Interview
- Top 20 API Design Questions for System Design Interviews
- Top 10 Steps to Create a System Design Portfolio for Developers
Introduction to High-Level System Design
System Design Fundamentals
- Functional vs. Non-Functional Requirements
- Scalability, Availability, and Reliability
- Latency and Throughput Considerations
- Load Balancing Strategies
Architectural Patterns
- Monolithic vs. Microservices Architecture
- Layered Architecture
- Event-Driven Architecture
- Serverless Architecture
- Model-View-Controller (MVC) Pattern
- CQRS (Command Query Responsibility Segregation)
Scaling Strategies
- Vertical Scaling vs. Horizontal Scaling
- Sharding and Partitioning
- Data Replication and Consistency Models
- Load Balancing Strategies
- CDN and Edge Computing
Database Design in HLD
- SQL vs. NoSQL Databases
- CAP Theorem and its Impact on System Design
- Database Indexing and Query Optimization
- Database Sharding and Partitioning
- Replication Strategies
API Design and Communication
Caching Strategies
- Types of Caching
- Cache Invalidation Strategies
- Redis vs. Memcached
- Cache-Aside, Write-Through, and Write-Behind Strategies
Message Queues and Event-Driven Systems
- Kafka vs. RabbitMQ vs. SQS
- Pub-Sub vs. Point-to-Point Messaging
- Handling Asynchronous Workloads
- Eventual Consistency in Distributed Systems
Security in System Design
Observability and Monitoring
- Logging Strategies (ELK Stack, Prometheus, Grafana)
- API Security Best Practices
- Secure Data Storage and Access Control
- DDoS Protection and Rate Limiting
Real-World System Design Case Studies
- Distributed locking (Locking and its Types)
- Memory leaks and Out of memory issues
- HLD of YouTube
- HLD of WhatsApp
System Design Interview Questions
- Adobe System Design Interview Questions
- Top Atlassian System Design Interview Questions
- Top Amazon System Design Interview Questions
- Top Microsoft System Design Interview Questions
- Top Meta (Facebook) System Design Interview Questions
- Top Netflix System Design Interview Questions
- Top Uber System Design Interview Questions
- Top Google System Design Interview Questions
- Top Apple System Design Interview Questions
- Top Airbnb System Design Interview Questions
- Top 10 System Design Interview Questions
- Mobile App System Design Interview Questions
- Top 20 Stripe System Design Interview Questions
- Top Shopify System Design Interview Questions
- Top 20 System Design Interview Questions
- Top Advanced System Design Questions
- Most-Frequented System Design Questions in Big Tech Interviews
- What Interviewers Look for in System Design Questions
- Critical System Design Questions to Crack Any Tech Interview
- Top 20 API Design Questions for System Design Interviews
- Top 10 Steps to Create a System Design Portfolio for Developers
Top 20 DSA Interview Questions You Need to Know
Welcome to an in‐depth guide on the top 20 DSA interview questions that every aspiring software developer must master. In today’s competitive tech environment, a strong grasp of Data Structures and Algorithms (DSA) is not just an advantage—it’s a necessity. Whether you are preparing for your first interview or brushing up on advanced concepts, this article is designed to walk you through essential questions and detailed explanations to boost your confidence and performance. If you’re looking to stay ahead in your learning journey, check out our free courses and updates to get the latest insights delivered right to your inbox.
This comprehensive article is crafted in simple, engaging language, making complex concepts accessible even to beginners. We include practical examples, statistics, quotes from renowned sources, and useful tables to help you understand each concept clearly. As you read, you’ll notice integrated recommendations for related topics to broaden your learning scope. Enjoy the journey to mastering DSA and elevating your interview skills!
Core DSA Concepts and Interview Strategies
Understanding the core concepts of Data Structures and Algorithms is the first step toward acing your technical interviews. In this section, we discuss the fundamentals that are frequently touched upon during interviews, along with proven strategies to solve problems efficiently. Whether you’re dealing with arrays, linked lists, trees, or graphs, having a solid foundation helps you tackle a wide range of challenges. Experts suggest that having a clear strategy for analyzing time and space complexity can set you apart from other candidates.
Interviewers often look for candidates who not only know the theory but can also apply it practically. It is essential to be comfortable with both the theoretical underpinnings and the coding implementations of each topic. Here are a few strategies to prepare for DSA interviews:
- Practice Coding: Regularly solve problems on platforms like LeetCode, HackerRank, or CodeSignal.
- Analyze Complexity: Always explain the time and space complexity of your solutions.
- Understand Trade-offs: Compare different data structures to choose the most efficient one for a given problem.
- Mock Interviews: Simulate interview conditions to improve your problem-solving speed.
Below is a table that compares some commonly used data structures:
Data Structure | Average Time Complexity (Search) | Advantages | Disadvantages |
Array | O(1) | Fast access, simple to use | Fixed size, costly insertions |
Linked List | O(n) | Dynamic size, ease of insertion | Slow access, extra memory overhead |
Stack | O(1) | Simple LIFO operations | Limited access pattern |
Queue | O(1) | FIFO operations, efficient processing | Limited direct access |
Hash Table | O(1) average | Fast lookup, dynamic size | Possibility of collisions |
By regularly revisiting these core principles and practicing various problems, you will be better prepared to answer in-depth interview questions related to DSA. Additionally, sharpening your problem-solving strategies will allow you to tackle even the most challenging questions with confidence.
Also Read: Low-Level Design of YouTube Recommendations
Top 20 DSA Interview Questions
Below, we dive into the top 20 questions that frequently appear in DSA interviews. Each question is broken down into detailed explanations, practical examples, and clear bullet points to ensure you understand not just the answer but also the reasoning behind it.
Question 1: What is an Array?
Arrays are one of the simplest and most commonly used data structures. They allow you to store a fixed-size sequential collection of elements of the same type. In an interview, you may be asked to explain the advantages and limitations of arrays as well as to implement basic operations like insertion, deletion, and traversal.
Arrays are praised for their ability to provide constant time access to any element, as the memory location is directly computed using the index. However, their fixed size can be a limitation when dealing with dynamic data sets, which is why alternatives such as dynamic arrays (e.g., Python lists) are often used.
Key points:
- Contiguous memory allocation
- O(1) access time
- Fixed size, but dynamic arrays overcome this
Example table comparing array properties:
Property | Value |
Access Time | O(1) |
Insertion (end) | O(1)* |
Insertion (middle) | O(n) |
Memory Layout | Contiguous |
*Note: Insertion at the end can be O(1) if there is spare capacity.
Question 2: What is a Linked List?
A linked list is a data structure in which elements, known as nodes, are linked together using pointers. Unlike arrays, linked lists allow for dynamic memory allocation, making it easy to insert or remove elements without shifting other elements.
Linked lists come in different forms: singly linked lists, doubly linked lists, and circular linked lists. Each type offers different advantages in terms of traversal and memory efficiency.
Highlights:
- Dynamic size and efficient insertion/deletion
- Non-contiguous memory allocation
- Variations include singly, doubly, and circular linked lists
Bullet points for operations:
- Insertion: O(1) if the insertion point is known
- Deletion: O(1) for head, O(n) for arbitrary nodes
- Traversal: O(n) for searching an element
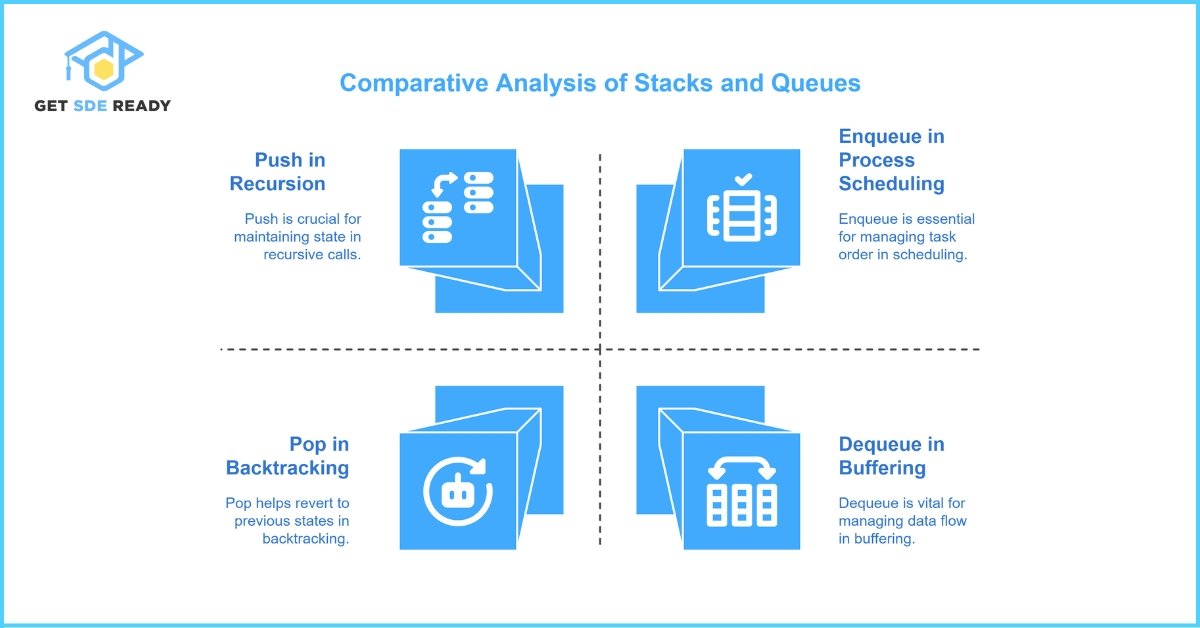
Question 3: What is a Stack and Queue?
Both stacks and queues are abstract data types that serve specific purposes in computer science. A stack follows a Last In, First Out (LIFO) approach, whereas a queue uses a First In, First Out (FIFO) methodology.
Stacks are widely used in scenarios such as function calls and undo mechanisms, while queues are crucial in scheduling algorithms and breadth-first search (BFS) in graphs.
Core differences:
- Stack:
- Operations: Push, Pop, Peek
- Use cases: Recursion, backtracking
- Operations: Push, Pop, Peek
- Queue:
- Operations: Enqueue, Dequeue, Front
- Use cases: Process scheduling, buffering
- Operations: Enqueue, Dequeue, Front
Both structures are fundamental for various algorithms, and understanding them is key to solving many interview problems.
Question 4: What is a Tree?
Trees are hierarchical data structures that consist of nodes connected by edges, with one node designated as the root. They are used to represent hierarchical relationships such as file systems, organizational structures, or even decision-making processes.
In interviews, you may be asked to explain binary trees, binary search trees (BST), and balanced trees such as AVL or Red-Black trees. The efficiency of operations like search, insert, and delete often depends on the tree’s balance.
Key features:
- Rooted structure: Single starting point for traversal
- Child nodes: Each node may have one or more children
- Balanced vs. Unbalanced: Impacts performance significantly
Bullet points for tree types:
- Binary Tree: Each node has up to two children
- BST: Left subtree holds smaller values, right subtree larger values
- Balanced Trees: Maintain height balance for efficiency
Question 5: What is a Graph?
Graphs are complex data structures used to represent pairwise relationships between objects. They consist of nodes (vertices) and edges connecting these nodes, and can be either directed or undirected.
Graphs are fundamental in computer science, especially in problems involving networks, social connections, and pathfinding. In interviews, you might be required to implement graph traversal algorithms such as Depth First Search (DFS) or Breadth First Search (BFS).
Important aspects:
- Vertices and Edges: Core components of graphs
- Directed vs. Undirected: Different relationship types
- Weighted Graphs: Include weights for edges, useful in shortest path problems
Quick summary in bullet points:
- DFS: Deep traversal using recursion or stack
- BFS: Level-wise traversal using a queue
- Applications: Social networks, mapping, recommendation systems
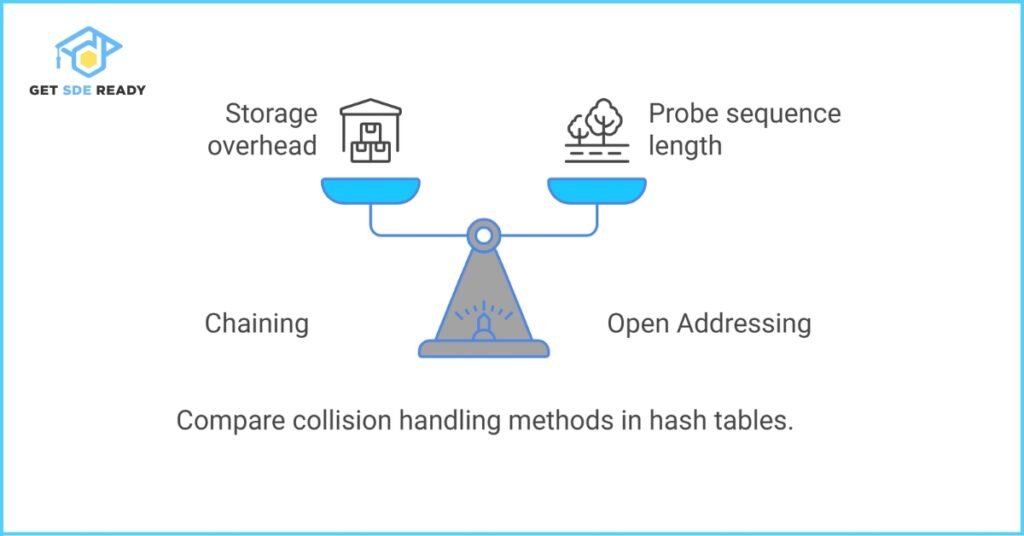
Question 6: Explain Hashing and Hash Tables
Hashing is a technique to convert a large amount of data into a fixed-size value, known as a hash code, which can be used for indexing and retrieval. Hash tables use this method to store key-value pairs and allow for average-case constant time complexity for search, insert, and delete operations.
In interviews, discussing hash functions, collision resolution techniques (like chaining and open addressing), and the overall performance of hash tables is common.
Key discussion points:
- Hash Function: Converts keys into array indices
- Collision Handling: Chaining vs. open addressing
- Efficiency: Average-case O(1) operations, but worst-case O(n) in poor implementations
Bullet points:
- Simple and effective for lookup
- Depends on the quality of the hash function
Widely used in databases and caches
Question 7: What is a Heap?
A heap is a specialized tree-based data structure that satisfies the heap property: in a max-heap, every parent node is greater than or equal to its children, and vice versa for a min-heap. Heaps are often used to implement priority queues, which are essential in many algorithmic problems.
In interviews, you might be asked to implement a heap from scratch or to explain how heaps can be used in algorithms like heap sort. The heap’s ability to quickly access the largest or smallest element makes it indispensable in many real-world applications.
Highlights:
- Max-Heap: Parent nodes have greater or equal values than children
- Min-Heap: Parent nodes have smaller or equal values than children
- Applications: Priority queues, heap sort, scheduling algorithms
Table of heap operations:
Operation | Average Complexity |
Insertion | O(log n) |
Deletion | O(log n) |
Peek | O(1) |
Question 8: Explain Sorting Algorithms
Sorting algorithms are a fundamental part of computer science, essential for organizing data efficiently. Common sorting techniques include Quick Sort, Merge Sort, Bubble Sort, and Insertion Sort, each with its own time and space complexities.
In interviews, candidates are expected to understand how these algorithms work, their use cases, and how to analyze their performance. Sorting is often a precursor to more advanced algorithms, and choosing the right algorithm for a specific dataset is key.
Core points:
- Quick Sort: Average O(n log n), but worst-case O(n²)
- Merge Sort: Always O(n log n) but requires extra space
- Bubble Sort: Simple but inefficient with O(n²) complexity
Bullet points for comparison:
- Efficiency: Merge Sort is more stable and predictable
- Simplicity: Bubble Sort is easier to implement for beginners
- In-place sorting: Quick Sort typically requires less extra memory
Question 9: What is Binary Search and How Does It Work?
Binary Search is an efficient algorithm for finding an item from a sorted list of elements. It works by repeatedly dividing the search interval in half, significantly reducing the number of comparisons required compared to linear search.
In an interview, you might be asked to write code for binary search and analyze its time complexity. This algorithm is a favorite due to its simplicity and efficiency, achieving O(log n) time complexity in the best-case scenarios.
Key elements:
- Sorted Data: Binary search requires data to be sorted
- Divide and Conquer: Recursively halves the search space
- Efficiency: Highly efficient for large datasets
Example pseudocode outline:
- Set low and high indices
- Calculate mid index
- Compare mid value with the target
- Adjust low or high accordingly until found
Question 10: Explain Recursion with Examples
Recursion is a technique where a function calls itself to solve smaller instances of the same problem. It is a powerful concept often used in algorithms such as tree traversals, sorting, and solving complex mathematical problems.
During interviews, candidates are expected to explain the base case, the recursive case, and potential pitfalls like stack overflow. Recursion can simplify code but may lead to performance issues if not managed properly.
Key ideas:
- Base Case: Prevents infinite recursion
- Recursive Case: Breaks the problem into smaller subproblems
- Use Cases: Factorial calculation, Fibonacci series, tree traversal
Bullet points summarizing recursion:
- Elegant solution for repetitive problems
- Can be less efficient than iterative solutions
- Requires careful handling to avoid infinite loops
Question 11: What is Dynamic Programming and How to Approach It?
Dynamic Programming (DP) is a method for solving complex problems by breaking them down into simpler subproblems, storing the results to avoid redundant computations. DP is highly effective for optimization problems where the solution can be recursively defined in terms of smaller subproblems.
In interviews, you may be given classic problems such as the Knapsack problem, Longest Common Subsequence, or Fibonacci numbers with memoization. The key is to identify overlapping subproblems and optimal substructure in the problem at hand.
Highlights:
- Memoization: Caching results for future reference
- Tabulation: Bottom-up approach using iterative loops
- Optimization: Helps reduce exponential time complexity to polynomial
Steps to approach DP problems:
- Identify the subproblems
- Define the state and recurrence relation
- Decide on memoization or tabulation
Question 12: What are Greedy Algorithms and When to Use Them?
Greedy algorithms work by making the locally optimal choice at each stage with the hope of finding the global optimum. They are straightforward and efficient but do not always guarantee the best solution for every problem.
In an interview scenario, you might be asked to compare greedy algorithms with dynamic programming, especially in problems like coin change, activity selection, or Kruskal’s algorithm for Minimum Spanning Trees (MST).
Key points:
- Local vs. Global Optimum: Greedy choice may not yield the best global outcome
- Efficiency: Generally faster and simpler than exhaustive methods
- Applications: Useful in problems where the greedy choice property holds true
Comparison bullet points:
- Greedy Algorithms: Fast and simple, but may fail in some cases
- Dynamic Programming: More complex, guarantees optimal solution for overlapping subproblems
- Example Use Case: Activity selection problem works perfectly with a greedy approach
Question 13: Explain Backtracking and Its Application
Backtracking is a refined brute-force approach that incrementally builds candidates to the solutions and abandons a candidate (“backtracks”) as soon as it determines that the candidate cannot possibly be completed to a valid solution. It is widely used in solving constraint satisfaction problems such as puzzles, pathfinding, and combinatorial optimization.
During interviews, you might be asked to implement backtracking for problems like the N-Queens problem, Sudoku solver, or generating all subsets of a set. Understanding when to use backtracking over other methods is crucial, as it helps in reducing the search space significantly.
Core components:
- Decision Tree: Explores possible solution paths
- Pruning: Eliminates paths that lead to invalid solutions
- Recursion: Often implemented using recursive function calls
Steps in backtracking:
- Choose a possible candidate
- Recursively explore further candidates
- Backtrack if a candidate fails to lead to a solution
Question 14: What is Time Complexity and How to Analyze It?
Time complexity is a measure of the amount of time an algorithm takes to run as a function of the length of the input. It is typically expressed using Big O notation, which helps in comparing the efficiency of different algorithms.
Interviewers expect candidates to explain the significance of time complexity, how to derive it for loops, recursive calls, and nested operations. By breaking down the algorithm step-by-step, you can articulate its performance in both average and worst-case scenarios.
Key elements:
- Big O Notation: Describes the upper bound
- Best, Average, Worst Cases: Different scenarios of execution time
- Importance: Crucial for selecting efficient algorithms in large-scale applications
Bullet points:
- Loop Analysis: Each loop iteration contributes to complexity
- Recursive Calls: Often involve multiplication of subproblem complexities
- Optimization: Aim for algorithms with lower time complexity
Question 15: What is Space Complexity and Why Is It Important?
Space complexity measures the total amount of memory that an algorithm or operation needs in relation to the size of the input data. Just like time complexity, understanding space complexity is crucial for designing efficient algorithms, especially when working with limited memory resources.
In interviews, candidates are expected to analyze how data structures, recursion, and iterative processes affect the overall memory consumption. Explaining space complexity also involves discussing auxiliary space and in-place algorithms.
Core points:
- Auxiliary Space: Extra space used by the algorithm
- In-place Algorithms: Algorithms that use a constant amount of extra space
- Significance: Impacts performance in memory-constrained environments
Bullet points summarizing space considerations:
- Memory Usage: Evaluate both input and extra storage
- Optimization: Seek to minimize auxiliary space where possible
- Trade-offs: Balance between time and space efficiency
Question 16: Explain Big O, Big Theta, and Big Omega Notations
Big O, Big Theta, and Big Omega notations are mathematical representations used to describe the efficiency of algorithms. Big O provides an upper bound, Big Theta gives a tight bound, and Big Omega offers a lower bound on the growth rate of an algorithm’s running time or space requirements.
During technical interviews, you may be asked to distinguish between these notations and provide examples. Demonstrating a clear understanding of these concepts can help you effectively analyze and compare different algorithms.
Key differences:
- Big O: Worst-case scenario
- Big Theta: Average-case scenario when bounds are tight
- Big Omega: Best-case scenario or lower bound
Bullet points:
- Big O: Focuses on the worst-case performance
- Big Theta: Represents a precise asymptotic behavior
- Big Omega: Ensures that performance does not fall below a certain threshold
Question 17: What is the Divide and Conquer Strategy?
Divide and Conquer is an algorithm design paradigm that divides a problem into smaller subproblems, solves each subproblem recursively, and then combines their solutions to solve the original problem. It is widely used in sorting algorithms such as Merge Sort and Quick Sort, as well as in solving complex mathematical problems.
In interviews, candidates are often expected to break down the strategy and provide examples of how it improves efficiency by reducing the overall problem size. The technique highlights the power of recursion and efficient merging of subproblem results.
Steps involved:
- Divide: Split the problem into smaller parts
- Conquer: Solve the subproblems recursively
- Combine: Merge the solutions to form the final answer
Bullet points for the strategy:
- Reduces time complexity by simplifying large problems
- Highly effective in recursive algorithm design
- Commonly used in sorting, searching, and optimization problems
Question 18: Explain Binary Search Tree and Its Operations
A Binary Search Tree (BST) is a special form of a tree where each node has at most two children, and for any node, the left subtree contains nodes with values less than the node’s value while the right subtree contains nodes with greater values. This structure facilitates efficient searching, insertion, and deletion operations.
BSTs are a favorite topic in interviews because they combine the properties of trees with efficient search algorithms. Candidates are expected to explain operations such as insertion, deletion, and traversal (inorder, preorder, and postorder) along with the time complexities involved.
Key features:
- Sorted Order: Inorder traversal of a BST yields sorted output
- Dynamic Data: Efficient handling of dynamic data sets
- Complexity: Average-case O(log n) for search, but can degrade to O(n) in skewed trees
Bullet points:
- Insertion: Recursively find the correct position
- Deletion: Handle three cases: leaf node, one child, two children
- Traversal: Inorder, preorder, and postorder methods for various uses
Question 19: How Do Depth First Search (DFS) and Breadth First Search (BFS) Work in Graphs?
Depth First Search (DFS) and Breadth First Search (BFS) are two fundamental graph traversal algorithms. DFS explores as far as possible along each branch before backtracking, while BFS visits nodes level by level, making it ideal for finding the shortest path in unweighted graphs.
During interviews, you might be asked to implement these algorithms, compare their time and space complexities, and discuss their applications in real-world scenarios such as social networks or maze solving.
Highlights:
- DFS: Uses recursion or a stack, ideal for pathfinding where all possibilities need exploration
- BFS: Uses a queue, optimal for shortest path problems in graphs
- Complexity: Both typically operate in O(V+E), where V is vertices and E is edges
Bullet points summarizing differences:
- DFS: Deep exploration, can be implemented recursively
- BFS: Level order exploration, uses more memory for queues
- Applications: DFS for topological sorting, BFS for shortest paths
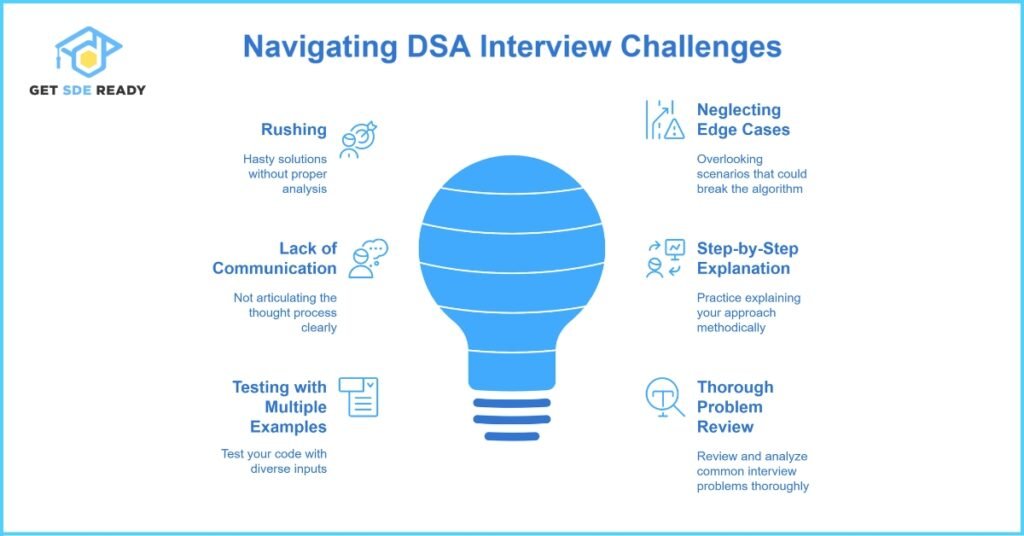
Question 20: What Are the Common Pitfalls and Mistakes During DSA Interviews?
Many candidates make similar mistakes during DSA interviews, ranging from misinterpreting the problem to overlooking edge cases in their solutions. Common pitfalls include not explaining the thought process clearly, failing to analyze time and space complexities, and not testing code with diverse input cases.
To excel in interviews, it is important to not only arrive at a correct solution but also to communicate your approach effectively. Interviewers value a candidate’s ability to identify potential issues, handle error conditions, and optimize their solutions.
Key pitfalls:
- Rushing: Hasty solutions without proper analysis
- Neglecting Edge Cases: Overlooking scenarios that could break the algorithm
- Lack of Communication: Not articulating the thought process clearly
Bullet points for improvement:
- Practice explaining your approach step-by-step
- Test your code with multiple examples
- Review and analyze common interview problems thoroughly
FAQs
What are the best practices for preparing DSA interviews?
Preparing for DSA interviews requires a balanced approach between theory and practice. It is essential to understand the underlying concepts of data structures and algorithms, practice coding problems regularly, and learn to articulate your thought process during interviews. Many experts recommend using online coding platforms and mock interviews to refine your skills. For more comprehensive preparation tips, check out our DSA course.
How important is it to master both time and space complexity analysis?
Mastering both time and space complexity analysis is crucial for designing efficient algorithms and solving problems under interview conditions. Understanding these concepts helps you optimize your code and choose the most effective solution for a given problem, which can be a significant differentiator during an interview. Interviewers often focus on whether candidates can not only write working code but also explain its efficiency in terms of computational resources. To dive deeper into these concepts, consider enrolling in our Web Development course.
Can practicing mock interviews really improve my performance in DSA interviews?
Yes, practicing mock interviews is an excellent way to improve your performance in DSA interviews. It helps simulate real interview conditions, builds your confidence, and allows you to receive constructive feedback on your problem-solving approach. Regular practice also trains you to manage time effectively and think on your feet, ensuring you can handle even the most challenging questions during the actual interview. For a structured approach to improving your interview skills, check out our Design DSA Combined course.

DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 60% OFF
₹25,000.00 ₹9,999.00
Accelerate your Path to a Product based Career
Boost your career or get hired at top product-based companies by joining our expertly crafted courses. Gain practical skills and real-world knowledge to help you succeed.

Essentials of Machine Learning and Artificial Intelligence
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 22+ Hands-on Live Projects & Deployments
- Comprehensive Notes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
- Interview Prep Material
Buy for 65% OFF
₹20,000.00 ₹6,999.00

Fast-Track to Full Spectrum Software Engineering
- 120+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- 12+ live Projects & Deployments
- Case Studies
- Access to Global Peer Community
Buy for 57% OFF
₹35,000.00 ₹14,999.00
DSA, High & Low Level System Designs
- 85+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests & Quizzes
- Topic-wise Quizzes
- Case Studies
- Access to Global Peer Community
Buy for 60% OFF
₹25,000.00 ₹9,999.00

Low & High Level System Design
- 20+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 400+ DSA Practice Questions
- Comprehensive Notes
- HackerRank Tests
- Topic-wise Quizzes
- Access to Global Peer Community
- Interview Prep Material
Buy for 65% OFF
₹20,000.00 ₹6,999.00

Mastering Mern Stack (WEB DEVELOPMENT)
- 65+ Live Classes & Recordings
- 24*7 Live Doubt Support
- 12+ Hands-on Live Projects & Deployments
- Comprehensive Notes & Quizzes
- Real-world Tools & Technologies
- Access to Global Peer Community
- Interview Prep Material
- Placement Assistance
Buy for 60% OFF
₹15,000.00 ₹5,999.00
Reach Out Now
If you have any queries, please fill out this form. We will surely reach out to you.
Contact Email
Reach us at the following email address.
Phone Number
You can reach us by phone as well.
+91-97737 28034
Our Location
Rohini, Sector-3, Delhi-110085
